

Snowpark:雪だるまを使用したdatabase機械学習
従来の機械学習には、データベースから大規模なデータセットをモデルトレーニング環境に移動することがよくあります。 これは、今日の大規模なデータセットではますます非効率的になっています。 Snowflake Snowparkは、Databaseで処理を可能にすることでこれに対処します。 SnowParkは、Snowflakeのクラウド内で直接コード(Python、Java、Scala)を実行するライブラリとランタイムを提供し、データの動きを最小限に抑え、セキュリティを強化します。
なぜスノーパークを選ぶのか?Snowparkにはいくつかの重要な利点があります:
コンドラ環境を作成し、必要なライブラリをインストールします(
、、、、snowflake-snowpark-python)。pandas)。
pyarrow
numpy
matplotlibseabornデータの摂取:ipykernelサンプルデータ(シーボーンダイヤモンドデータセットなど)をスノーフレークテーブルにインポートします。 (注:実際のシナリオでは、通常、既存のスノーフレークデータベースを使用して作業します。)
SnowParkセッションの作成:資格情報(アカウント名、ユーザー名、パスワード)を使用してSnowflakeへの接続を確立します。
データの読み込み:SnowParkセッションを使用して、データにアクセスしてSnowParkデータフレームにロードします。
config.py
.gitignoreSnowParkデータフレームの理解
ローカルマシンにデータを転送することは非現実的である大規模なデータセットにSnowParkデータフレームを使用します。 小さなデータセットの場合、パンダで十分です。 この方法により、SnowParkとPandasのデータフレーム間の変換が可能になります。 メソッドは、SQLクエリを直接実行するための代替手段を提供します。
SnowParkデータフレーム変換関数:F、snowflake.snowpark.functions、および.select()メソッドで使用されます。
.filter()探索的データ分析(EDA):.with_column()
データのクリーニング:
データ型が正しいことを確認し、前処理のニーズ(例えば、列の名前変更、データ型のキャスト、テキスト機能のクリーニングなど)を処理します。プリプロセシング:スノーフレークMLの
。を使用してパイプラインを保存します
Pipeline
OrdinalEncoderStandardScalerモデルトレーニング:joblibプリプロセッスされたデータを使用してxgboostモデル(
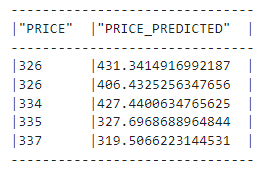
モデルの評価:XGBRegressorrmse(random_split()from
ハイパーパラメーターチューニング:mean_squared_errorを使用して、モデルハイパーパラメーターを最適化します。snowflake.ml.modeling.metrics
モデルの保存:トレーニングされたモデルとそのメタデータをSnowflakeのモデルレジストリに保存します。
RandomizedSearchCV
結論:Registry












注:画像URLは入力から保存されます。 フォーマットは、読みやすさと流れを改善するために調整されます。 技術的な詳細は保持されますが、言語はより簡潔になり、より多くの視聴者がアクセスしやすくなります。
以上がスノーフレークスノーパーク:包括的な紹介の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



