

kimi K1.5:風景を再形成する生成AI推論モデル
補強学習(RL)および大規模な言語モデル(LLM)の最近のブレークスルーは、生成AI推論に革命をもたらす態勢の整ったモデルであるKimi K1.5の作成で頂点に達しました。 この記事では、Kimi K1.5の主要な特徴、革新、潜在的な影響を掘り下げて、付随する研究から洞察を引き出します。
目次:
kimi k1.5?とは何ですか
kimi K1.5は、LLMを使用してRLをスケーリングする際にかなりの跳躍を表しています。モンテカルロツリー検索などの複雑な方法に依存する従来のモデルとは異なり、自己回帰予測とRL技術を中心とした合理化されたアプローチを採用しています。 その設計により、マルチモーダルタスクを処理し、Math VistaやLive Code Benchなどのベンチマークで例外的なパフォーマンスを紹介できます。 kimi k1.5トレーニングKimi K1.5のトレーニングは、RLとマルチモーダル統合を通じて推論を強化するために設計されたマルチステージプロセスです。
監視された微調整(SFT):
補強学習(RL):慎重にキュレーションされたプロンプトセットがRLトレーニングを駆動します。 このモデルは、応答の精度を評価する報酬モデルによって導かれた一連の推論ステップを介してソリューションを生成することを学びます。 オンラインミラーの降下はポリシーを最適化します
部分的なロールアウト:長いコンテキストを効率的に処理するために、Kimi K1.5は部分的なロールアウトを使用し、後の継続のために未完成の部分を保存します。
長さのペナルティは簡潔な回答を促進しますが、カリキュラムと優先順位付けされたサンプリング戦略では、最初に簡単なタスクにトレーニングを集中します。
kimi k1.5システムの概要と部分的なロールアウト図:
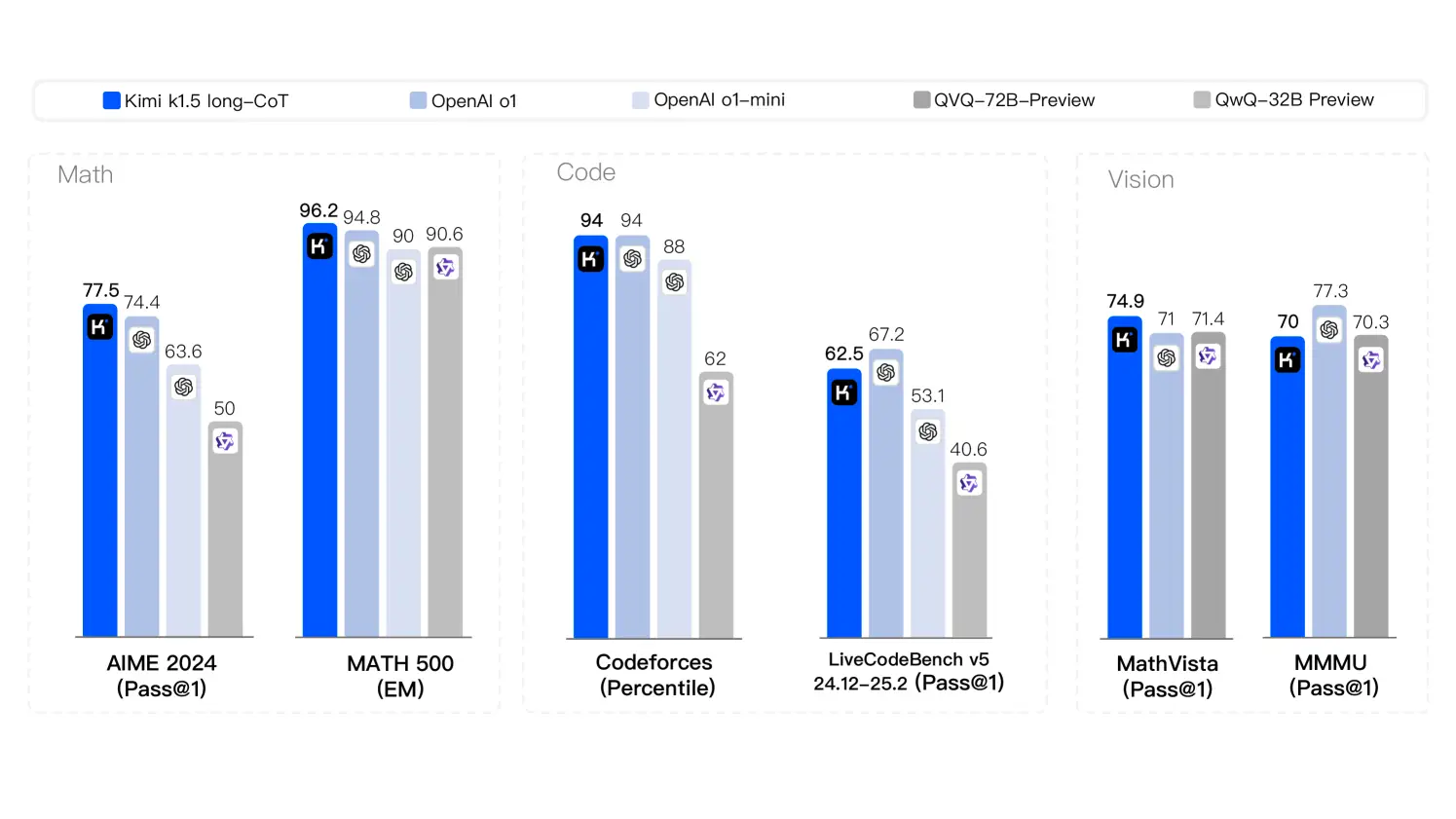
kimi K1.5は、多様なタスク全体で最先端のパフォーマンスを示しています:
長いコンテキストのスケーリング:最大128,000トークンのプロセス、部分的なロールアウトによる効率を向上させます。 経由でkimi k1.5にアクセスします
APIアクセスには、Kimiの管理コンソールへの登録が必要です。 Pythonコードスニペットの例は、API相互作用を示しています:
Kimi K1.5は、生成AI推論の重要な進歩を表し、最先端の結果を達成しながらRL設計を簡素化します。 コンテキストでのその革新スケーリングとマルチモーダルデータ処理は、さまざまな業界で幅広い意味を持つ主要なモデルとして位置付けています。
以上がDeepseekの後、Kimi K1.5はOpenai O1を照らしますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



