

Solar-10.7B:非常に効率的な大型言語モデルに深く潜ります
ソーラー10.7Bプロジェクトは、大規模な言語モデル(LLM)開発における大幅な進歩を示しています。 この記事では、その革新的なスケーリングアプローチ、パフォーマンスベンチマーク、実用的な使用、および潜在的なアプリケーションを調査しながら、その制限も認めています。
Solar-10.7b深度アップスケーリング:新しいスケーリング手法
DUSは、計算リソースを比例して増加させることなく、モデルの深さを増やすことができます。これにより、効率とパフォーマンスの両方が向上します。 この方法は、Mistral 7Bウェイト、Llama 2フレームワーク、および連続前トレーニングの3つの重要なコンポーネントに依存しています。
N = 32、S = 48、およびM = 8の深さアップスケーリングのイラスト2段階のプロセスは、深さごとのスケーリングと継続的なトレーニングを組み合わせています。 (ソース)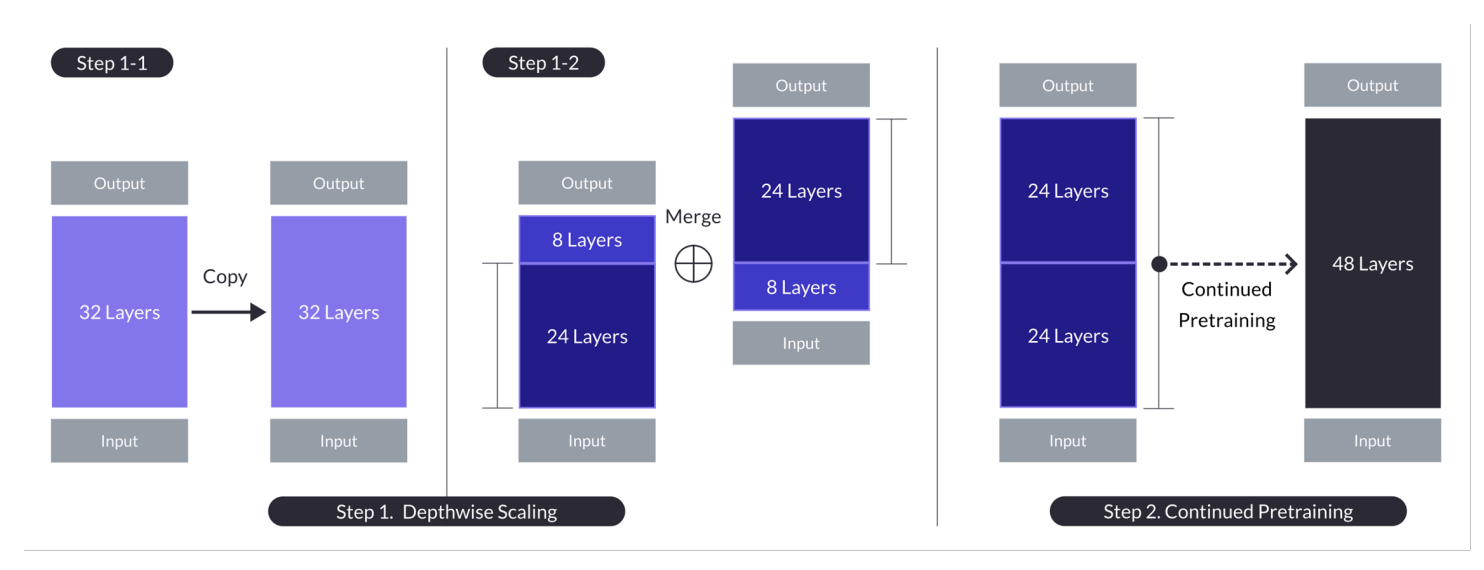
ベースモデル:
A 32層Llama 2モデルMistral 7bウェイトで初期化。
2。インポートライブラリ:
pip -q install transformers==4.35.2 pip -q install accelerate
3。 GPU構成:
GPUが有効になっていることを確認します(たとえば、Google Colabのランタイム設定を使用)。import torch from transformers import AutoModelForCausalLM, AutoTokenizer
で確認します
4。モデルの定義:!nvidia-smi
5。モデルの推論と結果生成:
model_ID = "Upstage/SOLAR-10.7B-Instruct-v1.0" tokenizer = AutoTokenizer.from_pretrained(model_ID) model = AutoModelForCausalLM.from_pretrained(model_ID, device_map="auto", torch_dtype=torch.float16)
制限
強力ですが、ソーラー10.7bには制限があります:user_request = "What is the square root of 24?"
conversation = [{'role': 'user', 'content': user_request}]
prompt = tokenizer.apply_chat_template(conversation, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, use_cache=True, max_length=4096)
output_text = tokenizer.decode(outputs[0])
print(output_text)ハイパーパラメーターの最適化:
DUSには、より広範なハイパーパラメーター探査が必要です。以上がSolar-10.7B微調整されたモデルチュートリアルの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



