

Modernbertの可能性のあるRAGのロックを解除します

ModernBert:強力で効率的なNLPモデル
Modernbertは、元のBertアーキテクチャを大幅に改善し、さまざまな自然言語処理(NLP)タスクのパフォーマンスと効率を向上させます。 この高度なモデルには、最先端のアーキテクチャの改善と革新的なトレーニング方法が組み込まれており、機械学習分野の開発者の能力を拡大します。 拡張されたコンテキスト長8,192トークン(従来のモデルよりも大幅に増加)は、長期の検索やコード理解などの複雑な課題に顕著な精度を持って取り組むことになります。 この効率は、メモリの使用量の減少と相まって、洗練された検索エンジンからAI駆動のコーディング環境まで、NLPアプリケーションを最適化するのに最新のものを理想的にします。
重要な機能と進歩Modernbertの優れたパフォーマンスは、いくつかの重要な革新に由来しています:
- 回転式位置エンコーディング(ロープ):従来の位置埋め込みを置き換え、単語の関係をよりよく理解し、より長いシーケンス(最大8,192トークン)にスケーリングします。 これは、より長いシーケンスに苦労する絶対的な位置エンコードの制限に対処します。
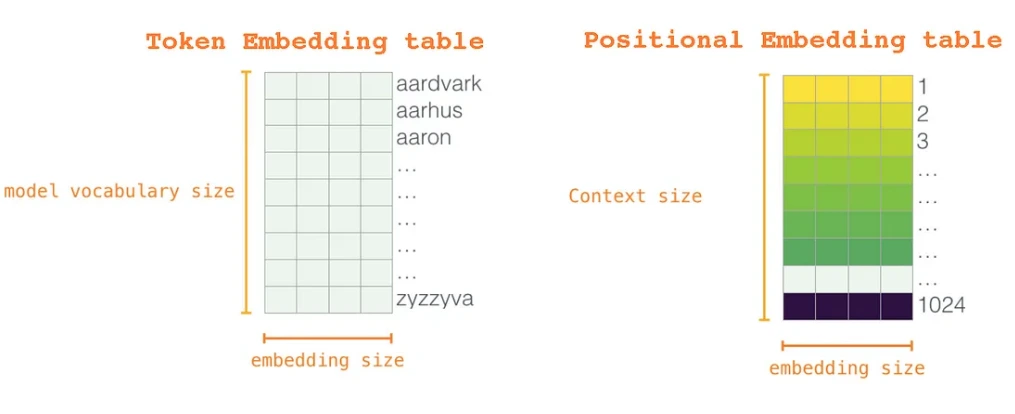
- Gegluアクティベーション関数:
- Glu(ゲート線形ユニット)とGelu(Gaussian error Linearユニット)のアクティベーションを組み合わせて、情報フロー制御とネットワーク内の非線形性を強化するためのアクティベーション。
- 注意メカニズムの交互のメカニズム:グローバルとローカルの注意のブレンドを採用し、効率とパフォーマンスのバランスを取ります。 この最適化されたアプローチは、計算の複雑さを減らすことにより、長い入力の処理を高速化します。
- フラッシュ注意2統合:メモリの使用量を最小限に抑え、加速処理を加速することにより、計算効率をさらに強化します。特に長いシーケンスに有益です。 大規模なトレーニングデータ:
- コードや科学文献を含む2兆個のトークンの大規模なデータセットでトレーニングを受け、コード関連のタスクで優れたパフォーマンスを可能にします。 Modernbert vs. Bert:比較
実用的なアプリケーション
ModernBertの機能は、さまざまなアプリケーションに拡張されています
- ロングドキュメントの検索:法的テキストや科学論文などの広範な文書を分析するのに最適です。
- ハイブリッドセマンティック検索:テキストとコードの両方のクエリを理解することにより、検索エンジンを強化します。 コンテキストコード分析:
- バグ検出やコード最適化などのタスクを促進します。 コード検索: AIを搭載したIDEおよびコードインデックスソリューションに最適です。
- 検索拡張生成(RAG)システム:より正確で関連性のある応答を生成するための強化されたコンテキストを提供します。
- Python実装(Rag Systemの例) Modernbert EmbeddingsとWeaviateを使用した単純化されたRAGシステムを以下に示します。 (注:このセクションでは、いくつかのライブラリと承認トークンを備えたハグのフェイスアカウントをインストールする必要があります。コードは、適切なデータセットとOpenai APIキーへのアクセスも想定しています。)完全なコードは、ここで省略されていますが、rag pipeline内に埋め込み生成と検索のためのModernbertの統合を示しています。 結論
ModernBertは、NLPで実質的な進歩を提示し、パフォーマンスの向上と効率の向上を組み合わせています。長いシーケンスとその多様なトレーニングデータを処理する能力により、多数のアプリケーションに汎用性の高いツールになります。 ロープやGegluなどの革新的な技術の統合は、ModernBertを複雑なNLPとコード関連のタスクに取り組むための主要なモデルとして位置付けています。
(注:画像URLは変更されていません。)
以上がModernbertの可能性のあるRAGのロックを解除しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7771
7771
 15
1644
14
1399
52
1296
25
1234
29
15
1644
14
1399
52
1296
25
1234
29

 クリエイティブプロジェクトのための最高のAIアートジェネレーター(無料&有料)
Apr 02, 2025 pm 06:10 PM
クリエイティブプロジェクトのための最高のAIアートジェネレーター(無料&有料)
Apr 02, 2025 pm 06:10 PM
この記事では、トップAIアートジェネレーターをレビューし、その機能、創造的なプロジェクトへの適合性、価値について説明します。 Midjourneyを専門家にとって最高の価値として強調し、高品質でカスタマイズ可能なアートにDall-E 2を推奨しています。
 Meta Llama 3.2を始めましょう - 分析Vidhya
Apr 11, 2025 pm 12:04 PM
Meta Llama 3.2を始めましょう - 分析Vidhya
Apr 11, 2025 pm 12:04 PM
メタのラマ3.2:マルチモーダルとモバイルAIの前進 メタは最近、ラマ3.2を発表しました。これは、モバイルデバイス向けに最適化された強力なビジョン機能と軽量テキストモデルを特徴とするAIの大幅な進歩です。 成功に基づいてo
 ベストAIチャットボットが比較されました(chatgpt、gemini、claude& more)
Apr 02, 2025 pm 06:09 PM
ベストAIチャットボットが比較されました(chatgpt、gemini、claude& more)
Apr 02, 2025 pm 06:09 PM
この記事では、ChatGpt、Gemini、ClaudeなどのトップAIチャットボットを比較し、自然言語の処理と信頼性における独自の機能、カスタマイズオプション、パフォーマンスに焦点を当てています。
 ChatGpt 4 oは利用できますか?
Mar 28, 2025 pm 05:29 PM
ChatGpt 4 oは利用できますか?
Mar 28, 2025 pm 05:29 PM
CHATGPT 4は現在利用可能で広く使用されており、CHATGPT 3.5のような前任者と比較して、コンテキストを理解し、一貫した応答を生成することに大幅な改善を示しています。将来の開発には、よりパーソナライズされたインターが含まれる場合があります
 トップAIライティングアシスタントは、コンテンツの作成を後押しします
Apr 02, 2025 pm 06:11 PM
トップAIライティングアシスタントは、コンテンツの作成を後押しします
Apr 02, 2025 pm 06:11 PM
この記事では、Grammarly、Jasper、Copy.ai、Writesonic、RytrなどのトップAIライティングアシスタントについて説明し、コンテンツ作成のためのユニークな機能に焦点を当てています。 JasperがSEOの最適化に優れているのに対し、AIツールはトーンの維持に役立つと主張します
 AIエージェントを構築するためのトップ7エージェントRAGシステム
Mar 31, 2025 pm 04:25 PM
AIエージェントを構築するためのトップ7エージェントRAGシステム
Mar 31, 2025 pm 04:25 PM
2024年は、コンテンツ生成にLLMSを使用することから、内部の仕組みを理解することへの移行を目撃しました。 この調査は、AIエージェントの発見につながりました。これは、最小限の人間の介入でタスクと決定を処理する自律システムを処理しました。 buildin
 従業員へのAI戦略の販売:Shopify CEOのマニフェスト
Apr 10, 2025 am 11:19 AM
従業員へのAI戦略の販売:Shopify CEOのマニフェスト
Apr 10, 2025 am 11:19 AM
Shopify CEOのTobiLütkeの最近のメモは、AIの能力がすべての従業員にとって基本的な期待であると大胆に宣言し、会社内の重大な文化的変化を示しています。 これはつかの間の傾向ではありません。これは、pに統合された新しい運用パラダイムです
 最高のAI音声ジェネレーターの選択:レビューされたトップオプション
Apr 02, 2025 pm 06:12 PM
最高のAI音声ジェネレーターの選択:レビューされたトップオプション
Apr 02, 2025 pm 06:12 PM
この記事では、Google Cloud、Amazon Polly、Microsoft Azure、IBM Watson、DecriptなどのトップAI音声ジェネレーターをレビューし、機能、音声品質、さまざまなニーズへの適合性に焦点を当てています。
