

このデータサンプコミュニティのチュートリアルは、明確さと精度のために編集されており、革新的な対照的なキャプション(COCA)モデルに焦点を当てた画像テキストファンデーションモデルを探ります。 Cocaは、ContrastiveとGenerativeの学習目標をユニークに組み合わせて、ClipやSimVLMなどのモデルの強さを単一のアーキテクチャに統合します。

基礎モデル:深いダイビング重要な用語:
ファンデーションモデル:多様なアプリケーションに適応可能な事前に訓練されたモデル。
画像 - テキストデュアルエンコーダーモデル(クリップ、アライメント):
関連する画像テキストのペアをクラスター化し、共有ベクトル空間で無関係なペアを分離することを学びます。 単一のプールされた画像埋め込みが使用されます 生成目標:
テキストを自己回避的に予測するために、微調整された画像表現(256次元シーケンス)とクロスモーダルの注意を使用します。

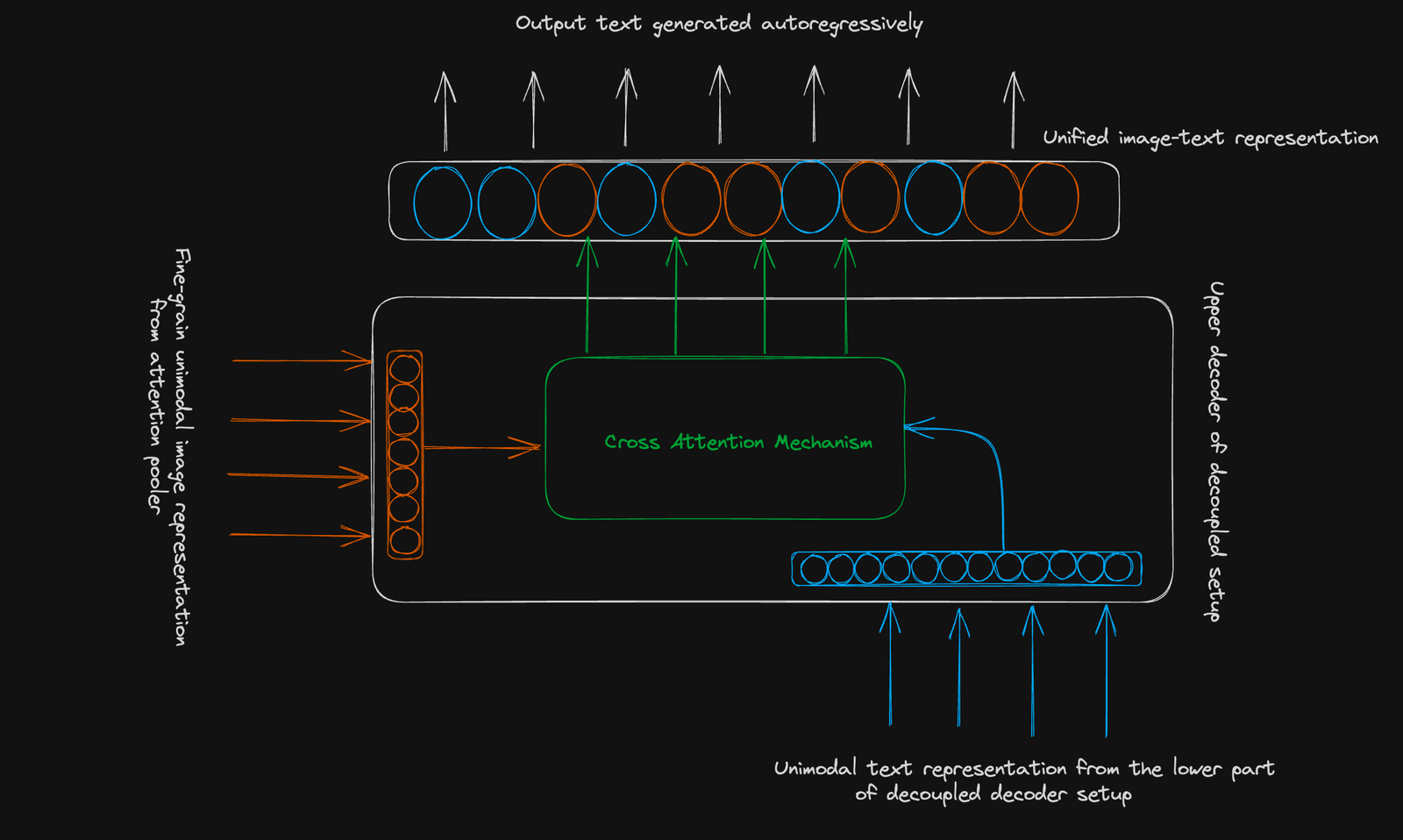 結論:
結論:
cocaは、画像テキストファンデーションモデルの大幅な進歩を表しています。その組み合わせたアプローチは、さまざまなタスクでのパフォーマンスを向上させ、ダウンストリームアプリケーションに汎用性の高いツールを提供します。 高度な深い学習の概念を理解するために、Kerasコースを使用したDatacampの高度な深い学習を検討してください。
さらなる読み取り:自然言語の監督からの移転可能な視覚モデルの学習
対照的なキャプションを使用した画像テキスト事前トレーニング以上がCOCA:対照型のキャプションは、視覚的に説明されている画像テキストファンデーションモデルですの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



