

ベクトル埋め込みは、セマンティック検索や異常検出など、多くの高度なAIアプリケーションの基本です。この記事では、文の埋め込みとベクトル表現に焦点を当てた埋め込みの基礎的な理解を提供します。平均プーリングやコサインの類似性などの実用的な手法を調査し、BERTを使用してデュアルエンコーダーのアーキテクチャを掘り下げ、詐欺検出やコンテンツモデレーションなどのタスクの頂点AIを使用した異常検出のアプリケーションを調べます。
*この記事は、***データサイエンスブログソンの一部です。
目次
頂点埋め込みの理解
ベクトル埋め込みは、定義された空間内の単語または文を表します。これらのベクトルの近接性は類似性を意味します。より近いベクトルは、セマンティックな類似性の大きさを示します。最初は主にNLPで使用されていましたが、そのアプリケーションは画像、ビデオ、オーディオ、グラフに拡張されています。顕著なマルチモーダル学習モデルであるClipは、画像とテキストの埋め込みの両方を生成します。
ベクトル埋め込みの主要なアプリケーションには次のものがあります。
ぼろきれパイプラインにおける文の埋め込みの重要性を調べましょう。
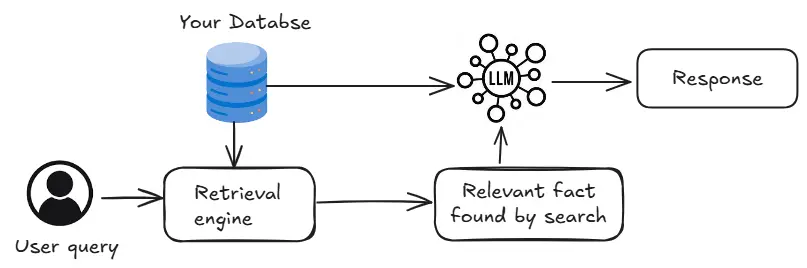
上記の図の検索エンジンは、ユーザークエリに関連するデータベース情報を識別します。トランスベースのクロスエンコーダーは、クエリをすべての情報と比較して、関連性を分類できます。ただし、これは遅いです。ベクトルデータベースは、埋め込みを保存し、類似性検索を使用することにより、より高速な代替手段を提供しますが、精度はわずかに低くなる場合があります。
文の埋め込みを理解する
文の埋め込みは、数学的操作をトークン埋め込みに適用することによって作成されます。これは、多くの場合、BertやGPTなどの事前に訓練されたモデルによって生成されます。次のコードは、文を生成したトークン埋め込みの平均プーリングを示しています。
model_name = "./models/bert-base-uncased"
tokenizer = berttokenizer.from_pretrained(model_name)
Model = bertmodel.from_pretrained(model_name)
def get_sentence_embedding(cente):
encoded_input = tokenizer(cente、padding = true、truncation = true、return_tensors = 'pt')
attention_mask = encoded_input ['attention_mask']
torch.no_grad()を使用して:
output = model(** encoded_input)
token_embeddings = output.last_hidden_state
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size())。float()
cente_embeding = torch.sum(token_embeddings * input_mask_expanded、1) / torch.clamp(input_mask_expanded.sum(1)、min = 1e-9)
return tente_embeding.flatten()。tolist()このコードはBERTモデルをロードし、平均プーリングを使用して文埋め込みを計算する関数を定義します。
文の埋め込みのコサインの類似性
コサインの類似性は、2つのベクトル間の類似性を測定し、文の埋め込みを比較するのに適しています。次のコードは、コサインの類似性と視覚化を実装します。
defosine_similarity_matrix(feature):
norms = np.linalg.norm(feature、axis = 1、keepdims = true)
remarized_features = feature / norms
類似性_matrix = np.inner(remarized_features、remormized_features)
rounded_similarity_matrix = np.round(signility_matrix、4)
Runited_similarity_matrixを返します
def plot_similarity(ラベル、機能、回転):
sim = cosine_similarity_matrix(feature)
sns.set_theme(font_scale = 1.2)
g = sns.heatmap(sim、xticklabels = labels、yticklabels = labels、vmin = 0、vmax = 1、cmap = "ylorrd")
g.set_xticklabels(ラベル、回転=回転)
g.set_title( "セマンティックテキストの類似性")
g
メッセージ= [
# テクノロジー
「私は仕事にMacBookを使用することを好みます。」、
「AIは人間の仕事を引き継いでいますか?」
「私のラップトップのバッテリーは速すぎて排出します。」
#スポーツ
「昨夜ワールドカップ決勝を見ましたか?」
「レブロン・ジェームズは信じられないほどのバスケットボール選手です。」
「週末にマラソンを走るのは楽しかった」、
# 旅行
「パリは訪れるべき美しい街です。」、
「夏に旅行するのに最適な場所は何ですか?」
「私はスイスアルプスでのハイキングが大好きです。」
# エンターテインメント
「最新のマーベル映画は素晴らしかった!」
「テイラー・スウィフトの歌を聴いていますか?」
「私は私のお気に入りのシリーズのシーズン全体を視聴しました。」
]
埋め込み= []
メッセージのtの場合:
emb = get_sentence_embedding(t)
Embeddings.Append(emb)
plot_similarity(メッセージ、埋め込み、90)このコードは、文を定義し、埋め込みを生成し、コサインの類似性を示すヒートマップをプロットします。結果は、予想外に高い類似性を示す可能性があり、デュアルエンコーダーのようなより正確な方法の探求を動機付けています。
(残りのセクションは同様の方法で続き、コア情報を維持し、画像の場所と形式を保持しながら、元のテキストを言い換えて再構築します。)
以上が頂点AIを使用した埋め込みモデルの探索の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



