

専門家(MOE)モデルの混合は、効率とスケーラビリティを改善することにより、大規模な言語モデル(LLM)に革命をもたらしています。この革新的なアーキテクチャは、モデルを専門のサブネットワーク、または「専門家」に分割し、それぞれ特定のデータ型またはタスクのために訓練されています。入力に基づいて専門家の関連するサブセットのみをアクティブにすることにより、MOEモデルは計算コストを比例的に増加させることなく容量を大幅に高めます。この選択的アクティベーションは、リソースの使用を最適化し、自然言語処理、コンピュータービジョン、推奨システムなどの多様な分野で複雑なタスクを処理できるようにします。この記事では、MOEモデル、その機能、一般的な例、およびPythonの実装について説明します。
この記事は、Data Science Blogathonの一部です。
目次:
専門家(MOE)の混合は何ですか?
MOEモデルは、単一の大きなモデルではなく、複数の小さく、特殊なモデルを採用することにより、機械学習を強化します。それぞれの小さいモデルは、特定の問題タイプで優れています。 「意思決定者」(ゲーティングメカニズム)は、各タスクに適したモデルを選択し、全体的なパフォーマンスを向上させます。トランスを含む最新のディープラーニングモデルは、データを処理し、結果を後続の層に渡す層状相互接続ユニット(「ニューロン」)を使用します。 MOEは、複雑な問題を特殊なコンポーネント(「専門家」)に分割することでこれを反映しており、それぞれが特定の側面に取り組んでいます。
MOEモデルの重要な利点:
MOEモデルは、2つの主要な部分で構成されています。専門家(専門の小規模なニューラルネットワーク)とルーター(入力に基づいて関連する専門家をアクティブにする)です。この選択的活性化は効率を高めます。
深い学習のoes
深い学習では、MOEは複雑な問題を分解することにより、ニューラルネットワークのパフォーマンスを向上させます。単一の大規模なモデルの代わりに、さまざまな入力データの側面に特化した複数の小さな「エキスパート」モデルを使用します。ゲーティングネットワークは、各入力に使用する専門家を決定し、効率と有効性を向上させます。
MOEモデルはどのように機能しますか?
MOEモデルは次のように動作します:
顕著なMOEベースのモデル
Performanceを維持しながらLLMSの効率的なスケーリングにより、AIではMOEモデルがますます重要になっています。注目すべき例であるMixtral 8x7Bは、まばらなMoEアーキテクチャを使用し、各入力に対して専門家のサブセットのみをアクティブにし、有意な効率向上をもたらします。
Mixtral 8x7Bはデコーダーのみの変圧器です。入力トークンはベクターに埋め込まれ、デコーダーレイヤーを介して処理されます。出力は、各場所が単語で占有される可能性であり、テキストの充填と予測を可能にします。各デコーダーレイヤーには、注意メカニズム(コンテキスト情報用)とエキスパート(SMOE)セクションのまばらな混合物(各単語ベクトルを個別に処理)があります。 SMOEレイヤーは複数のレイヤー(「専門家」)を使用し、各入力について、最も関連性の高い専門家の出力の加重合計が取得されます。
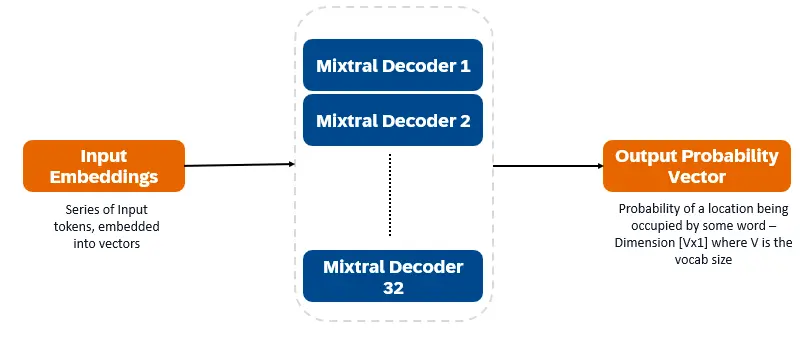
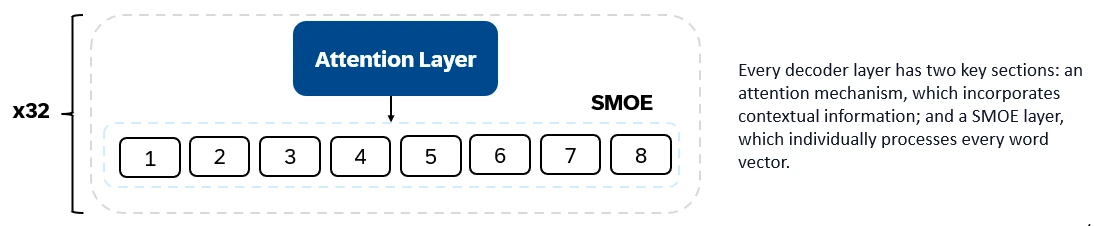
Mixtral 8x7bの主要な機能:
Mixtral 8x7bは、テキスト生成、理解、翻訳、要約などに優れています。
DBRX(DataBricks)は、次のトークン予測を使用してトレーニングされたトランスベースのデコーダーのみのLLMです。きめの細かいMOEアーキテクチャ(132B合計パラメーター、36Bアクティブ)を使用しています。テキストおよびコードデータの12tトークンで事前に訓練されていました。 DBRXは、多くの小規模な専門家(16人の専門家、入力ごとに選択された4人)を使用して、きめ細かく粒度を獲得しています。
DBRXの重要なアーキテクチャの特徴:
DBRXの重要な機能:
DBRXは、コード生成、複雑な言語理解、数学的推論に優れています。
DeepSeek-V2は、きめの細かい専門家と共有専門家(常にアクティブ)を使用して、普遍的な知識を統合します。
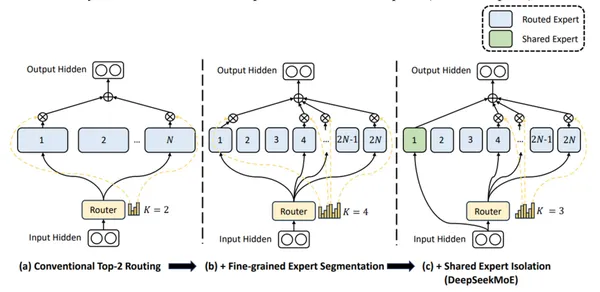
DeepSeek-V2の主要な機能:
DeepSeek-V2は、会話、コンテンツの作成、コード生成に熟達しています。
(Pythonの実装と出力の比較セクションは、長いコードの例と詳細な分析であるため、簡潔に削除されました。)
よくある質問
Q1。専門家(MOE)モデルの混合は何ですか? A. MOEモデルは、まばらなアーキテクチャを使用し、各タスクで最も関連性の高い専門家のみをアクティブにし、計算リソースの使用量を減らします。
Q2。 MOEモデルとのトレードオフは何ですか? A. MOEモデルでは、すべての専門家をメモリに保存するために重要なVRAMが必要であり、計算能力とメモリの要件のバランスを取ります。
Q3。 MixTral 8x7Bのアクティブパラメーターカウントは何ですか? A. MixTral 8x7Bには、128億のアクティブパラメーターがあります。
Q4。 DBRXは他のMOEモデルとどのように違いますか? A. DBRXは、より小規模の専門家とのきめの細かいMOEアプローチを使用しています。
Q5。 deepseek-v2を区別するものは何ですか? A. deepseek-v2は、大規模なパラメーターセットと長いコンテキストの長さとともに、細粒と共有の専門家を組み合わせています。
結論
MOEモデルは、深い学習に対する非常に効率的なアプローチを提供します。重要なVRAMを必要としますが、専門家の選択的アクティブ化により、さまざまなドメインで複雑なタスクを処理するための強力なツールになります。 Mixtral 8x7B、DBRX、およびDeepSeek-V2は、それぞれが独自の強みとアプリケーションを備えた重要な進歩を表しています。
以上が専門家の混合とは何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



