

この画期的な調査「大規模な言語モデルのデータセット:包括的な調査」は、2024年2月にリリースされ、大規模な言語モデル(LLM)開発のための400を超える綿密に分類されたデータセットの宝庫を発表します。 Yang Liu、Jiahuan Cao、Chongyu Liu、Kai Ding、およびLianwen Jinが編集したこのリソースは、研究者と開発者のための金鉱です。それは単なる静的コレクションではありません。定期的に更新されており、継続的な関連性を確保しています。
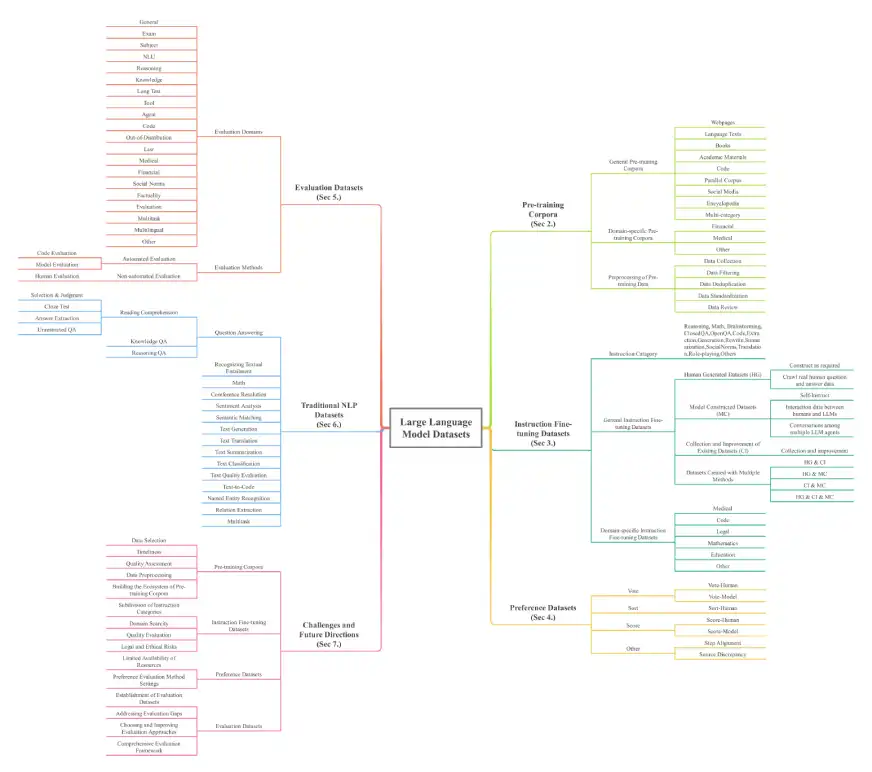
このペーパーでは、これらの強力なモデルの基礎を理解するために不可欠なLLMデータセットの包括的な概要を提供します。データセットは、トレーニング前のコーパス、命令微調整データセット、選好データセット、評価データセット、従来のNLPデータセット、マルチモーダル大手言語モデル(MLLM)データセット、および検索拡張生成(RAG)データセットに分類されます。純粋なスケールは印象的で、32のドメインと8つの言語にまたがる他のカテゴリにわたって、トレーニング前だけで774.5 TBを超えるデータがあり、7億インスタンスがあります。

主要なデータセットのカテゴリと例:
調査では、以下を含むさまざまなデータセットタイプの詳細
トレーニング前のコーパス:初期LLMトレーニングのための大規模なテキストコレクション。例には、Madlad-400(2.8Tトークン)、FineWeb(15TBトークン)、BookCorpusopen(17,868冊の本)が含まれます。これらはさらに、一般的なコーパス(ウェブページ、書籍、言語テキスト)およびドメイン固有のコーパス(金融、医療、数学)に分類されます。
命令微調整データセット:モデルの動作を改善するための指示のペアと対応する回答。例には、DataBricks-Dolly-15KとAlpaca_Dataが含まれます。これらは、一般的およびドメイン固有の(医療、コード)データセットに分類されます。
設定データセット:複数の応答を比較することにより、モデルの出力を評価および改善するために使用されます。例には、chatbot_arena_conversationsとhh-rlhfが含まれます。
評価データセット:さまざまなタスクでLLMパフォーマンスをベンチマークするように特別に設計されています。例には、AlpacaevalおよびBayling-80が含まれます。
従来のNLPデータセット: Pre-LLM NLPタスクに使用されるデータセット。例には、ブールク、コスモスカ、およびPubMedqaが含まれます。
マルチモーダル大手言語モデル(MLLMS)データセット:テキストとその他のモダリティ(画像、ビデオ)を組み合わせたデータセット。例には、モスカーとMMRS-1Mが含まれます。
検索拡張生成(RAG)データセット:外部データ検索機能を使用してLLMを強化するデータセット。例には、Crud-RagとWikievalが含まれます。

出典:大規模な言語モデルのデータセット:包括的な調査
調査のアーキテクチャを以下に示します。
結論とさらなる調査:
この調査は、LLM分野の研究者と開発者を指導する重要なリソースとして機能します。提供されたリポジトリ(Awesome-llms-Datasets)は、これらの貴重なデータセットにアクセスして利用するための完全なロードマップを提供します。詳細な分類と包括的な統計は、LLMを使用したり調査したりする人にとって不可欠なツールになります。この論文はまた、重要な課題に対処し、将来の研究の方向性を提案しています。
以上が400個の分類された大規模な言語モデルデータセットのガイドの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



