

Apache Icebergテーブルの使用方法は?

Apache Iceberg:データレイク管理を強化するための最新のテーブル形式
Apache Icebergは、従来のハイブテーブルの欠点に対処するために設計された最先端のテーブル形式であり、優れたパフォーマンス、データの一貫性、およびスケーラビリティを実現します。この記事では、Icebergの進化、主要な機能(酸トランザクション、スキーマの進化、タイムトラベル)、アーキテクチャ、およびデルタ湖やParquetなどの他のテーブル形式との比較について説明します。また、最新のデータ湖との統合と、大規模なデータ管理と分析への影響を調べます。
重要な学習ポイント
- Apache Icebergのコア機能とアーキテクチャを把握します。
- Icebergがデータの書き換えなしにスキーマとパーティションの進化をどのように促進するかを理解してください。
- 酸トランザクションとタイムトラベルがデータの一貫性を強化する方法を調べます。
- アイスバーグの能力をデルタ湖とフディと比較してください。
- 氷山がデータ湖のパフォーマンスを最適化するシナリオを特定します。
目次
- Apache Icebergの紹介
- 氷山の進化
- 氷山形式の理解
- Apache Icebergのコア機能
- 氷山の建築に深く潜ります
- Iceberg vs.その他のテーブル形式:比較
- 結論
- よくある質問
Apache Icebergの紹介
2017年にNetflixで発信され(Ryan BlueとDaniel Weeksの発案者)、Apache Icebergは、ハイブテーブル形式に固有のパフォーマンスボトルネック、一貫性の問題、制限を解決するために作成されました。 2018年にオープンソーシングされ、Apache Software Foundationに寄付され、すぐに牽引力を獲得し、Apple、AWS、LinkedInなどの業界の巨人からの貢献を引き付けました。
Apache Icebergの進化
Netflixの経験は、ハイブの重大な弱点を強調しました。テーブル追跡のためのディレクトリへの依存です。このアプローチには、堅牢な一貫性、効率的な並行性、および最新のデータ倉庫で予想される高度な機能に必要な粒度がありませんでした。 Icebergの開発は、次のことを焦点を当ててこれらの制限を克服することを目的としています。
主要な設計目標
- データの一貫性:複数のパーティションにおける更新はアトミックでシームレスである必要があり、ユーザーが一貫性のないデータを見ることができなくなります。
- パフォーマンスの最適化:効率的なメタデータ管理は、クエリの計画ボトルネックを排除し、クエリの実行をスピードアップするために最も重要でした。
- ユーザーフレンドリー:パーティション化はユーザーに透過的である必要があり、手動介入なしで自動クエリの最適化を可能にします。
- スキーマの適応性:スキーマの変更は、完全なデータセット書き換えを必要とせずに安全に処理する必要があります。
- スケーラビリティ:ソリューションは、Netflixのスケールをミラーリングして、ペタバイトのデータを効率的に処理する必要がありました。
氷山形式の理解
Icebergは、ディレクトリではなく、ファイルの構造化リストとしてテーブルを追跡することにより、これらの課題に対処します。複数のファイルにわたってメタデータ構造を定義する標準化された形式を提供し、SparkやFlinkなどの人気エンジンとのシームレスな統合のためのライブラリを提供します。
データレイク標準
Icebergの設計は、既存のストレージおよび計算エンジンとの互換性を優先し、大幅な変更なしに広範な採用を促進します。目的は、氷山を業界標準として確立し、ユーザーが基礎となる形式に関係なくテーブルと対話できるようにすることです。現在、多くのデータツールがネイティブアイスバーグのサポートを提供しています。
Apache Icebergのコア機能
アイスバーグは、単にハイブの制限に対処するだけで超越しています。データレイクとデータレイクハウスのワークロードを強化する強力な機能を導入します。主な機能は次のとおりです。
酸トランザクション保証
Icebergは、楽観的な並行性制御を使用して酸性特性を確保し、トランザクションが完全にコミットされるか、完全に巻き戻されていることを保証します。これにより、データの整合性を維持しながら、競合が最小限に抑えられます。
パーティションの進化
従来のデータ湖とは異なり、Icebergはテーブル全体を書き直さずにパーティションスキームを変更できます。これにより、既存のデータを破壊することなく、効率的なクエリ最適化が保証されます。
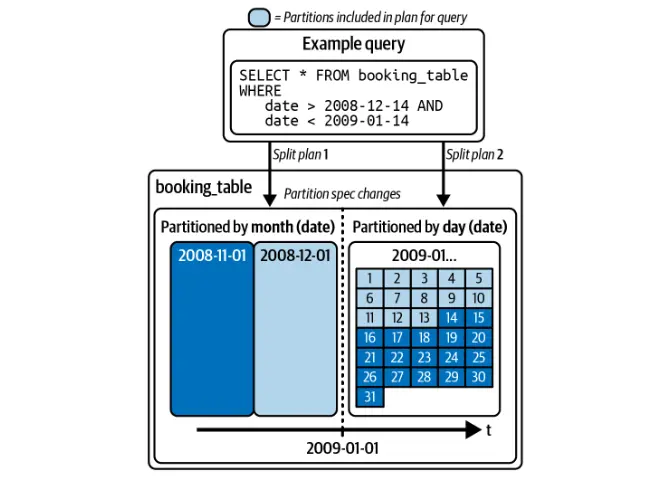
隠されたパーティション
Icebergは、パーティション化に基づいてクエリを自動的に最適化し、ユーザーがパーティション列で手動でフィルタリングする必要性を排除します。
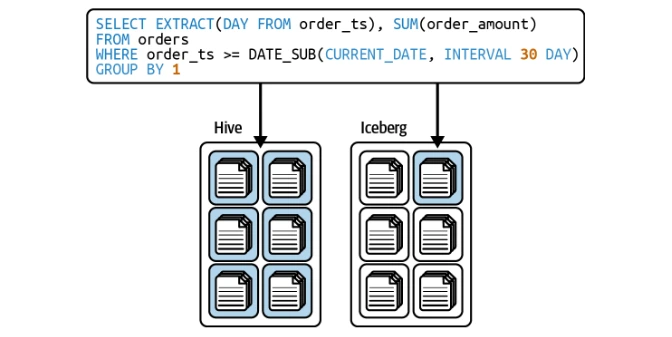
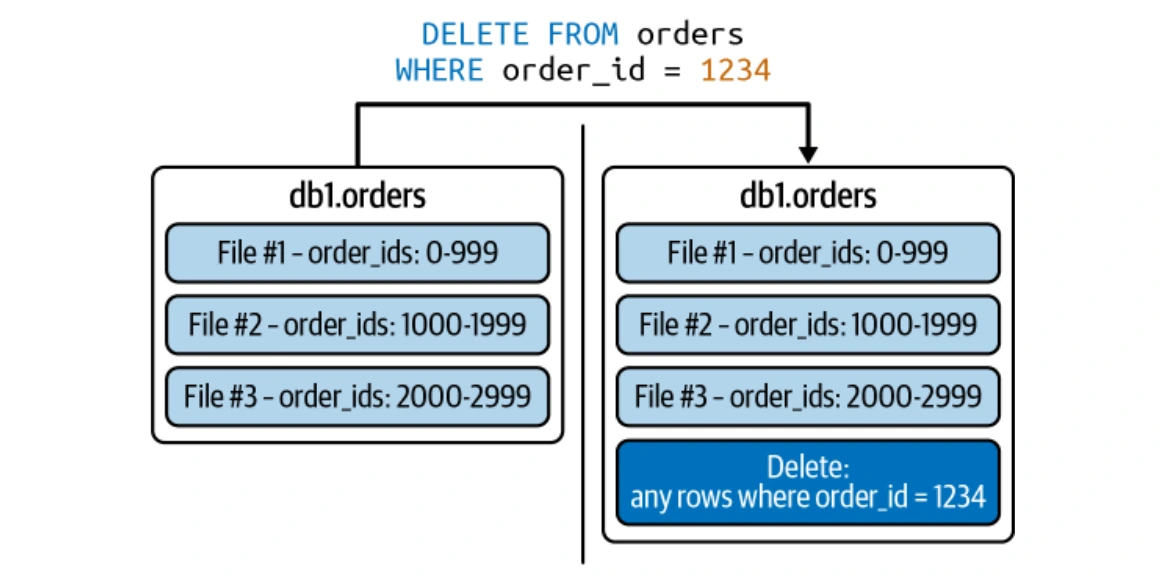
行レベルの操作(コピーオンワイトとマージオンリード)
Icebergは、効率的な行レベルの更新のために、コピーオンワイト(COW)とMerge-on-read(MOR)戦略の両方をサポートしています。
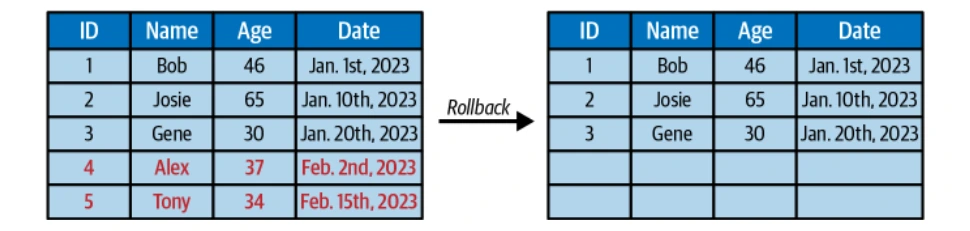
タイムトラベルとバージョンロールバック
Icebergの不変のスナップショットにより、タイムトラベルクエリと以前のテーブル状態にロールバックする機能が可能になります。

スキーマの進化
Icebergは、データの書き換えなしにスキーマの変更(列の追加、削除、または変更)をサポートし、柔軟性と互換性を確保します。
氷山の建築に深く潜ります
このセクションでは、Icebergの建築と、Hiveの制限を克服する方法について説明します。
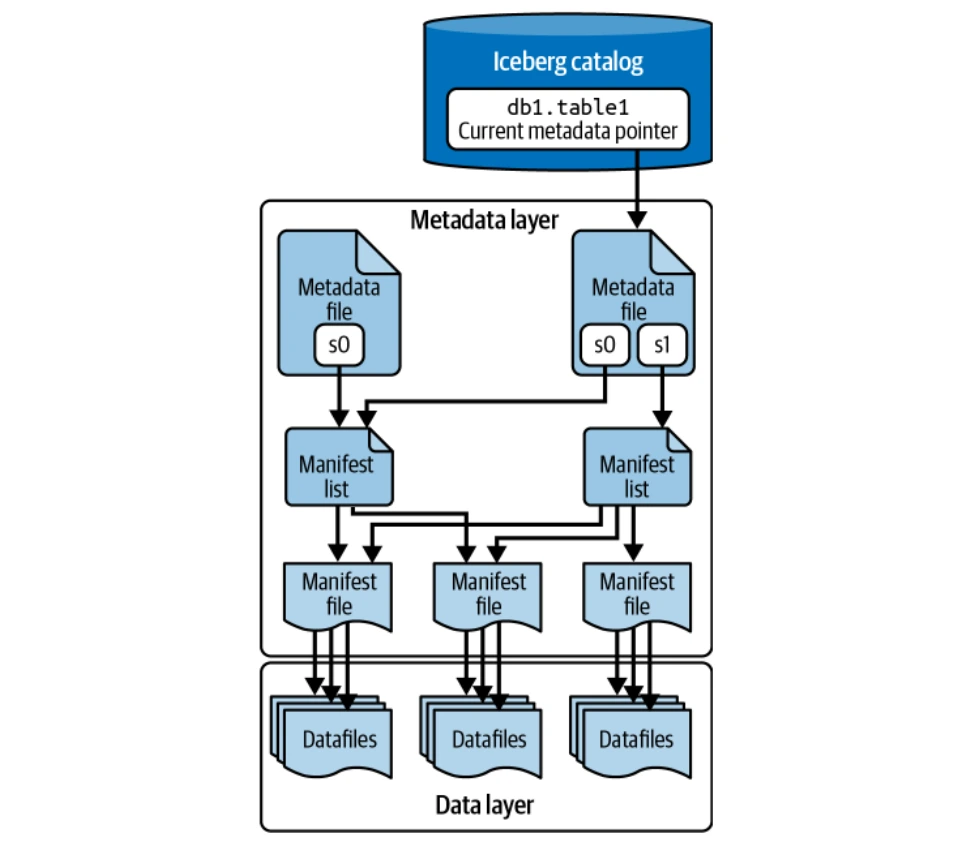
データレイヤー
データレイヤーは、実際のテーブルデータ(データファイルと削除ファイル)を保存します。分散ファイルシステム(HDFS、S3など)でホストされ、複数のファイル形式(Parquet、ORC、AVRO)をサポートしています。寄木細工は、一般的にその円柱状の保管よりも好まれます。


メタデータ層
このレイヤーは、ツリー構造内のすべてのメタデータファイルを管理し、データファイルと操作を追跡します。主要なコンポーネントには、マニフェストファイル、マニフェストリスト、メタデータファイルが含まれます。 Puffin Filesは、クエリ最適化のための高度な統計とインデックスを保存します。
カタログ
カタログは中央のレジストリとして機能し、各テーブルの現在のメタデータファイルの場所を提供し、すべての読者と作家に一貫したアクセスを保証します。さまざまなバックエンドは、Icebergカタログ(Hadoopカタログ、Hive Metastore、Nessie Catalog、AWS Glue Catalog)として機能します。
Iceberg vs.その他のテーブル形式:比較
氷山、パルケット、オーク、デルタ湖は、大規模なデータ処理で頻繁に使用されます。 Icebergは、ファイル形式であるParquetやOrcとは異なり、トランザクション保証とメタデータの最適化を提供するテーブル形式として区別しています。デルタ湖と比較して、アイスバーグはスキーマとパーティションの進化に優れています。
結論
Apache Icebergは、データレイク管理に対する堅牢でスケーラブルでユーザーフレンドリーなアプローチを提供します。その機能により、大規模なデータを処理する組織にとって魅力的なソリューションになります。
よくある質問
Q1。 Apache Icebergとは何ですか? A.データのパフォーマンス、一貫性、およびスケーラビリティを強化する最新のオープンソーステーブル形式。
Q2。 Apache Icebergが必要なのはなぜですか? A.メタデータの取り扱いとトランザクション機能におけるHiveの制限を克服する。
Q3。 Icebergはスキーマの進化をどのように処理しますか? A.完全なテーブル書き換えを必要とせずにスキーマの変更をサポートします。
Q4。 Icebergのパーティションの進化とは何ですか? A.履歴データを書き換えずにパーティションスキームを変更します。
Q5。 Icebergは酸トランザクションをどのようにサポートしていますか? A.楽観的な並行性制御を通じて、アトミックの更新を確保します。
以上がApache Icebergテーブルの使用方法は?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7834
7834
 15
1648
14
1403
52
1300
25
1240
29
15
1648
14
1403
52
1300
25
1240
29

 クリエイティブプロジェクトのための最高のAIアートジェネレーター(無料&有料)
Apr 02, 2025 pm 06:10 PM
クリエイティブプロジェクトのための最高のAIアートジェネレーター(無料&有料)
Apr 02, 2025 pm 06:10 PM
この記事では、トップAIアートジェネレーターをレビューし、その機能、創造的なプロジェクトへの適合性、価値について説明します。 Midjourneyを専門家にとって最高の価値として強調し、高品質でカスタマイズ可能なアートにDall-E 2を推奨しています。
 Meta Llama 3.2を始めましょう - 分析Vidhya
Apr 11, 2025 pm 12:04 PM
Meta Llama 3.2を始めましょう - 分析Vidhya
Apr 11, 2025 pm 12:04 PM
メタのラマ3.2:マルチモーダルとモバイルAIの前進 メタは最近、ラマ3.2を発表しました。これは、モバイルデバイス向けに最適化された強力なビジョン機能と軽量テキストモデルを特徴とするAIの大幅な進歩です。 成功に基づいてo
 ベストAIチャットボットが比較されました(chatgpt、gemini、claude& more)
Apr 02, 2025 pm 06:09 PM
ベストAIチャットボットが比較されました(chatgpt、gemini、claude& more)
Apr 02, 2025 pm 06:09 PM
この記事では、ChatGpt、Gemini、ClaudeなどのトップAIチャットボットを比較し、自然言語の処理と信頼性における独自の機能、カスタマイズオプション、パフォーマンスに焦点を当てています。
 トップAIライティングアシスタントは、コンテンツの作成を後押しします
Apr 02, 2025 pm 06:11 PM
トップAIライティングアシスタントは、コンテンツの作成を後押しします
Apr 02, 2025 pm 06:11 PM
この記事では、Grammarly、Jasper、Copy.ai、Writesonic、RytrなどのトップAIライティングアシスタントについて説明し、コンテンツ作成のためのユニークな機能に焦点を当てています。 JasperがSEOの最適化に優れているのに対し、AIツールはトーンの維持に役立つと主張します
 従業員へのAI戦略の販売:Shopify CEOのマニフェスト
Apr 10, 2025 am 11:19 AM
従業員へのAI戦略の販売:Shopify CEOのマニフェスト
Apr 10, 2025 am 11:19 AM
Shopify CEOのTobiLütkeの最近のメモは、AIの能力がすべての従業員にとって基本的な期待であると大胆に宣言し、会社内の重大な文化的変化を示しています。 これはつかの間の傾向ではありません。これは、pに統合された新しい運用パラダイムです
 AVバイト:Meta' s llama 3.2、GoogleのGemini 1.5など
Apr 11, 2025 pm 12:01 PM
AVバイト:Meta' s llama 3.2、GoogleのGemini 1.5など
Apr 11, 2025 pm 12:01 PM
今週のAIの風景:進歩、倫理的考慮、規制の議論の旋風。 Openai、Google、Meta、Microsoftのような主要なプレーヤーは、画期的な新しいモデルからLEの重要な変化まで、アップデートの急流を解き放ちました
 AIエージェントを構築するためのトップ7エージェントRAGシステム
Mar 31, 2025 pm 04:25 PM
AIエージェントを構築するためのトップ7エージェントRAGシステム
Mar 31, 2025 pm 04:25 PM
2024年は、コンテンツ生成にLLMSを使用することから、内部の仕組みを理解することへの移行を目撃しました。 この調査は、AIエージェントの発見につながりました。これは、最小限の人間の介入でタスクと決定を処理する自律システムを処理しました。 buildin
 最高のAI音声ジェネレーターの選択:レビューされたトップオプション
Apr 02, 2025 pm 06:12 PM
最高のAI音声ジェネレーターの選択:レビューされたトップオプション
Apr 02, 2025 pm 06:12 PM
この記事では、Google Cloud、Amazon Polly、Microsoft Azure、IBM Watson、DecriptなどのトップAI音声ジェネレーターをレビューし、機能、音声品質、さまざまなニーズへの適合性に焦点を当てています。
