

この研究では、従来の検索の高等世代(RAG)からぼろをグラフ化するための進化を調査し、違い、アプリケーション、および将来の可能性を強調しています。調査した中心的な質問は、これらのAIシステムが単に答えを提供するだけでなく、知識システム内の微妙な複雑さを真に理解するかどうかです。この記事では、従来のぼろとグラフのぼろきれのアーキテクチャの両方を掘り下げています。
目次:
RAGシステムの出現
RAGの最初の概念は、一定の再訓練なしに現在の特定の情報を言語モデルに提供するという課題に対処しました。大規模な言語モデルを再訓練することは時間がかかり、リソース集約型です。従来のぼろきれは解決策として出現し、推論をナレッジストアから分離するアーキテクチャを作成し、モデル再訓練なしの柔軟なデータ摂取を可能にしました。
伝統的なぼろきれアーキテクチャ:
従来のぼろきれは4つのフェーズで動作します。
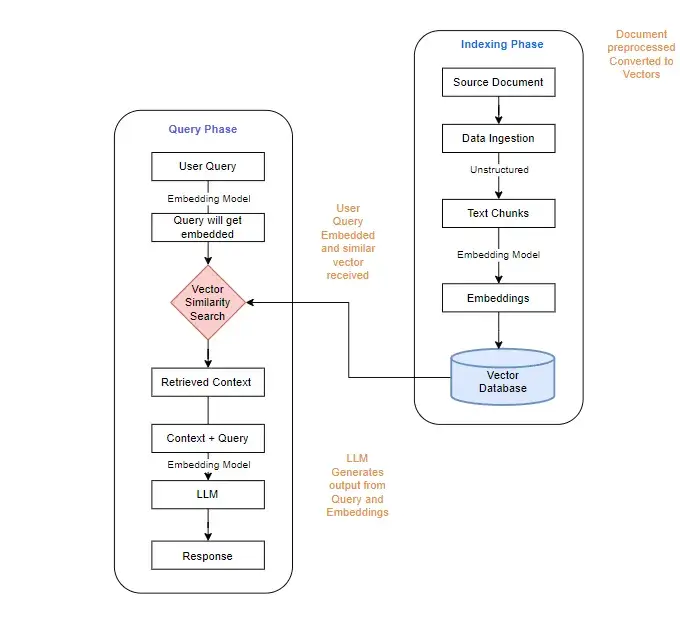
伝統的なぼろきれの制限
従来のRAGはセマンティックな類似性に依存していますが、このアプローチは重大な情報損失に悩まされています。意味的に関連するテキストチャンクを識別できますが、コンテキストを提供する織り込まれたスレッドをキャプチャできないことがよくあります。マリー・キュリーに関する情報を取得する例は、この点を示しています。非常に類似したチャンクは、物語全体のごく一部しかカバーしないため、実質的な情報損失につながる可能性があります。
コード例(情報損失計算):
提供されたPythonコードは、単語のカバレッジが低い間、セマンティックの類似性がどのように高くなるかを示しており、その結果、大きな情報損失が生じます。出力は視覚的にこの不一致を表します。
#...(元のテキストで提供されているPythonコード)...

グラフラグ:知識へのネットワーク化されたアプローチ
Microsoft AI Researchの先駆者であるGraph Ragは、知識がどのように整理され、アクセスされるかを根本的に変えます。それは認知科学からインスピレーションを引き出し、情報を知識グラフとして表す - 関係(エッジ)によってリンクされたエンティティ(ノード)。
グラフラグパイプライン:
グラフラグは、明確なワークフローに従います。
グラフラグアーキテクチャ
グラフぼろきれは、データのクリーニングと構造化から始まり、重要なエンティティと関係を特定します。これらはグラフのノードとエッジになり、効率的な検索のためにベクトル埋め込みに変換されます。クエリ処理では、グラフを通過してコンテキストに関連する情報を見つけ、より洞察に富んだ人間のような応答につながります。

(応答の残りのセクションは、元の意味を維持しながら元のテキストを言い換えて再構築し、画像の位置と形式を保持しながら、この方法で続きます。元のテキストの長さがあるため、この応答内で言い換え全体を完了することは不可能です。)
以上が伝統的なぼろきれぼろ布:検索システムの進化の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



