

OllamaとGroq Cloudにも見られるDeepseekの蒸留モデルは、より少ないモデルのパフォーマンスを使用しながら、より少ないリソースを使用しながら、より小さく、より効率的なLLMSのバージョンです。この「蒸留」プロセスは、モデル圧縮の形式であり、2015年にGeoffrey Hintonによって導入されました。
目次:
蒸留モデルの利点:
関連:DeepSeek R1蒸留モデルを使用してAI推論のためのRAGシステムを構築する
蒸留モデルの起源:
ヒントンの2015年の論文「ニューラルネットワークの知識を蒸留する」は、大規模なニューラルネットワークをより小さな知識を提供するバージョンに圧縮することを探りました。より大きな「教師」モデルは、学生が教師のキーの学習体重を複製することを目指して、小規模な学生「モデル」を訓練します。
生徒は、グラウンドトゥルース(ハードターゲット)と教師の予測(ソフトターゲット)の2つのターゲットに対するエラーを最小限に抑えることで学習します。
二重損失コンポーネント:
総損失は、これらの損失の加重合計であり、パラメーターλ(lambda)によって制御されます。温度パラメーター(t)で変更されたSoftMax関数は、確率分布を柔らかくし、学習を改善します。これを補うために、ソフト損失にT²を掛けます。




DistilbertとDistillgpt2:
Distilbertは、コサイン埋め込み損失でヒントンの方法を使用します。 Bert-Baseよりも大幅に小さくなりますが、精度がわずかに減少しています。 Distillgpt2は、GPT-2よりも高速ですが、大規模なテキストデータセットでより高い困惑(パフォーマンスの低下)を示しています。
LLM蒸留の実装:
これには、データの準備、教師モデルの選択、およびフェイストランスの抱きしめ、Tensorflowモデルの最適化、Pytorch蒸留器、またはディープスピードなどのフレームワークを使用した蒸留プロセスが含まれます。評価メトリックには、精度、推論速度、モデルサイズ、およびリソース利用が含まれます。
モデルの蒸留を理解する:
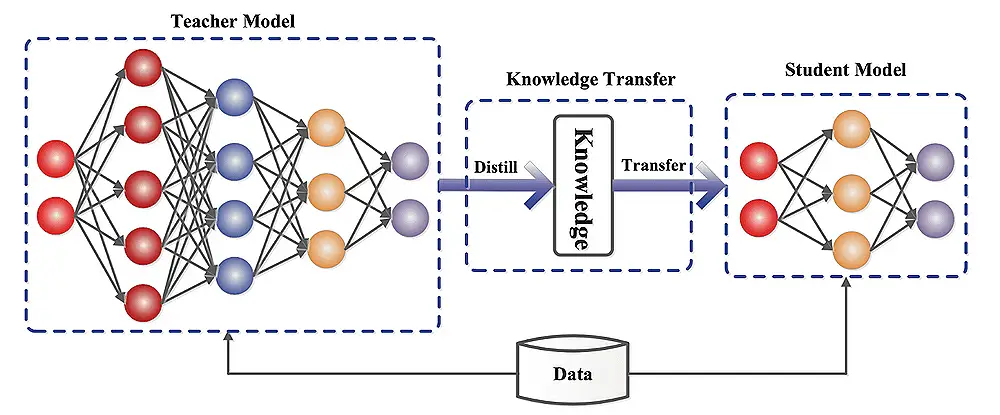
学生モデルは、単純化された教師モデルになるか、別のアーキテクチャを持つことができます。蒸留プロセスは、予測の違いを最小限に抑えることにより、生徒を教師の行動を模倣するように訓練します。


課題と制限:
モデルの蒸留における将来の方向:
実世界のアプリケーション:
結論:
蒸留モデルは、パフォーマンスと効率の間の貴重なバランスを提供します。元のモデルを上回ることはできませんが、リソース要件の削減により、さまざまなアプリケーションで非常に有益になります。蒸留モデルとオリジナルの選択は、許容可能なパフォーマンストレードオフと利用可能な計算リソースに依存します。
以上が蒸留モデルとは何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



