

TFIDFVectorizerを使用して、テキストドキュメントをTF-IDFマトリックスに変換します

この記事では、テキストデータを分析するための自然言語処理(NLP)の重要なツールである周波数逆文書頻度(TF-IDF)手法について説明します。 TF-IDFは、ドキュメント内の頻度とドキュメントのコレクション全体にわたって希少性に基づいて項を重み付けすることにより、基本的な言葉の袋のアプローチの制限を上回ります。この強化された重み付けにより、テキスト分類が改善され、機械学習モデルの分析機能が向上します。 TF-IDFモデルをPythonでゼロから構築し、数値計算を実行する方法を示します。
目次
- TF-IDFの重要な用語
- 用語頻度(TF)が説明しました
- ドキュメント頻度(DF)が説明しました
- 逆ドキュメント頻度(IDF)が説明しました
- TF-IDFの理解
- 数値TF-IDF計算
- ステップ1:ターム周波数の計算(TF)
- ステップ2:逆ドキュメント頻度の計算(IDF)
- ステップ3:TF-IDFの計算
- 内蔵データセットを使用したPython実装
- ステップ1:必要なライブラリのインストール
- ステップ2:ライブラリのインポート
- ステップ3:データセットのロード
- ステップ4:
TfidfVectorizerの初期化 - ステップ5:ドキュメントの取り付けと変換
- ステップ6:TF-IDFマトリックスの検査
- 結論
- よくある質問
TF-IDFの重要な用語
先に進む前に、重要な用語を定義しましょう。
- T :用語(個々の単語)
- D :ドキュメント(単語のセット)
- N :コーパス内のドキュメントの総数
- コーパス:ドキュメントのコレクション全体
用語頻度(TF)が説明しました
用語頻度(TF)は、特定のドキュメントに用語が表示される頻度を定量化します。より高いTFは、そのドキュメント内でより重要性を示しています。式は次のとおりです。
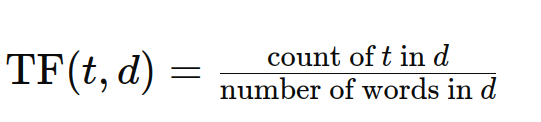
ドキュメント頻度(DF)が説明しました
ドキュメント頻度(DF)は、特定の用語を含むコーパス内のドキュメントの数を測定します。 TFとは異なり、その発生ではなく、用語の存在をカウントします。式は次のとおりです。
df(t)=用語tを含むドキュメントの数
逆ドキュメント頻度(IDF)が説明しました
逆ドキュメント頻度(IDF)は、単語の情報性を評価します。 TFはすべての用語を平等に扱いますが、IDFのダウンウェイトは一般的な単語(停止単語など)と高級の希少な用語を扱います。式は次のとおりです。
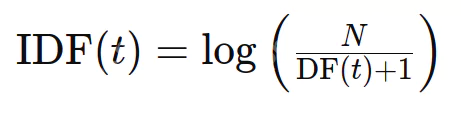
ここで、nはドキュメントの総数とdf(t)は、用語tを含むドキュメントの数です。
TF-IDFの理解
TF-IDFは、用語頻度と逆文書頻度を組み合わせて、コーパス全体に比べてドキュメント内の用語の重要性を決定します。式は次のとおりです。
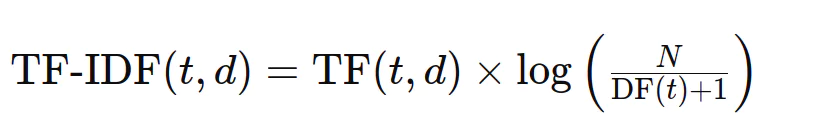
数値TF-IDF計算
例のドキュメントを使用して、数値TF-IDF計算を説明しましょう。
文書:
- 「空は青い。」
- 「今日の太陽は明るいです。」
- 「空の太陽は明るいです。」
- 「輝く太陽、明るい太陽が見えます。」
元のテキストで概説されている手順に従って、各ドキュメントの各用語のTF、IDF、およびTF-IDFを計算します。 (Brevityのために詳細な計算はここでは省略されていますが、元の例を反映しています。)
内蔵データセットを使用したPython実装
このセクションでは、SCIKIT-LEARNのTfidfVectorizerおよび20のNewsGroups Datasetを使用したTF-IDF計算を示します。
ステップ1:必要なライブラリのインストール
ピップインストールScikit-Learn
ステップ2:ライブラリのインポート
PDとしてパンダをインポートします sklearn.datasetsからfetch_20newsgroupsをインポートします Sklearn.feature_extraction.textからtfidfvectorizerをインポートします
ステップ3:データセットのロード
newsgroups = fetch_20newsgroups(subset = 'train')
ステップ4: TfidfVectorizerの初期化
vectorizer = tfidfvectorizer(stop_words = 'inglish'、max_features = 1000)
ステップ5:ドキュメントの取り付けと変換
tfidf_matrix = vectorizer.fit_transform(newsgroups.data)
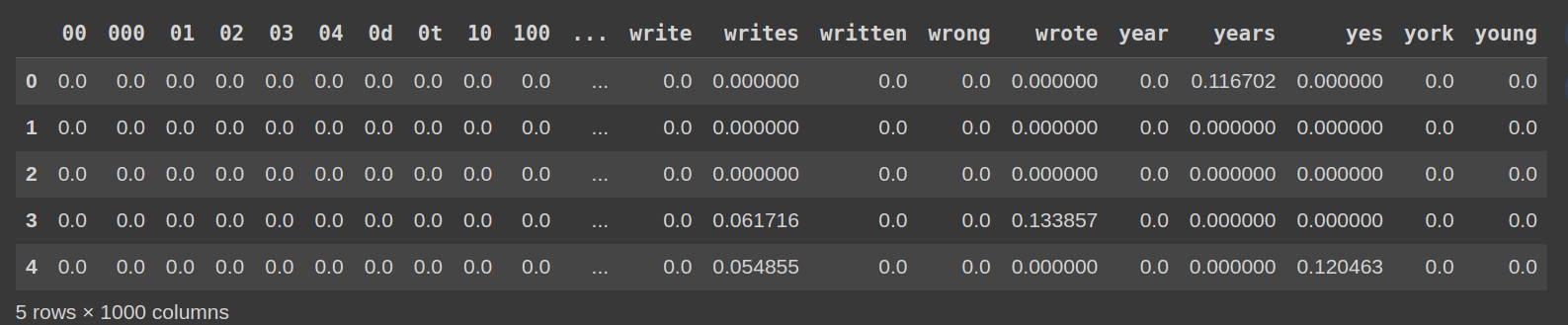
ステップ6:TF-IDFマトリックスの検査
df_tfidf = pd.dataframe(tfidf_matrix.toarray()、columns = vectorizer.get_feature_names_out())) df_tfidf.head()
結論
20のNewsGroups DatasetとTfidfVectorizerを使用して、テキストドキュメントをTF-IDFマトリックスに効率的に変換します。このマトリックスは、各用語の重要性を表し、テキスト分類やクラスタリングなどのさまざまなNLPタスクを可能にします。 Scikit-LearnのTfidfVectorizer 、このプロセスを大幅に簡素化します。
よくある質問
FAQSセクションは、IDFの対数性、大規模なデータセットへのスケーラビリティ、TF-IDFの制限(語順とコンテキストを無視)、および一般的なアプリケーション(検索エンジン、テキスト分類、クラスタリング、要約)の制限に対処することはほとんど変わらないままです。
以上がTFIDFVectorizerを使用して、テキストドキュメントをTF-IDFマトリックスに変換しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7798
7798
 15
1644
14
1402
52
1299
25
1234
29
15
1644
14
1402
52
1299
25
1234
29

 クリエイティブプロジェクトのための最高のAIアートジェネレーター(無料&有料)
Apr 02, 2025 pm 06:10 PM
クリエイティブプロジェクトのための最高のAIアートジェネレーター(無料&有料)
Apr 02, 2025 pm 06:10 PM
この記事では、トップAIアートジェネレーターをレビューし、その機能、創造的なプロジェクトへの適合性、価値について説明します。 Midjourneyを専門家にとって最高の価値として強調し、高品質でカスタマイズ可能なアートにDall-E 2を推奨しています。
 Meta Llama 3.2を始めましょう - 分析Vidhya
Apr 11, 2025 pm 12:04 PM
Meta Llama 3.2を始めましょう - 分析Vidhya
Apr 11, 2025 pm 12:04 PM
メタのラマ3.2:マルチモーダルとモバイルAIの前進 メタは最近、ラマ3.2を発表しました。これは、モバイルデバイス向けに最適化された強力なビジョン機能と軽量テキストモデルを特徴とするAIの大幅な進歩です。 成功に基づいてo
 ベストAIチャットボットが比較されました(chatgpt、gemini、claude& more)
Apr 02, 2025 pm 06:09 PM
ベストAIチャットボットが比較されました(chatgpt、gemini、claude& more)
Apr 02, 2025 pm 06:09 PM
この記事では、ChatGpt、Gemini、ClaudeなどのトップAIチャットボットを比較し、自然言語の処理と信頼性における独自の機能、カスタマイズオプション、パフォーマンスに焦点を当てています。
 トップAIライティングアシスタントは、コンテンツの作成を後押しします
Apr 02, 2025 pm 06:11 PM
トップAIライティングアシスタントは、コンテンツの作成を後押しします
Apr 02, 2025 pm 06:11 PM
この記事では、Grammarly、Jasper、Copy.ai、Writesonic、RytrなどのトップAIライティングアシスタントについて説明し、コンテンツ作成のためのユニークな機能に焦点を当てています。 JasperがSEOの最適化に優れているのに対し、AIツールはトーンの維持に役立つと主張します
 AVバイト:Meta' s llama 3.2、GoogleのGemini 1.5など
Apr 11, 2025 pm 12:01 PM
AVバイト:Meta' s llama 3.2、GoogleのGemini 1.5など
Apr 11, 2025 pm 12:01 PM
今週のAIの風景:進歩、倫理的考慮、規制の議論の旋風。 Openai、Google、Meta、Microsoftのような主要なプレーヤーは、画期的な新しいモデルからLEの重要な変化まで、アップデートの急流を解き放ちました
 AIエージェントを構築するためのトップ7エージェントRAGシステム
Mar 31, 2025 pm 04:25 PM
AIエージェントを構築するためのトップ7エージェントRAGシステム
Mar 31, 2025 pm 04:25 PM
2024年は、コンテンツ生成にLLMSを使用することから、内部の仕組みを理解することへの移行を目撃しました。 この調査は、AIエージェントの発見につながりました。これは、最小限の人間の介入でタスクと決定を処理する自律システムを処理しました。 buildin
 従業員へのAI戦略の販売:Shopify CEOのマニフェスト
Apr 10, 2025 am 11:19 AM
従業員へのAI戦略の販売:Shopify CEOのマニフェスト
Apr 10, 2025 am 11:19 AM
Shopify CEOのTobiLütkeの最近のメモは、AIの能力がすべての従業員にとって基本的な期待であると大胆に宣言し、会社内の重大な文化的変化を示しています。 これはつかの間の傾向ではありません。これは、pに統合された新しい運用パラダイムです
 最高のAI音声ジェネレーターの選択:レビューされたトップオプション
Apr 02, 2025 pm 06:12 PM
最高のAI音声ジェネレーターの選択:レビューされたトップオプション
Apr 02, 2025 pm 06:12 PM
この記事では、Google Cloud、Amazon Polly、Microsoft Azure、IBM Watson、DecriptなどのトップAI音声ジェネレーターをレビューし、機能、音声品質、さまざまなニーズへの適合性に焦点を当てています。
