

AIパフォーマンスの最適化:効率的なLLM展開ガイド

高性能AIアプリケーションのために大規模な言語モデル(LLM)をマスターする
人工知能の台頭(AI)は、最適な革新と生産性のために効率的なLLM展開を必要とします。即時の洞察を提供するニーズまたはデータ分析ツールを予測するAIを搭載したカスタマーサービスを想像してください。これには、LLMサービングをマスターする必要があります - LLMを高性能のリアルタイムアプリケーションに変換します。この記事では、効率的なLLMのサービングと展開について、最適なプラットフォーム、最適化戦略、および強力で応答性の高いAIソリューションを作成するための実用的な例をカバーします。

主要な学習目標:
- LLM展開の概念とリアルタイムアプリケーションにおけるその重要性を把握します。
- 機能やユースケースなど、さまざまなLLMサービングフレームワークを調べます。
- さまざまなフレームワークを使用してLLMを展開するためのコード例で実践的な経験を積む。
- レイテンシとスループットに基づいて、LLMサービングフレームワークを比較およびベンチマークすることを学びます。
- さまざまなアプリケーションで特定のLLMサービングフレームワークを使用するための理想的なシナリオを特定します。
この記事は、Data Science Blogathonの一部です。
目次:
- 導入
- Triton Inference Server:ディープダイビング
- 生産テキスト生成のためのハギングフェイスモデルの最適化
- VLLM:言語モデルのバッチ処理の革新
- DeepSpeed-MII:効率的なLLM展開のためにディープスピードを活用します
- OpenllM:適応可能なフレームワーク統合
- Ray Serveを使用したスケーリングモデルの展開
- Ctranslate2による推論の加速
- 遅延とスループットの比較
- 結論
- よくある質問
Triton Inference Server:ディープダイビング
Triton Inference Serverは、生産中の機械学習モデルを展開およびスケーリングするための堅牢なプラットフォームです。 Nvidiaによって開発されたTensorflow、Pytorch、ONNX、およびカスタムバックエンドをサポートしています。
主な機能:
- モデル管理:動的荷重/アンロード、バージョン制御。
- 推論の最適化:マルチモデルアンサンブル、バッチ、動的バッチ。
- メトリックとロギング:監視用のプロメテウス統合。
- アクセラレータサポート:GPU、CPU、およびDLAサポート。
セットアップと構成:
Tritonのセットアップは複雑であり、DockerとKubernetesの親しみやすさが必要です。ただし、Nvidiaは包括的なドキュメントとコミュニティサポートを提供しています。
使用事例:
パフォーマンス、スケーラビリティ、マルチフレームワークのサポートを必要とする大規模な展開に最適です。
デモコードと説明:(コードは元の入力と同じままです)
生産テキスト生成のためのハギングフェイスモデルの最適化
このセクションでは、テキスト生成のためにハギングフェイスモデルの使用に焦点を当て、追加のアダプターなしでネイティブサポートを強調します。並列処理、リクエスト管理のためのバッファリング、効率のバッチにモデルシャードを使用します。 GRPCは、コンポーネント間の迅速な通信を保証します。
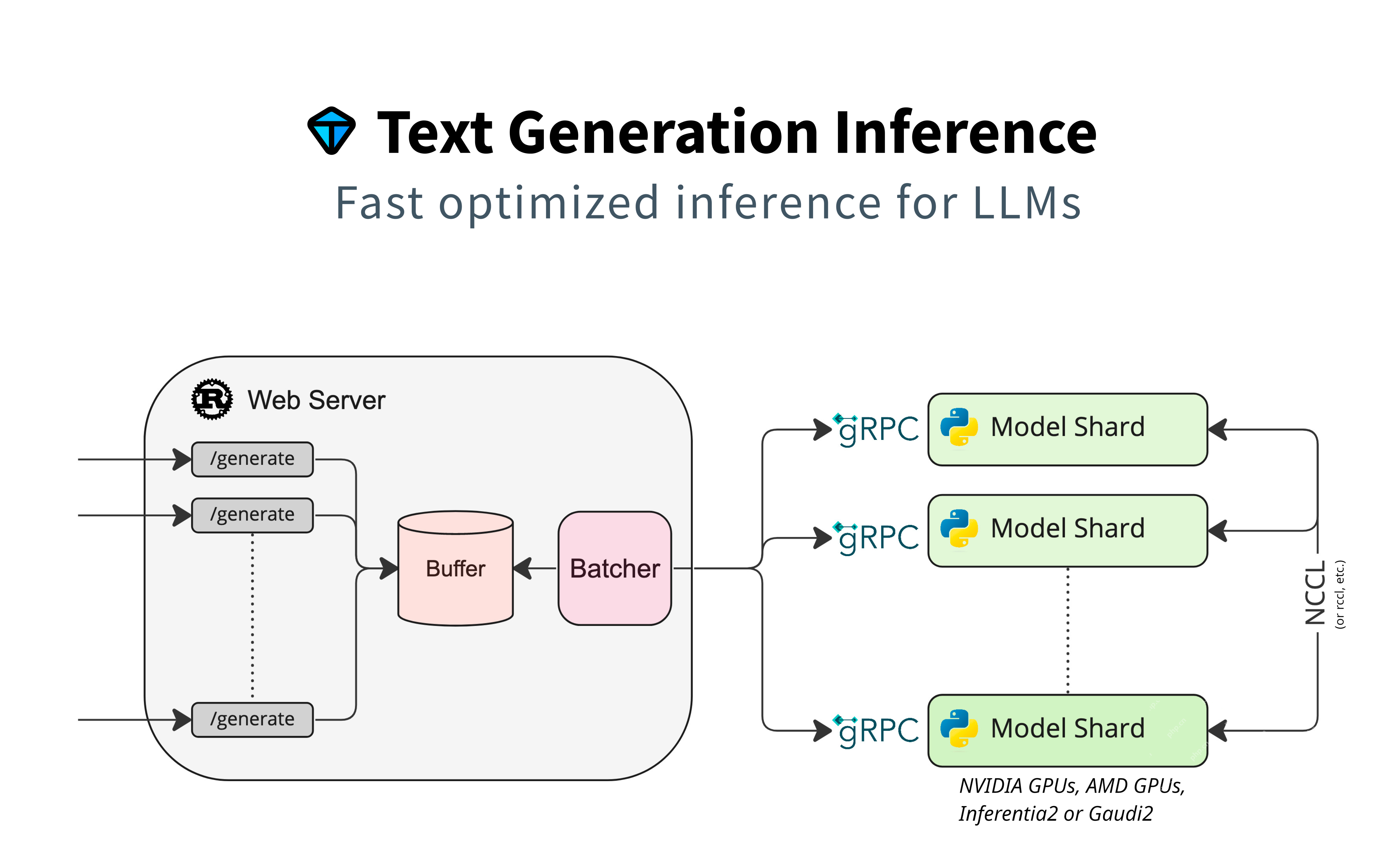
主な機能:
- ユーザーフレンドリー:シームレスなハギングフェイスの統合。
- カスタマイズ:微調整およびカスタム構成が可能になります。
- トランスのサポート:トランスライブラリを活用します。
ユースケース:
チャットボットやコンテンツ生成など、直接ハグFaceモデルの統合を必要とするアプリケーションに適しています。
デモコードと説明:(コードは元の入力と同じままです)
VLLM:言語モデルのバッチ処理の革新
VLLMは、バッチされたプロンプト配信の速度を優先し、レイテンシとスループットを最適化します。効率的なバッチテキスト生成のために、ベクトル化された操作と並列処理を使用します。

主な機能:
- 高性能:低レイテンシとスループットの高さに最適化されています。
- バッチ処理:バッチリクエストの効率的な処理。
- スケーラビリティ:大規模な展開に適しています。
ユースケース:
リアルタイム翻訳やインタラクティブなAIシステムなど、速度に最適なアプリケーションに最適です。
デモコードと説明:(コードは元の入力と同じままです)
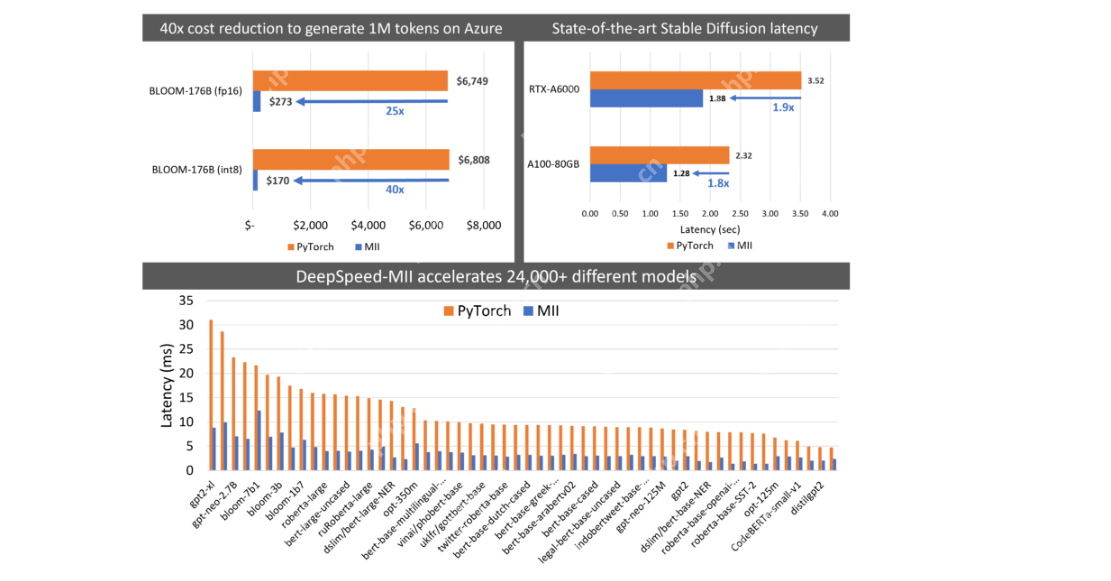
DeepSpeed-MII:効率的なLLM展開のためにディープスピードを利用します
DeepSpeed-MIIは、DeepSpeedを経験したユーザー向けで、効率的なLLM展開に焦点を当て、モデルの並列性、メモリ効率、速度の最適化をスケーリングします。

主な機能:
- 効率:メモリと計算効率。
- スケーラビリティ:非常に大きなモデルを処理します。
- 統合:ディープスピードワークフローを使用したシームレス。
ユースケース:
Deepspeedに精通している研究者や開発者に最適であり、高性能トレーニングと展開の優先順位を付けています。
デモコードと説明:(コードは元の入力と同じままです)
Openllm:柔軟なアダプター統合
Openllmは、アダプターをコアモデルに接続し、ハグFaceエージェントを使用します。 Pytorchを含む複数のフレームワークをサポートします。
主な機能:
- フレームワークアグノーティス:複数の深い学習フレームワークをサポートします。
- エージェントの統合:レバレッジハグFaceエージェント。
- アダプターサポート:モデルアダプターとの柔軟な統合。
ユースケース:
フレームワークの柔軟性と広範なハグするフェイスツールの使用を必要とするプロジェクトに最適です。
デモコードと説明:(コードは元の入力と同じままです)

レイレイのレバレッジは、スケーラブルなモデルの展開に役立ちます
Ray Servは、信頼できるスケーラブルなソリューションを必要とする成熟プロジェクトの安定したパイプラインと柔軟な展開を提供します。
主な機能:
- 柔軟性:複数の展開アーキテクチャをサポートします。
- スケーラビリティ:ハイロードアプリケーションを処理します。
- 統合:Rayのエコシステムでうまく機能します。
ユースケース:
堅牢でスケーラブルなサービングインフラストラクチャを必要とする確立されたプロジェクトに最適です。
デモコードと説明:(コードは元の入力と同じままです)
Ctranslate2を使用した推論を高速化します
Ctranslate2は、特にCPUベースの推論に対して速度を優先します。翻訳モデル用に最適化されており、さまざまなアーキテクチャをサポートしています。
主な機能:
- CPU最適化:CPU推論の高性能。
- 互換性:一般的なモデルアーキテクチャをサポートします。
- 軽量:最小限の依存関係。
ユースケース:
翻訳サービスなどのCPU速度と効率の優先順位付けに適しています。
デモコードと説明:(コードは元の入力と同じままです)

遅延とスループットの比較
(レイテンシとスループットを比較するテーブルと画像は、元の入力と同じままです)
結論
応答性の高いAIアプリケーションにとって、効率的なLLMサービングが重要です。この記事では、それぞれに独自の利点があるさまざまなプラットフォームを調査しました。最良の選択は、特定のニーズに依存します。
重要なテイクアウト:
- モデルに提供するモデルは、推論のために訓練されたモデルを展開します。
- さまざまなプラットフォームが異なるパフォーマンスの面で優れています。
- フレームワークの選択は、ユースケースに依存します。
- 一部のフレームワークは、成熟したプロジェクトでのスケーラブルな展開に適しています。
よくある質問:
(FAQは元の入力と同じままです)
注:この記事に示されているメディアは、[関連するエンティティに言及]が所有しておらず、著者の裁量で使用されます。
以上がAIパフォーマンスの最適化:効率的なLLM展開ガイドの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7760
7760
 15
1644
14
1399
52
1293
25
1234
29
15
1644
14
1399
52
1293
25
1234
29

 クリエイティブプロジェクトのための最高のAIアートジェネレーター(無料&有料)
Apr 02, 2025 pm 06:10 PM
クリエイティブプロジェクトのための最高のAIアートジェネレーター(無料&有料)
Apr 02, 2025 pm 06:10 PM
この記事では、トップAIアートジェネレーターをレビューし、その機能、創造的なプロジェクトへの適合性、価値について説明します。 Midjourneyを専門家にとって最高の価値として強調し、高品質でカスタマイズ可能なアートにDall-E 2を推奨しています。
 Meta Llama 3.2を始めましょう - 分析Vidhya
Apr 11, 2025 pm 12:04 PM
Meta Llama 3.2を始めましょう - 分析Vidhya
Apr 11, 2025 pm 12:04 PM
メタのラマ3.2:マルチモーダルとモバイルAIの前進 メタは最近、ラマ3.2を発表しました。これは、モバイルデバイス向けに最適化された強力なビジョン機能と軽量テキストモデルを特徴とするAIの大幅な進歩です。 成功に基づいてo
 ベストAIチャットボットが比較されました(chatgpt、gemini、claude& more)
Apr 02, 2025 pm 06:09 PM
ベストAIチャットボットが比較されました(chatgpt、gemini、claude& more)
Apr 02, 2025 pm 06:09 PM
この記事では、ChatGpt、Gemini、ClaudeなどのトップAIチャットボットを比較し、自然言語の処理と信頼性における独自の機能、カスタマイズオプション、パフォーマンスに焦点を当てています。
 ChatGpt 4 oは利用できますか?
Mar 28, 2025 pm 05:29 PM
ChatGpt 4 oは利用できますか?
Mar 28, 2025 pm 05:29 PM
CHATGPT 4は現在利用可能で広く使用されており、CHATGPT 3.5のような前任者と比較して、コンテキストを理解し、一貫した応答を生成することに大幅な改善を示しています。将来の開発には、よりパーソナライズされたインターが含まれる場合があります
 トップAIライティングアシスタントは、コンテンツの作成を後押しします
Apr 02, 2025 pm 06:11 PM
トップAIライティングアシスタントは、コンテンツの作成を後押しします
Apr 02, 2025 pm 06:11 PM
この記事では、Grammarly、Jasper、Copy.ai、Writesonic、RytrなどのトップAIライティングアシスタントについて説明し、コンテンツ作成のためのユニークな機能に焦点を当てています。 JasperがSEOの最適化に優れているのに対し、AIツールはトーンの維持に役立つと主張します
 AIエージェントを構築するためのトップ7エージェントRAGシステム
Mar 31, 2025 pm 04:25 PM
AIエージェントを構築するためのトップ7エージェントRAGシステム
Mar 31, 2025 pm 04:25 PM
2024年は、コンテンツ生成にLLMSを使用することから、内部の仕組みを理解することへの移行を目撃しました。 この調査は、AIエージェントの発見につながりました。これは、最小限の人間の介入でタスクと決定を処理する自律システムを処理しました。 buildin
 最高のAI音声ジェネレーターの選択:レビューされたトップオプション
Apr 02, 2025 pm 06:12 PM
最高のAI音声ジェネレーターの選択:レビューされたトップオプション
Apr 02, 2025 pm 06:12 PM
この記事では、Google Cloud、Amazon Polly、Microsoft Azure、IBM Watson、DecriptなどのトップAI音声ジェネレーターをレビューし、機能、音声品質、さまざまなニーズへの適合性に焦点を当てています。
 従業員へのAI戦略の販売:Shopify CEOのマニフェスト
Apr 10, 2025 am 11:19 AM
従業員へのAI戦略の販売:Shopify CEOのマニフェスト
Apr 10, 2025 am 11:19 AM
Shopify CEOのTobiLütkeの最近のメモは、AIの能力がすべての従業員にとって基本的な期待であると大胆に宣言し、会社内の重大な文化的変化を示しています。 これはつかの間の傾向ではありません。これは、pに統合された新しい運用パラダイムです
