

プロトタイプのソースコードの文字列部分の簡単な分析(2)_プロトタイプ

| 格式 | camelize | capitalize | underscore | dasherize | inspect |
| 变形 | toArray | succ | times |
これにはエスケープする必要がある文字が含まれるため、エスケープ文字情報のコピーが当然必要になります。これはすぐ下に示されています。
String.specialChar = {
'b': '\b',
't': '\ t'、
'n': '\n'、
'f': '\f'、
'r': '\r'、
'\': '\\'
}
[JSON.js では、余分な '"' が存在します。これは、JSON の文字列に "" を含めることができないため、エスケープする必要があります。
もちろん、最初のステップは特殊なエスケープ文字を置き換えることです。初期バージョン:
function Inspection () {
return this.replace(/[btnfr\]/,function(a){
return String.specialChar[a];
}) ;
}
JSON 形式の場合は、二重引用符が必要であるため、独自の戻り形式を選択できる必要があります。そのため、デフォルトでは useDoubleQuotes を使用します。文字列を返すには引用符で囲みます。
function Inspection(useDoubleQuotes) {
varscapeString = this.replace(/[btnfr\]/,function(a){
return String.specialChar[a];
});
if (useDoubleQuotes){
return '" ' エスケープ文字列.replace(/"/g, '\"') '"';
}
return "" エスケープ文字列.replace(/'/g, '\"') "'";
}
これはソース コードの関数と似ていますが、プロトタイプ ソース コードの実装はそうではありません。主な違いは、escapeString セクションにあります。すべての制御文字はソース コードに直接リストされ、[x00-x1f] として表現され、さらに '' は [x00-x1f\] となるため、上記の変更の初期バージョンは次のようになります:
function Inspection(useDoubleQuotes) {
varscapeString = this.replace(/[x00 -x1f\]/g , function(character) {
if (String.specialChar の文字) {
return String.specialChar[character];
return 文字
}) ;
if ( useDoubleQuotes) return '"'scapeString.replace(/"/g, '\"') '"';
return "'"scapeString.replace(/'/g, '\'' ) "'";
}
[html]
x00-x1f に対応する ASCII 制御文字エンコーディング テーブルを添付します:
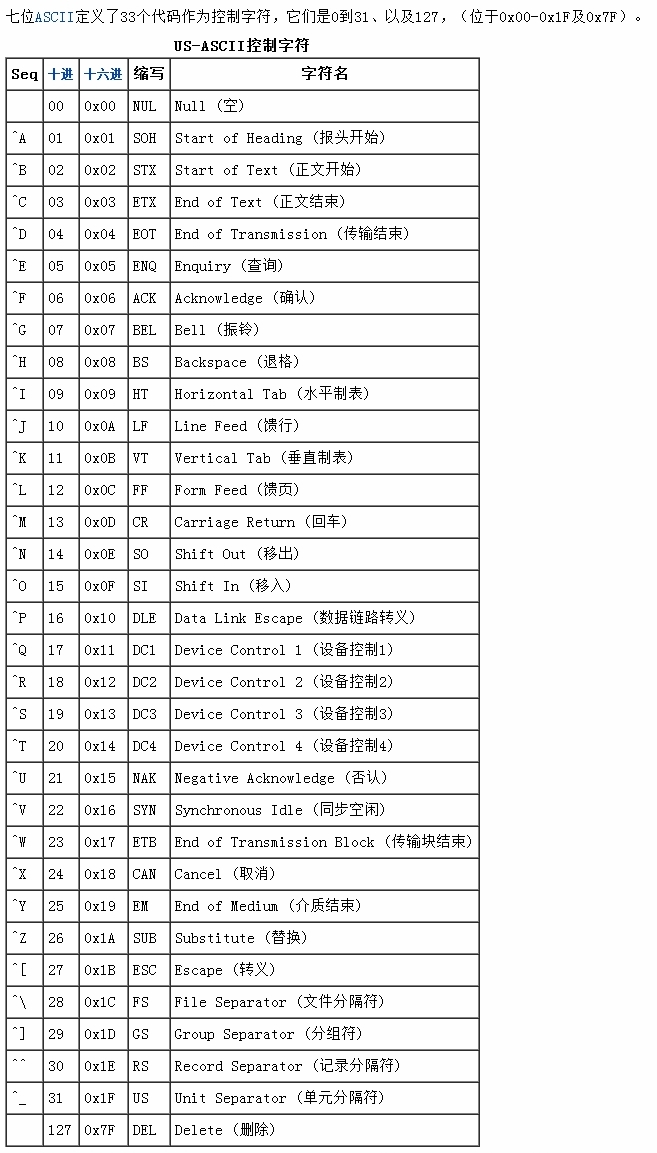
たとえば、垂直タブ文字「v」です。 'v'.inspect() -->'u000b'
完全版:
[code]
function Inspection(useDoubleQuotes) {
varscapeString = this.replace(/[x00-x1f \]/g, function(character) {
if (String.specialChar の文字) {
return String.specialChar[character]
}
return '\u00'character.charCodeAt() .toPaddedString(2, 16);
});
if (useDoubleQuotes) returnsString(/"/g, '\"') '"'; scapeString.replace(/'/g, '\'') "'";
}
の場合、toPaddedString(length[, radix]) は現在の Number オブジェクトを文字列に変換します。変換された文字列の長さが length で指定された値より小さい場合、0 が左側の残りの桁の埋め込みに使用されます。オプションのパラメータ radix は、変換に使用される基数を指定するために使用されます。これは Prototype の Number の拡張です。とりあえず知っておいてください。
メソッドの説明:
toArray: 文字列を文字配列に分割します。
succ: Unicode アルファベットに従って文字列の最後の文字を後続の文字に変換します。
times: 文字列を繰り返します。
対応する具体的な実装も非常にシンプルで、String 部分の重要な部分は後続のスクリプト、JSON、置換処理にあり、その他は強化されています。
function toArray() {
return this.split('');
}
ここで、split('') は文字列を個々の文字に分割して返します。さらに拡張したい場合は、toArray にパラメータを与えて区切り文字を指定できます。
function toArray(pattern) {
これを返します。 "xesam" ]
split を使用するだけですが、必要がないためソースコードでは行われていません。
}
ここでの主なものは次のとおりです。 fromCharCode メソッドと charCodeAt メソッドを使用します。また、このコードから、この 2 つの明らかな違いは、fromCharCode が String の静的メソッドであるのに対し、charCodeAt は String.prototype にぶら下がっている string のメソッドであることであることがわかります。次に、この 2 つはまったく逆の効果をもたらします。 http://www.w3school.com.cn による説明は次のとおりです。
charCodeAt() メソッドは、指定された位置にある文字の Unicode エンコーディングを返します。この戻り値は 0 ~ 65535 の整数です。
succ に固有で、文字列 'hello xesam' を例にとると、最初に終了文字を除くすべての文字 'hello xesa' を取得し、次に Unicode テーブルの 'm' の後に文字 'n' を追加します。結果は「hello xesan」です。
これに基づいて、「a」から「z」までのすべての文字を印刷したい場合は、次の関数を使用できます:
var e = (end '').charCodeAt();
if(s > e){
s = [e,e=s][0]
for(var i = s ;i console.log(String.fromCharCode(i))
}
}
printChar('a','z ');
回の関数は繰り返します。主なアイデアは、現在の文字を配列の連結子として呼び出して追加することであり、期待どおりの結果が得られます。もちろん、ループを使用して追加することもできますが、それほど単純ではありません。
文字列内の各文字を繰り返したい場合は、同じ考え方を使用できます:
コードをコピー
return arr.join(a);
})
}
console.log('xesam'.letterTimes(3));//xxxeeesssaaammm
camelize | underscore | これらの 4 つは主に変数名の変換に関するものです。
camelize: ダッシュで区切られた文字列を Camel 形式に変換します。
アンダースコア: Camel 形式の文字列をアンダースコア ("_") で区切られた一連の単語に変換します。
dasherize: 文字列内のすべてのアンダースコアをダッシュに置き換えます (「_」は「-」に置き換えられます)。
最も明白なものは、CSS 属性と DOM スタイル属性の間の相互変換に使用できます (class と float はこのカテゴリに分類されません)。上記のメソッドに対応して、camelize メソッドを使用して CSS 属性を対応する DOM スタイル属性に変換できますが、その逆のメソッドはないため、underscore -> dumperize メソッドを連続して呼び出す必要があります。
コードをコピー
中心となるのは replace メソッドの使用であり、残りは非常に単純です。「文字列における Replace メソッドの適用の簡単な分析」を参照してください。
function Capitalize() {
return this.charAt(0).toUpperCase() this.substring (1).toLowerCase();
}
ここで、charAt (charAt() メソッドは指定された位置の文字を返すことができます) と charCodeAt の違いに注意してください。
function underscore() {
return this.replace(/::/g, '/')
.replace(/([A-Z] )([A-Z][a-z])/g, '$1_$2')
。 replace(/ ([a-zd])([A-Z])/g, '$1_$2')
.replace(/-/g, '_')
.toLowerCase(); }
//'helloWorld::ABCDefg'
.replace(/::/g, '/') //'helloWorld/ ABCDefg'
.replace( /([A-Z] )([A-Z][a-z])/g, '$1_$2')//helloWorld/ABC_Defg
.replace(/([a-zd]) ([A-Z])/g, '$1_$2') //hello_World/ABC_Defg
.replace(/-/g, '_') //hello_World/ABC_Defg
.toLowerCase(); /abc_defg
return this.replace (/_/g, '-');
}
小西山子出身

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。
人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7758
7758
 15
1644
14
1399
52
1293
25
1234
29
15
1644
14
1399
52
1293
25
1234
29

 Java の String.valueOf() 関数を使用して基本データ型を文字列に変換する
Jul 24, 2023 pm 07:55 PM
Java の String.valueOf() 関数を使用して基本データ型を文字列に変換する
Jul 24, 2023 pm 07:55 PM
Java の String.valueOf() 関数を使用して基本データ型を文字列に変換する Java 開発で基本データ型を文字列に変換する必要がある場合、一般的な方法は String クラスの valueOf() 関数を使用することです。この関数は、基本データ型のパラメータを受け入れ、対応する文字列表現を返すことができます。この記事では、基本的なデータ型変換に String.valueOf() 関数を使用する方法を検討し、いくつかのコード例を提供します。
 char配列を文字列に変換する方法
Jun 09, 2023 am 10:04 AM
char配列を文字列に変換する方法
Jun 09, 2023 am 10:04 AM
char配列をstringに変換する方法:代入によって実現できます {char a[]=" abc d\0efg ";string s=a;} 構文を使用して、char配列にstringに値を直接代入させて実行します変換を完了するためのコード。
 Java の String.replace() 関数を使用して、文字列内の文字 (文字列) を置換します。
Jul 25, 2023 pm 05:16 PM
Java の String.replace() 関数を使用して、文字列内の文字 (文字列) を置換します。
Jul 25, 2023 pm 05:16 PM
Java の String.replace() 関数を使用して文字列内の文字 (文字列) を置換する Java では、文字列は不変オブジェクトです。つまり、文字列オブジェクトが作成されると、その値は変更できません。ただし、文字列内の特定の文字または文字列を置換する必要がある状況が発生する場合があります。現時点では、Java の String クラスの replace() メソッドを使用して文字列置換を実装できます。 String クラスの replace() メソッドには 2 つのタイプがあります。
 2wワード詳細説明文字列、yyds
Aug 24, 2023 pm 03:56 PM
2wワード詳細説明文字列、yyds
Aug 24, 2023 pm 03:56 PM
皆さんこんにちは。今日は Java の基本知識である String についてお話します。 String クラスの重要性は言うまでもなく、バックエンド開発で最もよく使用されるクラスであるため、説明する必要があります。
 Golang関数のバイト、ルーン、文字列型変換スキル
May 17, 2023 am 08:21 AM
Golang関数のバイト、ルーン、文字列型変換スキル
May 17, 2023 am 08:21 AM
Golang プログラミングでは、バイト、ルーン、文字列型は非常に基本的で一般的なデータ型です。これらは、文字列やファイル ストリームなどのデータ操作の処理において重要な役割を果たします。これらのデータ操作を実行するときは、通常、データを相互に変換する必要があるため、変換スキルを習得する必要があります。この記事では、読者がこれらのデータ型をより深く理解し、プログラミングの実践に上手に適用できるようにすることを目的として、Golang 関数のバイト、ルーン、および文字列の型変換テクニックを紹介します。
 JavaのString.length()関数を使用して文字列の長さを取得します。
Jul 25, 2023 am 09:09 AM
JavaのString.length()関数を使用して文字列の長さを取得します。
Jul 25, 2023 am 09:09 AM
文字列の長さを取得するには、Java の String.length() 関数を使用します。Java プログラミングでは、文字列は非常に一般的なデータ型です。多くの場合、文字列の長さ、つまり文字列内の文字数を取得する必要があります。 Java では、String クラスの length() 関数を使用して文字列の長さを取得できます。簡単なコード例を次に示します。 publicclassStringLengthExample{publ
 JavaのStringクラスの使い方
Apr 19, 2023 pm 01:19 PM
JavaのStringクラスの使い方
Apr 19, 2023 pm 01:19 PM
1. JDK の String1. String を理解する まず、JDK の String クラスのソース コードを見てみましょう. これには多くのインターフェイスが実装されています. String クラスは Final によって変更されていることがわかります. これは、String クラスができないことを意味しますString. クラスのサブクラスは継承されず、String. クラスのサブクラスは存在しないため、JDK を使用するすべての人が同じ String クラスを使用します。String の継承が許可されている場合、誰もが String を拡張できます。全員が異なるバージョンの String を使用し、2 人の異なる人が String. クラスを使用します。同じメソッドでも異なる結果が表示されるため、コードの開発が不可能になります。継承とメソッドのオーバーライドは柔軟性をもたらすだけでなく、多くのサブクラスの動作が異なる原因になります。
 JavaのString.toLowerCase()関数を使用して文字列を小文字に変換します。
Jul 24, 2023 pm 11:52 PM
JavaのString.toLowerCase()関数を使用して文字列を小文字に変換します。
Jul 24, 2023 pm 11:52 PM
String.toLowerCase() 関数は、文字列を小文字に変換できる、Java の非常に便利な一般的な文字列処理関数です。この記事では、この関数の使用方法と関連するコード例をいくつか紹介します。まず、String.toLowerCase() 関数の基本構文を見てみましょう。パラメータはありません。ただ呼び出すだけです。サンプルコードは次のとおりです: Stringstr="Hel
