

PHP は中国語の文字列をインターセプトし、指定された文字列が最初に出現した時点でインターセプトし、100 文字をインターセプトします。

PHP は、指定された文字列が最初に出現した時点で中国語の文字列をインターセプトし、100 文字をインターセプトします。
前述のように、次の 2 つの方法でインターセプトを実行しましたが、結果が間違っていることがわかりました。アドバイスをお願いします。
$word はインターセプトされる文字列、$key_word は指定された部分文字列です
方法 1:
- PHP コード
<!-- Code highlighting produced by Actipro CodeHighlighter (freeware) http://www.CodeHighlighter.com/ --> mb_substr($word,strpos($word,$key_word)/3,100,'utf-8');
方法 2 :
- PHP コード
<!-- Code highlighting produced by Actipro CodeHighlighter (freeware) http://www.CodeHighlighter.com/ --> $start_key = mb_strpos($word,$key_word); $start_key = $start_key>0?$start_key:0; mb_substr($word,$start_key,100,'utf-8');
-----解決策-------
文字幅をインターセプトする非常に便利な関数 mb_strimwidth($str, 0, 80, '', 'utf8') を見つけました
------解決策----------------------
汗っかき、汗っかきな人コーディングを理解する 書かれたコードは本当に煩わしいものです。
覚えておいてください、strstr/strpos はバイトごとの比較に使用されます。 GBK/UTF8 の場合、GBK/UTF8 の非 ASCII 文字の 1 バイトの 7 番目のビットが 1 であるため、特定の状況下でも正常に動作しますが、GBK コードでは 2 つの 2 バイト文字が含まれるため問題が発生しやすくなります。バイトのスペルが不正確な一致を引き起こす可能性があります。
MB はエンコーディングを認識する関数であるため、渡される数値と返される数値はバイト数ではなく文字数です。
最初のコードで strpos を使用しましたが、utf8 エンコーディングが OK であれば、正直に言うと残りは機能しません。 UTF8 のことは忘れてください。文字はすべて 3 バイトであると仮定します。 。 。これは間違いです。
2 番目のコードははるかに信頼性が高くなりますが、mb_strpos にエンコーディングを指示しなかったのは残念なので、これで終わりです。
------解決策---------
mb_string 関数グループはこの方法では使用されません
mb_internal_encoding("utf-8");
mb_substr($word, mb_strpos($word, $key_word), 100);
------解決策---------
- PHP コード
//文字列インターセプト。すべての文字の長さは 1 で、gbk と utf-8 に共通です。
関数カット($str, $len = 12, $dot = '...') {
if (mb_strlen($str, "utf-8") 
ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7677
7677
 15
1393
52
1207
24
91
11
15
1393
52
1207
24
91
11

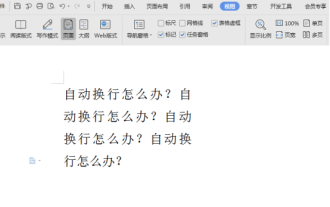 Wordの自動折り返しを解除する方法
Mar 19, 2024 pm 10:16 PM
Wordの自動折り返しを解除する方法
Mar 19, 2024 pm 10:16 PM
Word 文書のコンテンツを編集するときに、行が自動的に折り返されることがあります。この時点で調整を行わないと、編集に大きな影響があり、非常に頭を痛めることになります。何が起こっているのでしょうか?実は、これは定規の問題なのですが、以下ではワードの自動折り返しを解除する方法を紹介しますので、皆さんのお役に立てれば幸いです。 Word 文書を開いて文字を入力した後、コピーして貼り付けようとすると、文字が改行される場合があるため、この問題を解決するには設定を調整する必要があります。 2. この問題を解決するには、まずこの問題の原因を知る必要があります。ここでは、ツールバーの下にある [表示] をクリックします。 3. 次に、下の「ルーラー」オプションをクリックします。 4. この時点で、ドキュメントの上に定規が表示され、その上にいくつかの円錐形のマーカーが表示されます。
 Wordで定規を表示する方法と定規の操作方法を詳しく解説!
Mar 20, 2024 am 10:46 AM
Wordで定規を表示する方法と定規の操作方法を詳しく解説!
Mar 20, 2024 am 10:46 AM
Wordを使っていると、内容をより美しく編集するために定規を使うことが多いです。 Word のルーラーには、文書のページ余白、段落インデント、タブなどを表示および調整するために使用される水平ルーラーと垂直ルーラーが含まれていることを知っておく必要があります。では、Word で定規を表示するにはどうすればよいでしょうか。次にルーラー表示の設定方法を説明します。必要な学生はすぐに集めてください。 1. まず、ワードルーラーを表示します. デフォルトの Word 文書にはワードルーラーが表示されません. Word の [表示] ボタンをクリックするだけです。 2. 次に、[ルーラー]のオプションを見つけてチェックを入れます。このようにしてワードルーラーを調整することができます!はい、もしくは、いいえ
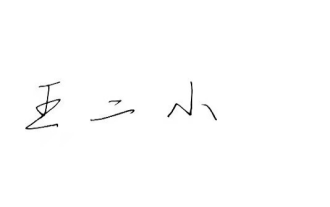 Word文書に手書きの署名を追加する方法
Mar 20, 2024 pm 08:56 PM
Word文書に手書きの署名を追加する方法
Mar 20, 2024 pm 08:56 PM
Word 文書はその強力な機能により広く使用されており、図や表などさまざまな形式を Word に挿入できるだけでなく、ファイルの完全性と信頼性を確保するために、多くのファイルの最後に手動で署名する必要があります。複雑な問題を解決するにはどうすればよいですか? 今日は、Word 文書に手書きの署名を追加する方法を説明します。スキャナー、カメラ、または携帯電話を使用して手書きの署名をスキャンまたは撮影し、PS またはその他の画像編集ソフトウェアを使用して画像に必要なトリミングを実行します。 2. 手書き署名を挿入したい Word 文書で「挿入 - 画像 - ファイルから」を選択し、切り取られた手書き署名を選択します。 3. 手書き署名の画像をダブルクリック(または画像を右クリックして「画像形式の設定」を選択)すると、「画像形式の設定」がポップアップ表示されます。
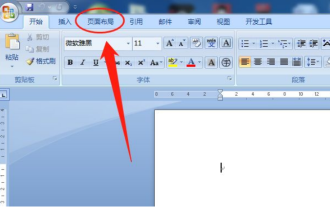 Wordのページ余白を設定する方法
Mar 19, 2024 pm 10:00 PM
Wordのページ余白を設定する方法
Mar 19, 2024 pm 10:00 PM
オフィスソフトの中でもWordは最もよく使われているソフトです。私たちが制作するテキスト文書は基本的にWordで操作します。必要に応じて紙で提出する必要がある文書もあります。印刷する前にレイアウトを設定してから提示する必要があります」 . より良い結果が得られます。そこで質問は、Word でページの余白をどのように設定するかということです。あなたの疑問を解決するために、具体的なコースの説明があります。 1. Word 文書を開くか、新しい Word 文書を作成し、メニュー バーの [ページ レイアウト] メニューをクリックします。 2. 「ページ設定」オプションの「余白」ボタンをクリックします。 3. リストから一般的に使用されるページ余白を選択します。 4. リストに適切なマージンがない場合は、[カスタム マージン] をクリックします。 5. 「ページ設定」ダイアログボックスが表示されるので、「余白」オプションをそれぞれ入力します。
 Wordで点線を引く方法
Mar 19, 2024 pm 10:25 PM
Wordで点線を引く方法
Mar 19, 2024 pm 10:25 PM
Wordはオフィスでよく使っているソフトで、大きな記事の場合、中の検索機能を使って全文中の単語が間違っていることを見つけたり、一つ一つ変更していき、上司に提出する際に文書を美化して見栄えを良くするなど、以下に編集者が点線の描き方の手順を紹介します。 Wordのline. 一緒に学びましょう! 1. まず、下図に示すように、コンピューター上で Word 文書を開きます。 2. 次に、下図の赤い丸で示すように、文書にテキスト文字列を入力します。 3. 次に、 と を押します。 [ctrl+A] を押しながら、下図の赤丸で示したテキストをすべて選択します。 4. メニューバー上部の [開始] をクリックします。
 Wordの網掛け設定はどこにあるのでしょうか?
Mar 20, 2024 am 08:16 AM
Wordの網掛け設定はどこにあるのでしょうか?
Mar 20, 2024 am 08:16 AM
オフィスワークなどでワードを使うことが多いですが、ワードの網掛けの設定がどこにあるのかご存知ですか?今日は具体的な操作手順を紹介しますので、ぜひ見てください。 1. まず、Word文書を開き、網掛けを追加する必要があるテキスト段落情報の段落を選択し、ツールバーの[開始]ボタンをクリックし、段落領域を見つけて、右側のドロップダウンボタンをクリックします(下図の赤丸で示すように))。 2. ドロップダウン ボックス ボタンをクリックした後、ポップアップ メニュー オプションで [境界線と網掛け] オプションをクリックします (下図の赤丸で示されているように)。 3. [境界線と網かけ]ダイアログボックスが表示されるので、[網かけ]オプションをクリックします(下図の赤丸部分)。 4. 塗りつぶされた列で色を選択します
 Wordで下矢印を削除する具体的な手順!
Mar 19, 2024 pm 08:50 PM
Wordで下矢印を削除する具体的な手順!
Mar 19, 2024 pm 08:50 PM
日常のオフィスワークで、Webサイトの文章をコピーしてWordに直接貼り付けると、[下矢印]が表示されることがありますが、この[下矢印]は選択することで削除できますが、数が多すぎると[下矢印]が表示されます。では、すべての矢印を簡単に削除する方法はあるのでしょうか?そこで今回はWordの下向き矢印を削除する具体的な手順を紹介します!まず、Wordの[下矢印]は、実は[手動改行]を表しています。以下の図に示すように、すべての [下矢印] を [段落マーク] 記号に置き換えることができます。 2. 次に、メニュー バーの [検索と置換] オプションを選択します (下図の赤丸で示されています)。 3. [置換]コマンドをクリックすると、ポップアップボックスが表示されるので、[特殊記号]をクリックします。
 Wordで表を描く方法
Mar 19, 2024 pm 11:50 PM
Wordで表を描く方法
Mar 19, 2024 pm 11:50 PM
Word は非常に強力なオフィスソフトであり、WPS に比べて詳細な処理に優れており、特に文書の記述が複雑な場合には Word を使用した方が一般的には安心です。そのため、社会に出たらワードの使い方のコツを学ばなければなりません。以前、いとこからこんな質問をされましたが、Wordを使っていると他の人が表を描いているのをよく見かけますが、とてもレベルの高いものを感じます。高度な内容に見えましたが、実際に操作するのはたったの3ステップでした Wordで表を描く方法をご存知ですか? 1. Word を開き、表を挿入する場所を選択し、上部のメニュー バーにある [挿入] オプションを見つけます。 2. 「テーブル」オプションをクリックすると、密集した小さな立方体が表示されます。
