

PHP の学習: 文字列操作と正規表現

メインコンテンツ:
- 文字列の書式設定;
- 文字列関数を使用して文字列を連結および分離します。
- 文字列比較;
- 文字列関数を使用して部分文字列の一致と置換を行います。
- 正規表現を使用します。
文字列の書式設定
1、スペースを削除します:trim()、ltrim()、rtrim()
trim() 関数は、先頭と末尾のスペースを削除します。
ltrim() 関数は先頭のスペースを削除します。
rtrim() 関数は末尾のスペースを削除します。
2、フォーマット文字列: printf()、sprintf()
printf() 関数と sprintf() 関数は echo と同じ機能を持ち、文字列を出力します。ただし、より複雑な形式 (C# の string.Format() と同様) を実装できます。
printf() と sprintf() のプロトタイプは次のとおりです:
string sprintf(string format[,mixed args..]); void printf(string format[,mixed args...]);ログイン後にコピーsprintf() はフォーマットされた文字列を返します。そして、printf は結果を直接出力します。 2 つの関数は似ているため、例として printf() が使用されます。
$boy = "boy"; echo "i am a $boy"; echo '<br />'; printf("i am a %s",$boy);ログイン後にコピー上記の出力結果は同じです。
形式のタイプは次のとおりです:
フォーマット内のすべての変換タイプは % で始まります。 「%」記号を出力したい場合は、「%%」を 2 つ使用する必要があります
3、文字列内の文字の大文字と小文字を変更します
a) 文字を大文字に変換します: strtoupper()
$str = "i am a boy"; echo strtoupper($str);ログイン後にコピーb) 文字を小文字に変換します: strto lower()
$str = "I Am A Boy"; echo strtolower($str);ログイン後にコピーc) 最初の文字が文字の場合は、ucfirst()
のように大文字に変換します。$str = "i am a boy"; echo ucfirst($str);ログイン後にコピーd) 文字列内の各単語の最初の文字を大文字に変換します: ucwords()
$str = "i am a boy"; echo ucwords($str);ログイン後にコピー4、エスケープ文字列
addslashes() 関数は、「に」を変換したり、二重スラッシュに変換したりするためのものです。
$str = '"i am a [\] boy."'; echo addslashes($str);ログイン後にコピー出力: 「私は [\] の男の子です。」
addslashes() 関数の反対の関数は、stripslashes() です。
5、エンコードされた文字列
htmlspecialchars() 関数は、&、<,>、" などをブラウザーが解釈できない文字にエンコードします。

文字列関数を使用して文字列を連結および分離する
1、区切り文字列:explode()
そのプロトタイプは次のとおりです:
array explode(string separator,string input[,int limit]);ログイン後にコピー配列が返されたことがわかります。次のように使用します:
$str = "1,2,3,4,5"; $arr = explode(',',$str); foreach($arr as $v){ echo $v.'<br />'; }ログイン後にコピー1 2 3 4 5 を返す<🎜>
分離があるから統合も起こります。はい、implode() 関数と join() 関数の実装は、explode() の逆の操作です。
2、インターセプト文字列: substr()$str = "1,2,3,4,5"; $arr = explode(',',$str); echo implode(',',$arr);ログイン後にコピーsubstr() 関数のプロトタイプは次のとおりです:
2 番目のパラメータはインターセプトの開始位置を示します。string substr(string input,int start[,int length]);ログイン後にコピー3 番目のパラメータは、インターセプトされた長さを表します。
次のように使用します:
出力: 私は男の子です$str = "i am a boy"; echo substr($str,2);ログイン後にコピー2 番目のパラメータと 3 番目のパラメータが負の場合は、後ろから開始することを意味することに注意してください。
function reverse_i($str){ for($i=1;$i<=strlen($str);$i++){ echo substr($str,-$i,1); } return; } reverse_i('word');ログイン後にコピー返回:drow;
字符串比较
1,字符串排序:strcmp(),strcasecmp(),strnatcmp()
strcmp()的原型如下:
int strcmp(string str1,string str2);ログイン後にコピー如果两个字符串相等,返回0;如果按字典顺序str1在str2后面就返回一个正数,反之。这个函数是区分大小写的。
$str1 = "2"; $str2 = "12"; echo strcmp($str1,$str2);ログイン後にコピー返回1,说明它是按字典顺序排列的,$str1的第一个字符大于$str2的第一个字符。
strcasecmp()函数除了不区分大小写之外,其他和strcmp()函数一样。
而strnatcmp()则是按照人们习惯的顺序进行排序。它也不区分大小写。
$str1 = "2"; $str2 = "12"; echo strnatcmp($str1,$str2);ログイン後にコピー返回-1,说明12比2大。
2,获得字符串的长度:strlen()
strlen(“hello”),输出结果为5。
使用字符串函数匹配和替换子字符串
1,在字符串中查找字符串:strstr(),strchr(),strrchr()和strissr()
这些函数看起来张得差不多,真是难记啊!~~
最常用的是strstr()函数,strchr()函数和strstr()函数时一样的,虽然感觉strchr()是查找一个字符的意思。
strstr()函数的原型如下:
string strstr(string haystack,string needle);ログイン後にコピー第一个参数为整个字符串。ログイン後にコピー第二个参数为需要查找的子字符串。
如果找到一个匹配,函数会从needle前面返回haystack,否则返回false。如果存在不止一个needle,返回的字符串从出现第一个needle的位置开始。
a).一个精确匹配
$str1 = "To all, I am very sad to tell you that I’ve just been fired.It has been my pleasure to work with all of you and I wish you only the best going forward."; echo strstr($str1,'very');ログイン後にコピー输出:very sad to tell you that I’ve just been fired.It has been my pleasure to work with all of you and I wish you only the best going forward.
b).多个匹配
$str1 = "To all, I am very sad to tell you that I’ve just been fired.It has been my pleasure to work with all of you and I wish you only the best going forward"; echo strstr($str1,'been');ログイン後にコピー输出:been fired.It has been my pleasure to work with all of you and I wish you only the best going forward.
函数strstr()有两个变体。第一个是stristr()函数,它几乎和strstr()函数一样,但区别就是不区分大小写。
第二个是strrchr()函数,它几乎和strstr()一样,但会从最后出现needle的位置的前面返回字符串haystack。
此函数第二个参数为字符。
输出:ward.$str1 = "To all, I am very sad to tell you that I’ve just been fired.It has been my pleasure to work with all of you and I wish you only the best going forward."; echo strrchr($str1,'w');ログイン後にコピー2,查找字符串的位置:strpos(),strrpos()
strpos()函数和strstr()函数的操作类似。但它不是返回一个字符串,而是返回子字符串在整个字符串中的位置。我们平常使用的也是这个。而且比strstr()速度也快。
strpos()函数原型如下:
int strpos(string haystack,string needle,int offset);ログイン後にコピー第三个参数是可选的,标示开始搜索的位置。
$str1 = "hello word"; echo strpos($str1,'o');ログイン後にコピー输出:4,位置是从0开始起。也可以用子字符串,这里只是出于演示目的。
$str1 = "hello word"; echo strpos($str1,'o',5);ログイン後にコピー输出:7。是从位置5开始搜索,也就看不到位置4的那个“o”了。
函数strrpos()也几乎一样,但返回的是子字符串在整个字符串中最后一次出现的位置。
$str1 = "hello word"; echo strrpos($str1,'o');ログイン後にコピー输出:7。说明“o”在hello word中最后一个位置的7。
这里需要注意一下,PHP中的false等于0,如果strpos()或者strrpos()都返回false(没有找到)或者在第一个字符就找到了(第一个字符的起始位置是0),
那么就区分不出来是找到,还是未找到了。那怎么办呢?只能用“===”恒等式来避免这个问题了。
$str1 = "hello word"; $position = strrpos($str1,'h'); //第一个字符就找到了,$position ==0 if($position === false){ echo '没有找到'; }else{ echo $position; }ログイン後にコピー3,替换子字符串:str_replace(),substr_replace()
str_replace()函数的原型如下:
mixed str_replace(mixed needle,mixed new_needle,mixed haystack[,int &count]);ログイン後にコピー第三个参数是可选的。它包含了要执行的替换操作次数。
返回替换过的字符串。
$str1 = "hello word"; echo str_replace('word','china',$str1);ログイン後にコピー输出:hello china
函数substr_replace()则用来在给定位置中查找和替换字符串中特定的子字符串。原型如下:
string substr_replace(string string,string replacement,int start[,int length]);ログイン後にコピー这个函数使用字符串replacement替换整个字符串string中的一部分。具体是那一部分则取决于起始位置和可选参数length的值。
需要注意的是,start的值如果是0或者一个正值,就是从字符串开始计算偏移量;如果是一个负值,就从字符串末尾开始的一个偏移量。
使用正则表达式
1,查找子字符串:ereg(),eregi()
ereg()函数的原型如下:
int ereg(string pattern,string search,array [matches]);ログイン後にコピー在search字符串中查找正则为pattern的表达式,如果发现了与pattern的字表达式相匹配的字符串,这些字符串将会存储在数组matches中,每个数组元素对应一个子表达式。
函数eregi()函数除了不区分大小写外,其功能与ereg()一样。
$str1 = "xxx@gmail.com.cn"; if(!eregi('[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4}',$str1)){ echo '不是正确的Email'; }else{ echo '正确'; }ログイン後にコピー2,替换子字符串:ereg_replace(),eregi_replace()
于str_replace()函数一样,只不过这两个使用正则表达式当做参数。
ereg_replace()的原型如下:
string ereg_replace(string pattern,string replacement,string search);ログイン後にコピー$str1 = "123123@gmail.com.cn"; echo ereg_replace('[A-Z0-9._%+-]+@','**@',$str1);ログイン後にコピー输出:**@gmail.com.cn
函数eregi_replace除了不区分大小写外,其他与ereg_replace()相同。
3,分隔字符串:split()
函数split()的原型如下:
array split(string pattern,string search[,int max]);ログイン後にコピー第三个参数为可选,表示进入数组中的元素个数。
返回值是数组。
$str1 = "123123@gmail.com.cn"; $arr = split('\.|@',$str1); while(list($key,$value) = each($arr)){ echo '<br />'.$key.'--'.$value; }ログイン後にコピー输出:
0--123123
1--gmail
2--com
3--cnsplit()函数和explode()函数有点相似,前者是用正则表达式当做分隔符,后者是用字符串当做分隔符。参考:PHP与MySQL.WEB开发

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7677
7677
 15
1393
52
1207
24
91
11
15
1393
52
1207
24
91
11

 Huawei の公式プログラミング言語 Cangjie の入門チュートリアルがリリースされ、ユニバーサル バージョン SDK の入手方法が 1 つの記事で学べます。
Jun 25, 2024 am 08:05 AM
Huawei の公式プログラミング言語 Cangjie の入門チュートリアルがリリースされ、ユニバーサル バージョン SDK の入手方法が 1 つの記事で学べます。
Jun 25, 2024 am 08:05 AM
6月24日の当サイトのニュースによると、6月21日のHDC2024ファーウェイ開発者カンファレンスの基調講演で、ファーウェイ端末BGソフトウェア部門社長のGong Ti氏が、ファーウェイが自社開発したCangjieプログラミング言語を正式に発表した。この言語は 5 年間開発されており、現在開発者プレビューが利用可能です。ファーウェイの公式開発者ウェブサイトは、開発者がプログラミング言語を使い始めて理解しやすくするために、Cangjie プログラミング言語の公式入門チュートリアルビデオを公開しました。このチュートリアルでは、ユーザーが倉街を体験し、倉街を学び、倉街を応用することができます。これには、倉街言語を使用した円周率の推定、2024 年の各月の幹と枝のルールの計算、倉街言語で二分木を表現する N 通りの方法の確認、列挙の使用などがあります。代数計算を実装するタイプ、インターフェイスと拡張機能を使用した信号システム シミュレーション、Cangjie マクロを使用した新しい構文など。このサイトのチュートリアル アクセス アドレス: ht
 5年間の研究開発を経て、ファーウェイの次世代プログラミング言語「Cangjie」が正式にプレビューを開始
Jun 22, 2024 am 09:54 AM
5年間の研究開発を経て、ファーウェイの次世代プログラミング言語「Cangjie」が正式にプレビューを開始
Jun 22, 2024 am 09:54 AM
本サイトは6月21日、本日午後のHDC2024 Huawei Developer Conferenceで、Huawei Terminal BG Software部門のGong Ti社長がHuaweiが自社開発したCangjieプログラミング言語を正式に発表し、HarmonyOSNEXT Cangjie言語の開発者プレビュー版をリリースしたと報じた。ファーウェイがCangjieプログラミング言語を公的にリリースするのはこれが初めてである。 Gong Ti 氏は次のように述べています。「2019 年に、Cangjie プログラミング言語プロジェクトが Huawei で誕生しました。5 年間の研究開発の蓄積と多額の R&D 投資を経て、今日、ついに世界の開発者と出会うことができました。Cangjie プログラミング言語は、最新の言語機能、包括的なコンパイルの最適化、ランタイム実装を統合しています」すぐに使用できる IDE ツール チェーンのサポートにより、開発者にとって使いやすい開発エクスペリエンスと優れたプログラム パフォーマンスが実現します。「レポートによると、Cangjie プログラミング言語はあらゆるシナリオに対応するインテリジェンス ツールです。
 ファーウェイ、HarmonyOS NEXT Cangjie プログラミング言語開発者プレビュー ベータ募集を開始
Jun 22, 2024 am 04:07 AM
ファーウェイ、HarmonyOS NEXT Cangjie プログラミング言語開発者プレビュー ベータ募集を開始
Jun 22, 2024 am 04:07 AM
6月21日の当サイトのニュースによると、ファーウェイが自社開発した倉街プログラミング言語が本日正式に発表され、公式はHarmonyOSNEXT倉街言語開発者プレビューベータ募集の開始を発表した。このアップグレードは、開発者プレビュー バージョンへの早期導入アップグレードであり、開発者が倉街言語を使用して HarmonyOSNext アプリケーションを開発、デバッグ、実行するための倉街言語 SDK、開発者ガイド、および関連する DevEcoStudio プラグインを提供します。登録期間: 2024 年 6 月 21 日から 2024 年 10 月 21 日まで 応募要件: この HarmonyOSNEXT Cangjie 言語開発者プレビュー ベータ募集イベントは、次の開発者のみが参加できます: 1) Huawei Developer Alliance 認定資格を実名で取得していること。 2) H を完了していること。
 天津大学と北杭大学はファーウェイの「Cangjie」プロジェクトに深く関与しており、国産プログラミング言語をベースにした初のAIエージェントプログラミングフレームワーク「Cangqiong」を立ち上げた。
Jun 23, 2024 am 08:37 AM
天津大学と北杭大学はファーウェイの「Cangjie」プロジェクトに深く関与しており、国産プログラミング言語をベースにした初のAIエージェントプログラミングフレームワーク「Cangqiong」を立ち上げた。
Jun 23, 2024 am 08:37 AM
6月22日のこのサイトのニュースによると、ファーウェイは昨日、ファーウェイが自社開発したプログラミング言語Cangjieを世界中の開発者に紹介した。 Cangjie プログラミング言語が公に公開されるのはこれが初めてです。当サイトの問い合わせによると、ファーウェイの「蒼傑」の研究開発には天津大学と北京航空航天大学が深く関与していた。天津大学:倉街プログラミング言語コンパイラ 天津大学知能計算学部のソフトウェアエンジニアリングチームは、ファーウェイの倉街チームと協力して、倉街プログラミング言語コンパイラの品質保証研究に深く参加しました。報告によると、Cangjie コンパイラは、Cangjie プログラミング言語と共生する基本ソフトウェアです。 Cangjie プログラミング言語の準備段階では、それに匹敵する高品質のコンパイラが中心的な目標の 1 つになりました。 Cangjie プログラミング言語が進化するにつれて、Cangjie コンパイラは常にアップグレードおよび改善されています。過去5年間、天津大学
 ファーウェイが自社開発したCangjieプログラミング言語の公式Webサイトと開発ドキュメントがオンラインになり、Hongmengエコシステムに初めて統合される
Jun 22, 2024 am 03:10 AM
ファーウェイが自社開発したCangjieプログラミング言語の公式Webサイトと開発ドキュメントがオンラインになり、Hongmengエコシステムに初めて統合される
Jun 22, 2024 am 03:10 AM
6月21日のこのサイトのニュースによると、HDC2024 Huawei Developer Conferenceの前に、Huaweiが自社開発したCangjieプログラミング言語が正式に公開され、Cangjieの公式ウェブサイトがオンラインになりました。公式ウェブサイトの紹介文によると、Cangjie プログラミング言語は、「ネイティブ インテリジェンス、自然なオール シナリオ、高性能、強力なセキュリティ」に焦点を当てた、オール シナリオ インテリジェンスのための新世代プログラミング言語です。 Honmeng エコシステムに統合して、開発者に優れたプログラミング エクスペリエンスを提供します。このサイトに付属する公式 Web サイトでは、AgentDSL を組み込んだネイティブのインテリジェント プログラミング フレームワーク、自然言語とプログラミング言語の有機的な統合、マルチエージェントの連携、簡素化された記号表現、パターンの自由な組み合わせ、さまざまなインテリジェント アプリケーションの開発をサポート、と紹介されています。あらゆるシーンに対応する本質的に軽量でスケーラブルなランタイム、モジュラー階層設計により、メモリがどれほど小さくても、あらゆるシナリオのドメイン拡張に対応できます。
 ファーウェイの純血Hongmengエコシステムの最後のリンクです!自社開発のCangjieプログラミング言語がデビュー
Jun 21, 2024 pm 03:23 PM
ファーウェイの純血Hongmengエコシステムの最後のリンクです!自社開発のCangjieプログラミング言語がデビュー
Jun 21, 2024 pm 03:23 PM
6月21日のニュースによると、本日午後、Huawei Developer Conference 2024が正式に開幕するとのこと。 「純血Hongmeng」Harmony OS NEXTは当然のことながら最優先事項であるYu Chengdong氏が以前に明らかにした計画によれば、今日の午後にパブリックベータ版が正式に発表され、一般消費者も「純血Harmony」を試すことができるようになる。報道によると、最初にサポートされる携帯電話はMate60シリーズとPura70シリーズだという。 「純血のHongmeng」として、HarmonyOSNEXTが従来のLinuxカーネルとAOSP Androidオープンソースコードを削除し、スタック全体を社内で開発したことは注目に値します。 Sina Technologyの最新レポートによると、HuaweiはHongmengエコシステムの最後のリンクも完成し、世界での存在感を拡大する予定です。
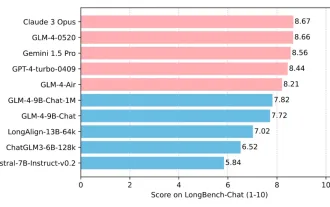 清華大学と Zhipu AI オープンソース GLM-4: 自然言語処理に新たな革命を起こす
Jun 12, 2024 pm 08:38 PM
清華大学と Zhipu AI オープンソース GLM-4: 自然言語処理に新たな革命を起こす
Jun 12, 2024 pm 08:38 PM
2023 年 3 月 14 日に ChatGLM-6B が発売されて以来、GLM シリーズ モデルは幅広い注目と認知を得てきました。特にChatGLM3-6Bがオープンソース化されてからは、Zhipu AIが投入する第4世代モデルに対する開発者の期待が高まっている。 GLM-4-9B のリリースにより、この期待はついに完全に満たされました。 GLM-4-9B の誕生 小型モデル (10B 以下) により強力な機能を提供するために、GLM 技術チームはこの新しい第 4 世代 GLM シリーズ オープン ソース モデル、GLM-4-9B をほぼ半年の期間を経て発売しました。探検。このモデルは、精度を確保しながらモデルサイズを大幅に圧縮し、推論速度の高速化と効率化を実現しています。 GLM 技術チームの調査はまだ終わっていない
 Mistral オープン ソース コード モデルが王位を獲得します。 Codestral は 80 を超える言語でのトレーニングに熱心に取り組んでおり、国内の Tongyi 開発者が参加を求めています。
Jun 08, 2024 pm 09:55 PM
Mistral オープン ソース コード モデルが王位を獲得します。 Codestral は 80 を超える言語でのトレーニングに熱心に取り組んでおり、国内の Tongyi 開発者が参加を求めています。
Jun 08, 2024 pm 09:55 PM
51CTO Technology Stack (WeChat ID: blog51cto) が制作、Mistral は最初のコードモデル Codestral-22B をリリースしました!このモデルのすごいところは、多くのコード モデルが無視する Swift などを含む 80 以上のプログラミング言語でトレーニングされていることだけではありません。それらの速度はまったく同じではありません。 Go言語を使用して「パブリッシュ/サブスクライブ」システムを記述する必要があります。ここでは GPT-4o が出力されており、Codestral は、見るのが難しいほど高速で論文を提出しています。発売されたばかりのモデルのため、まだ公的テストは行われていない。しかし、Mistral の担当者によると、Codestral は現在最もパフォーマンスの高いオープンソース コード モデルであるとのことです。写真に興味のある友達は次の場所に移動できます: - 顔を抱きしめる: https
