

少し前にDNSのドメイン名アクセスランキング(top100)を調べたいという依頼があり、仕方なくDNSログをゆっくり解析してみました。練習する。
1. 元のデータ分析:
まず、元のデータ ファイル、つまり DNS ログの内容を確認します。以下は、抽出されたいくつかの代表的なログです。2×8.2×1.2×.1×5 は、対応する数字であり、私は消去しました。それ。 。
13-08-30 03:11:34,229 情報: クエリ: – |1×3.2×8.2x.2×8|p19.qhimg.com|default|2×8.2×1.2x.1×5;|デフォルト;|A|成功|+|—w— qr aa rd ra |8061|
13-08-30 03:11:34,238 情報: クエリ: – |1×3.2×8.x.9x|shu.taobao.com|デフォルト|2×8.2×1.2x.1×5;|デフォルト;|A|成功|+|—w— qr aa rd ra |59034|
13-08-30 03:11:34,238 情報: クエリ: – |1×3.2×8.2×7.1×2|cncjn.phn.live.baofeng.net|デフォルト|2×8.2×1.2x.17x; |デフォルト;|A|成功|+|—w— qr aa rd ra |3004|
a) 区切り文字として | を使用します
b) 2 番目のフィールド ドメインはターゲット データであり、キー値、つまり辞書のキーとして使用します
c)domain[key] には、対応するドメイン名へのアクセス数が保存されます
2. スクリプトのアイデア:
a) DNS ログは一定の間隔で自動的に切り取られ、gz ファイルに圧縮されるため、最初に gzip.open を使用して gz ファイルを開き、ここで gz ライブラリをインポートする必要があります。
b) 要件は、一定期間のドメイン名ランキングを検索することであるため、一定期間フィルタリングする必要があります。ここでは通常の方法を使用してフィルタリングするため、通常のライブラリをインポートします。
c) ソート。結果はソートされ、topXX の結果が出力されます。それらは辞書に保存され、辞書はランダムであるため、適切なソート方法と辞書の反復項目が必要です。ちょうどいいです。
3. スクリプトの作成:
一般的なポイントを理解すれば、スクリプトを書くのは非常に簡単になります。
コードは次のとおりです:
スクリプトの内容について説明します。queries.log.CMN-CQ.20130830031330.gz は、主にドメイン フィールドをキーとして使用する、ドメイン[キー]を使用する特定のターゲット ファイルです。アクセス数を保存します。
その後、辞書の iteritems メソッドを呼び出して並べ替え用のイテレータを生成し、最後に上位 100 位のドメイン名を入力します。
最後の raw_input (「終了する単語を入力してください」) は、win7 でテストしたためです。デフォルトでは、この行は結果を観察するために追加されています。Linux では削除できます。
ここで少し厄介なのは、時間フィルタリングが通常のフィルタを使用するため、入力が通常である必要があり、面倒なことです。
3.
を実行します。長々と話してきたので、まずは簡単にその効果を見てみましょう。
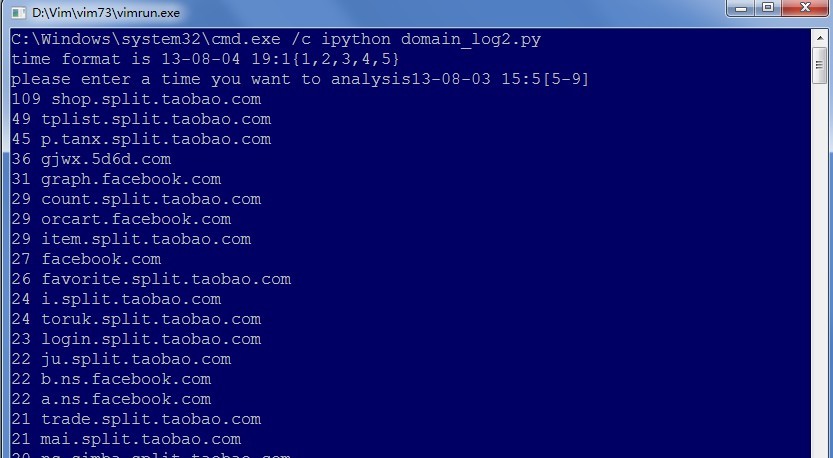
上位 20 位のドメイン名が正常に出力されていることがわかります。
4. 概要:
対応する要件は概ね達成されていますが、多くのファイルは適切に処理されません。たとえば、データ量が多い場合、定期的なフィルタリング期間を使用するとパフォーマンスに影響します。同時に、最終的な辞書の並べ替え方法をコピーした同僚に感謝します〜
。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



