

クローラーの作成には、PHP、Python、Node.js のどれが適していますか?

1. ページを解析する能力
2. データベース (mysql) を操作する能力
3. クローリング効率
4. コード量
言語を推奨する場合は、必要なクラス ライブラリまたはフレームワークを示してください。よろしくお願いします。 。
例: python+MySQLdb+urllib2+re
追記: 実際、私は Python を使用するのが好きではありません (おそらく Windows プラットフォーム上にあるため、さまざまな文字変換エンコーディングが必要で、マルチスレッドが機能しないようです) )
返信内容:
それは主に、「クローラー」として何を定義するかによって異なります。1. ターゲットを絞った方法で複数のページをクロールし、単純なページ解析を行う場合、クロールの効率は重要な要件ではありません。あまり違いはありませんか?
もちろん、ページ構造が複雑で、正規表現の記述が非常に複雑な場合、特に xpath をサポートするクラス ライブラリ/クローラー ライブラリを使用した後では、このメソッドは参入障壁が低いにもかかわらず、 、拡張性があり、保守性などが非常に悪いです。したがって、この場合は、xpath やマルチスレッドのサポートなどの要素を考慮する必要がある、既製のクローラー ライブラリを使用することをお勧めします。
2. 方向性クロールの場合、主な目的は js によって動的に生成されたコンテンツを解析することです
この時点で、ページのコンテンツは js/ によって動的に生成されます。 ajax では、通常のページをリクエストする方法を使用します -> 解析は機能しません。ページの JS コードを動的に解析するには、Firefox や Chrome ブラウザと同様の JS エンジンを使用する必要があります。
この場合、casperJS+phantomjs または SlimerJS+phantomjs を検討することをお勧めします。 もちろん、Selenium などの他のものも考慮できます。
3. クローラーに大規模な Web サイトのクローリングが含まれる場合、効率、拡張性、保守性などを考慮する必要があります
大規模なクローラーのクローリングには多くの問題が伴います。マルチスレッド同時実行、I/O機構、分散クローリング、メッセージ通信、重み判定機構、タスクスケジューリングなど。このとき、言語やフレームワークの選択は非常に重要です。
PHP はマルチスレッドと非同期使用のサポートが不十分であるため、お勧めできません。
NodeJS: 一部の縦型 Web サイトのクローリングには問題ありませんが、分散クローリングやメッセージ通信などのサポートが弱いため、状況に応じて判断する必要があります。
Python: 上記の問題を十分にサポートしているため、強くお勧めします。特に、Scrapy フレームワークは最初の選択肢となるに値します。多くの利点があります: クラスが独自の JS エンジンを作成します。
C と C++ は優れたパフォーマンスを持っていますが、特にコストなどの多くの要因を考慮すると、いくつかのオープンソース フレームワークに基づいて実行することをお勧めします。単純なクローラを作るのは簡単ですが、完全なクローラを作るのは難しいです。
私が構築した WeChat パブリック アカウント コンテンツ集約 Web サイトのような Web サイト
http://lewuxian.com はScrapy の動作に基づいており、もちろんメッセージ キューなども含まれます。以下の図を参照してください:
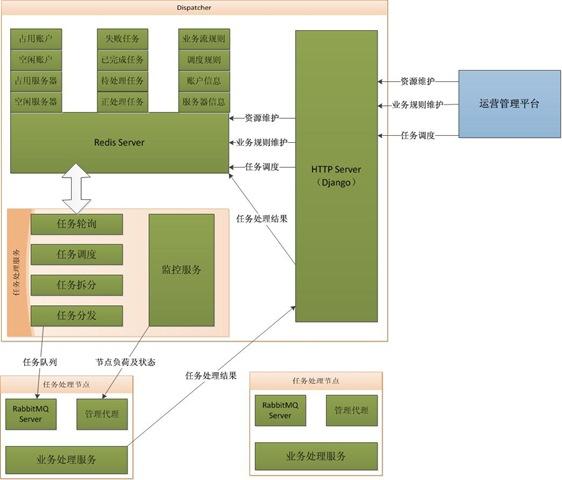
 特定の内容については、タスクのスケジューリングおよび配布サービスのアーキテクチャを参照してください
特定の内容については、タスクのスケジューリングおよび配布サービスのアーキテクチャを参照してください PHP については詳しくありませんが、Python と Node.js は使用したことがあります。
単純な方向性クロール:
Python + urlib2 + RegExp + bs4
または
Node.js + co、任意の dom フレームワークまたは html パーサー + Request + RegExp これも非常に便利です。
私にとって、上記 2 つのオプションはほぼ同等ですが、主に JS に慣れているため、今は Node プラットフォームを選択することになります。
大規模なサイト全体のクロール:
Python + Scrapy
上記 2 つのソリューションの DIY スパイダーが Xiaomi とライフルである場合、Scrapy は単なる強力な大砲です。カスタム クロール ルール、http エラー処理、XPath、RPC、パイプライン メカニズムなどは非常に使いやすいです。さらに、Scrapy は Twisted に基づいて実装されているため、効率が非常に優れていますが、唯一の欠点は、インストールが面倒で、依存関係が多いことです。
また、Spider に xpath を導入し、Chrome に xpath プラグインをインストールすると、解析パスが一目瞭然になり、開発効率が非常に高くなります。高い。 PHP と js はこれを行うように設計されていません。Python には比較的完全なフレームワークがありますが、私はそれを使用したことがないのでわかりません。ただし、Zhihu
にデータがあるため、nodejs を使用してそれについて話すことができます。 はノードを使用してキャプチャされます。
私と同じように、Windows で開発して Linux サーバーにデプロイする人はたくさんいると思います。現時点では、Nodejs には非常に顕著な利点があります。それは、展開が簡単で、プラットフォーム間でほぼバリアフリーであることです。それに比べて、Python は単純に耐え難いものです。
解析ページは、jQuery 構文と完全に互換性のある Cheerio を使用します。フロントエンドに慣れている場合は、非常に使いやすく、煩わしい通常のルールに対処する必要はもうありません。データベースを操作するだけで、mysql モジュールを直接使用するだけで、すべての機能が備わっています。
実際、Zhihu をクロールしているので、ストレス テストは行っていません。スレッドが増えると、帯域幅がボトルネックになります。さらに、真のマルチスレッドではなく、帯域幅が最終的にいっぱいになると (約数百スレッド、約 10MB/秒)、CPU は最低の linode の CPU にすぎません。構成ホスト。さらに、通常はスレッドとフェッチ間隔を制限しますが、これによりパフォーマンスはほとんど消費されません。
最後に、非同期プログラミングで最も厄介なのは、次のように複数行のキューを作成すると、コールバック地獄に陥ることです。実際の状況では、同期プログラミングに勝るものはありません。問題が多すぎます。 少しずつ答えていきましょう:
1. ページ解析能力
これに関しては、基本的に Web ページの解析を完了するために特定の言語のサードパーティ パッケージに依存しています。 HTML パーサーを自分で最初から実装したい場合、困難と時間の障害は非常に大きくなります。複雑な Web ページや、多数の Javascript 操作に基づいて生成されたリクエストの場合は、ブラウザ環境をスケジュールすることで完了できます。この点では、Python は完全に有能です。
2. データベース操作能力 (mysql)
データベース操作能力に関しては、Python には公式とサードパーティの接続ライブラリがあります。また、クローラで取得したデータについては、NoSQLデータベースに保存する方が個人的には適していると考えています。
3. クロール効率
確かにスクリプト言語の計算速度は高くありませんが、特定の Web サイトのクローラー対策メカニズムの強度と速度と比較すると、ネットワーク IO の速度は無視してください。ただし、それは開発者のレベルによって異なります。ネットワークリクエストを送信する待ち時間を他の処理(マルチスレッド、マルチプロセス、コルーチン)にうまく利用すれば、各言語の効率は問題になりません。
4. コード量
ご存知のように、Python コードは開発者のレベルが整っている限り、その単純さで有名です。疑似コードと同じくらい簡潔で理解しやすいものであり、コードの量は少なくなります。
言語を推奨する場合は、必要なクラス ライブラリまたはフレームワークを指定してください。ありがとうございます。
例: python+MySQLdb+urllib2+re
Python:requests + MongoDB + BeautifulSoup
追記: 実際、私は Python を使用するのが好きではありません (おそらく私がそうであるためです) Windows プラットフォームではさまざまな文字エンコーディングが必要で、マルチスレッドは役に立たないようです。)
GIL の存在により、Python のマルチスレッドはマルチコアを利用できません。この問題を解決するにはマルチプロセスを使用してください。ただし、クローラーの場合、ネットワーク IO の待機に多くの時間がかかるため、コルーチンを直接使用すると、クロール速度が大幅に向上します。
さらに、最近 Python でクローラーを作成した経験をコラムにまとめましたので、ご興味があればご覧ください。
コラムアドレス:
http://zhuanlan.zhihu.com/xlz-d Python を使用して HTML 内の有用なコンテンツをクロールして抽出します。この分野のライブラリは非常に便利で美しいスープとリクエストであるためです。
ノードを使用してデータベースに書き込みます。非同期メソッドでは、同期 IO の完了を待つ必要がなく、マルチスレッド ロックの問題も発生しません。現在、Node5.x はすでに ES6 をサポートしており、Promise を使用して複数のネストされたコールバック関数の問題を解決できます。
データのキャプチャと分析に php を使用することについては、忘れてください。 PHP Node.js Python を使用してクローリング スクリプトを作成しました。それについて簡単に説明しましょう。
初めての PHP。まず利点について説明します。オンラインでは HTML をクロールおよび解析するためのフレームワークが多数あり、さまざまなツールを直接使用できるため、より安心です。短所: まず第一に、速度/効率が問題です。かつて、映画のポスターをダウンロードしたときに、crontab が定期的に実行され、最適化が行われなかったことがあり、メモリを直接圧迫していました。文法も非常に遅く、キーワードや記号が多すぎて、簡潔さが足りず、書くのが非常に面倒です。
Node.js。利点は、ネットワークが非同期であるため、キャプチャされたデータの複雑な計算と処理がなければ、基本的にはメモリと CPU の使用量が非常に少ないことです。システムのボトルネック 基本的に、帯域幅と、MySQL などのデータベースへの書き込みの I/O 速度に依存します。もちろん、非同期ネットワークはメリットの逆にデメリットもあります。このとき、たとえばビジネス需要が線形の場合は、前のページの取得が完了するまで待ってからデータを取得する必要があります。次のページを取得すると、さらに多くのレイヤー依存関係が発生し、ひどいマルチレイヤー コールバックが発生します。基本的にこの時点では、コードの構造とロジックはめちゃくちゃになります。もちろん、ステップやその他のプロセス制御ツールを使用して、これらの問題を解決することもできます。
最後に、Python について話しましょう。効率性に対する極端な要件がない場合は、Python をお勧めします。まず、Python の構文は非常に簡潔であり、同じステートメントをキーボード上に何度も保存できます。そして、Pythonは関数パラメータのパッケージ化やアンパック、リスト分析、行列処理などのデータ処理に非常に適しており、非常に便利です。
私は最近、Python データ キャプチャおよび処理ツールキットも作成しました。これは現在も修正および改良中です。スター: yangjiePro/cutout - GitHub へようこそ。 Pythonにはscapyというクロール専用のフレームワークがあります PHP でcurl を使用して、携帯電話認証コード プラットフォームの番号を取得します
curl を使用して Caoliu ページをクロールし、画像を自動的にダウンロードします
まあ、私は Caoliu が好きです, 私はまだ Python を読んでいますが、個人的には Python は本当に強力だと思っているので、将来的には間違いなく nodejs を検討します
ああ、PHP はマルチスレッドをサポートしていないので、それを行うにはサーバーか拡張機能を使用するしかありません。マブ、もうやり方がわからない....
忘れて、何が起こるか見てみましょう... Python を使用することをお勧めします。マルチスレッド機能が非常に優れています。
私は Python を使用して 8 つの主要な音楽 Web サイトのクローラーを作成したことがありますので、自信を持って推奨できます。 私は PHP と Python を使用してクローラーを作成したことがありますが、JS でクローラーを作成したことは見たことがなく、Node.js についても知りません。
PHP でクローラーを作成し、PHP コマンドラインで実行しても問題ありません。 Curl_multi 50 スレッドを同時に使用すると、ネットワーク速度に応じて 1 日あたり約 600,000 ページをキャプチャできます。キャンパス ネットワークを使用しているため、データは正規表現を使用して抽出されます。
Curl は比較的成熟したライブラリです。例外処理、http ヘッダー、POST などで優れた機能を果たします。重要なことは、ウェアハウス操作のために PHP で MySQL を操作する方が安心であるということです。
しかし、マルチスレッド Curl (Curl_multi) に関しては、初心者にとってはさらに面倒になるでしょう。特に PHP の公式ドキュメントにおける Curl_multi の紹介は非常に曖昧です。
Python でクローラーを作成する最大の利点の 1 つは、Requests などのライブラリは機能的には Curl と同等ですが、単純なクローラーを実行するだけの場合は、より簡単であることです。 Beautiful Soup このような愚かなライブラリは、確かにクローラーに非常に適しています。
しかし、初心者にとってコーディングは確かに頭の痛い問題かもしれません。実際、チームで必要でなければ、私はすべてのクローラーを PHP で書くと思います。
パフォーマンスはさておき、JavaScript は仮想マシンの中の仮想マシンのようなものだと思います。Node.js 使ったことはありません。
- 最初はサンドボックスで実行されます。 はネイティブ インターフェイスがないため、データベースやローカル ファイルを操作するのが難しくなります。これをクローラーとして使用しており、他のソリューションを調査していません。
DOM ツリー解析では、- が比較的効率が悪い に加えて、 も多くのメモリを消費します 。
クロスドメインの場合は、Chrome の --disable-web-security で無効化できますが、やはり面倒です。
要するに、JS でクローラを書こうとすると、非常に苦労することになります。
これを使ってクローラーを書いている人を見たことがありません。
1. ページ解析機能には基本的に違いはありません。ただし、Python には、より便利な拡張機能がいくつかあります。2. , PHP は MySQL よりも優れた機能を備えており、Python は MySQLdb などのライブラリを追加する必要がありますが、それほど面倒ではありません。
3. クロール効率の点では、どちらもマルチスレッドをサポートしています。基本的に、ボトルネックはネットワーク上にあります。しかし、厳密なテストは行っていないので、同じ機能を複数の言語で実装する習慣がありません。しかし、PHP の方が速いような気がします。
4. コードの量に関しては、数十行の例外処理を追加する場合でも、必要な作業は 100 行だけです。例外をトラブルシューティングしてマークダウンし、後で再度クロールするなどです。処理はわずか数百行であり、誰にとっても違いはありません。
しかし、lib が含まれていない場合、Python は明らかに最低です。
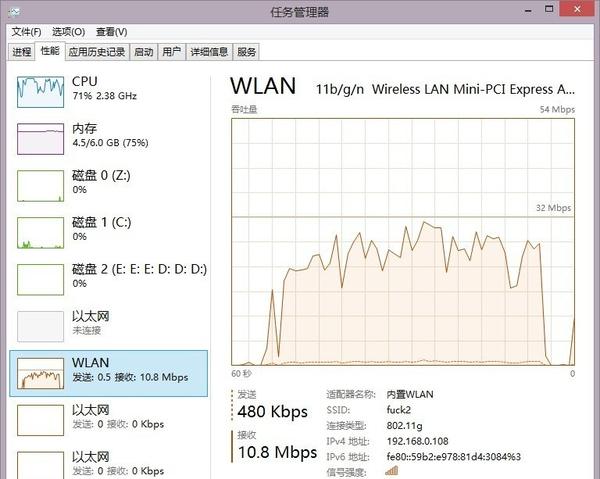 パフォーマンスに関して言えば、クローラーとパフォーマンスは基本的に無関係であり、考慮する必要のないものです 。クローラーを開始すると、クローラー効率はほぼ 30Mbps でしたが、PHP コマンド ラインで作成されたクローラーは CPU の 3 ~ 5% を占有するだけで、メモリは約 15 ~ 20MiB 消費しました (Core 2 Duo P8700 - ある程度の歴史のある古い U)はい、クローラには 50 のスレッドがあり、各スレッドには 10 の通常の抽出、1 の JSON 解析、2 のデータベース挿入操作 (数百万のデータに対する IF NOT EXIST)、および約 40 のさまざまな例外判定が含まれます)—ボトルネックネットワークのみである必要があります。 G ポートを持っていない場合は、パフォーマンスについて心配する必要はありません。どれを選択しても同じです。
パフォーマンスに関して言えば、クローラーとパフォーマンスは基本的に無関係であり、考慮する必要のないものです 。クローラーを開始すると、クローラー効率はほぼ 30Mbps でしたが、PHP コマンド ラインで作成されたクローラーは CPU の 3 ~ 5% を占有するだけで、メモリは約 15 ~ 20MiB 消費しました (Core 2 Duo P8700 - ある程度の歴史のある古い U)はい、クローラには 50 のスレッドがあり、各スレッドには 10 の通常の抽出、1 の JSON 解析、2 のデータベース挿入操作 (数百万のデータに対する IF NOT EXIST)、および約 40 のさまざまな例外判定が含まれます)—ボトルネックネットワークのみである必要があります。 G ポートを持っていない場合は、パフォーマンスについて心配する必要はありません。どれを選択しても同じです。 クローラーを実行した数日間で、約 270GiB のデータをクロールしました。
クローラーを実行した数日間で、約 270GiB のデータをクロールしました。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7455
7455
 15
1375
52
77
11
14
9
15
1375
52
77
11
14
9

 NAVICATでデータベースパスワードを取得できますか?
Apr 08, 2025 pm 09:51 PM
NAVICATでデータベースパスワードを取得できますか?
Apr 08, 2025 pm 09:51 PM
NAVICAT自体はデータベースパスワードを保存せず、暗号化されたパスワードのみを取得できます。解決策:1。パスワードマネージャーを確認します。 2。NAVICATの「パスワードを記憶する」機能を確認します。 3.データベースパスワードをリセットします。 4.データベース管理者に連絡してください。
 MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQLは、インストールが簡単で、強力で管理しやすいため、初心者に適しています。 1.さまざまなオペレーティングシステムに適した、単純なインストールと構成。 2。データベースとテーブルの作成、挿入、クエリ、更新、削除などの基本操作をサポートします。 3.参加オペレーションやサブクエリなどの高度な機能を提供します。 4.インデックス、クエリの最適化、テーブルパーティション化により、パフォーマンスを改善できます。 5。データのセキュリティと一貫性を確保するために、バックアップ、リカバリ、セキュリティ対策をサポートします。
 MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
Hash値として保存されているため、Navicatを介してMongoDBパスワードを直接表示することは不可能です。紛失したパスワードを取得する方法:1。パスワードのリセット。 2。構成ファイルを確認します(ハッシュ値が含まれる場合があります)。 3.コードを確認します(パスワードをハードコードできます)。
 NAVICATは、MySQL/Mariadb/PostgreSQLおよびその他のデータベースに接続できません
Apr 08, 2025 pm 11:00 PM
NAVICATは、MySQL/Mariadb/PostgreSQLおよびその他のデータベースに接続できません
Apr 08, 2025 pm 11:00 PM
NAVICATがデータベースとそのソリューションに接続できない一般的な理由:1。サーバーの実行ステータスを確認します。 2。接続情報を確認します。 3.ファイアウォール設定を調整します。 4.リモートアクセスを構成します。 5.ネットワークの問題のトラブルシューティング。 6.許可を確認します。 7.バージョンの互換性を確保します。 8。他の可能性のトラブルシューティング。
 Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
NAVICATプレミアムを使用してデータベースを作成します。データベースサーバーに接続し、接続パラメーターを入力します。サーバーを右クリックして、[データベースの作成]を選択します。新しいデータベースの名前と指定された文字セットと照合を入力します。新しいデータベースに接続し、オブジェクトブラウザにテーブルを作成します。テーブルを右クリックして、データを挿入してデータを挿入します。
 Navicatは、データベースエラーコードとソリューションに接続します
Apr 08, 2025 pm 11:06 PM
Navicatは、データベースエラーコードとソリューションに接続します
Apr 08, 2025 pm 11:06 PM
データベースに接続するときの一般的なエラーとソリューション:ユーザー名またはパスワード(エラー1045)ファイアウォールブロック接続(エラー2003)接続タイムアウト(エラー10060)ソケット接続を使用できません(エラー1042)SSL接続エラー(エラー10055)接続の試みが多すぎると、ホストがブロックされます(エラー1129)データベースは存在しません(エラー1049)
 NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
手順に従って、NAVICATで新しいMySQL接続を作成できます。アプリケーションを開き、新しい接続(CTRL N)を選択します。接続タイプとして「mysql」を選択します。ホスト名/IPアドレス、ポート、ユーザー名、およびパスワードを入力します。 (オプション)Advanced Optionsを構成します。接続を保存して、接続名を入力します。
 Navicatでテーブルノートを表示する方法
Apr 09, 2025 am 06:00 AM
Navicatでテーブルノートを表示する方法
Apr 09, 2025 am 06:00 AM
NAVICATでテーブルノートを表示する方法:データベースに接続し、ターゲットテーブルに移動します。 [メモ]タブに切り替えます。テーブルノートがあるかどうかを確認してください。
