

mysqlで同じフィールドデータを持つ2つのレコードを削除するにはどうすればよいですか?

たとえば、name 列と eamil 列があり、データベースにレコードが存在する場合、これら 2 つの列の値は同じです (これに対応する 2 つの列の値について話しています)値が同じである場合、他の冗長な列は自動的に削除され、最新の列 (つまり、ID が最も小さい列) が保持されます。 ID は自動インクリメントされる主キーです)
———————————————— ————
つまり、テーブルにはその名前のレコードが 2 つあります。どちらも管理者で、メールアドレスは abc@163.com です。どちらか一方だけを保持したいのですが、どうすればよいですか?
返信内容:
実際に英語で検索してみると。スタック オーバーフローに関する関連情報は簡単に見つかります。本当に CS を学びたい場合は、Baidu を使用しないでください。SQL を投稿するだけで、別の世界が見つかります。
アイデアの 1 つについてお話しましょう (良い答えがたくさんあります。自分で調べてください)
それは、グループを作成して保持することです。最大の ID を持つもの (自動インクリメントと言いました。最大の ID を持つものが最新である必要があります)
特定の SQL クエリは次のように記述できます
<span class="k">delete</span> <span class="k">from</span> <span class="n">test</span> <span class="k">where</span> <span class="n">id</span> <span class="k">not</span> <span class="k">in</span><span class="p">(</span> <span class="k">select</span> <span class="n">name</span><span class="p">,</span><span class="n">email</span><span class="p">,</span><span class="k">max</span><span class="p">(</span><span class="n">id</span><span class="p">)</span> <span class="k">from</span> <span class="n">test</span> <span class="k">group</span> <span class="k">by</span> <span class="n">name</span><span class="p">,</span><span class="n">email</span> <span class="k">having</span> <span class="n">id</span> <span class="k">is</span> <span class="k">not</span> <span class="k">null</span><span class="p">)</span>
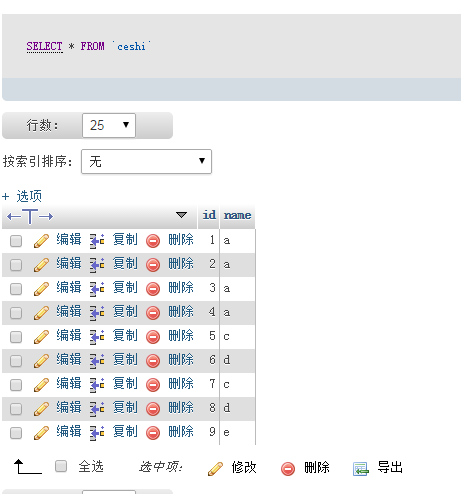
 Execute sql:select count(*) as count ,name,id from ceshi group by name
Execute sql:select count(*) as count ,name,id from ceshi group by name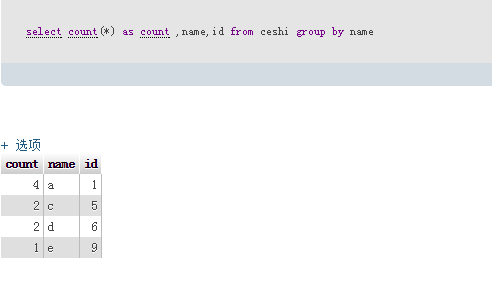 削除される最後の SQL SQL は次のとおりです: ID が入っていない ceshi から削除 (名前で ceshi グループから count ,name,id として count(*) を選択)
削除される最後の SQL SQL は次のとおりです: ID が入っていない ceshi から削除 (名前で ceshi グループから count ,name,id として count(*) を選択)最大値を保持したい場合id の値:
簡単な方法は次のとおりです。id が含まれていない ceshi から削除します (count (*) を count ,name,id から選択します (select * from ceshi order by id desc) group by name) 明確な 実際には非常に簡単で、テーブルを 2 つのテーブルとして扱うだけです。
DELETE p1 from TABLE p1, TABLE p2 WHERE p1.name = p2.name AND p1.email = p2.email AND p1.id
ここに質問があります、質問者はこう言いました。最新のものを保持する どれ(つまりIDが小さいもの)が増えているので、最新のものを一番大きくすればいいのではないでしょうか?
上記のステートメントでは、p1.id もちろん、group by, count を使用すると、n 回繰り返す状況をより正確に制御できます。ただし、元の投稿者のニーズに応じて、重複したものを削除し、最新のものを保持する必要があります。 DELETE FROM table WHERE id not in ( SELECT
tb.id FROM ( SELECT tmp.* FROM table tmp ) tb GROUP BY tb.field1, tb.field2,… );
table はテーブル名、field は必要な重複フィールドを削除します。 新しいテーブルを作成し、名前と電子メールを一意のインデックスとして設定し、古いテーブル データを再挿入します。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7448
7448
 15
1374
52
76
11
14
6
15
1374
52
76
11
14
6

 紅夢ネイティブアプリケーションのランダムな詩
Feb 19, 2024 pm 01:36 PM
紅夢ネイティブアプリケーションのランダムな詩
Feb 19, 2024 pm 01:36 PM
オープン ソースの詳細については、次のサイトを参照してください。 51CTO Honmeng 開発者コミュニティ https://ost.51cto.com 実行環境 DAYU200:4.0.10.16SDK: 4.0.10.15IDE: 4.0.600 1. アプリケーションを作成するには、[ファイル] をクリックします。 >新しいファイル ->プロジェクトの作成。テンプレートを選択します: [OpenHarmony] EmptyAbility: プロジェクト名 shici、アプリケーション パッケージ名 com.nut.shici、およびアプリケーションの保存場所 XXX (中国語、特殊文字、スペースは含まれません) を入力します。 CompileSDK10、モデル: ステージ。デバイス
 電子メール、smtplib、poplib、imaplib モジュールを使用して Python で電子メールを送受信する方法
May 16, 2023 pm 11:44 PM
電子メール、smtplib、poplib、imaplib モジュールを使用して Python で電子メールを送受信する方法
May 16, 2023 pm 11:44 PM
電子メールの流れは次のとおりです: MUA: MailUserAgent - メール ユーザー エージェント。 (つまり、Outlook に似た電子メール ソフトウェア) MTA: MailTransferAgent - メール転送エージェント。NetEase、Sina などの電子メール サービス プロバイダーです。 MDA: MailDeliverAgent - メール配信エージェント。電子メール サービス プロバイダーのサーバー sender->MUA->MTA->MTA->if
 comcn と com はどう違いますか?
May 12, 2023 pm 04:08 PM
comcn と com はどう違いますか?
May 12, 2023 pm 04:08 PM
comcn と com の違い: 1. comcn と com には意味の違いがありますが、アクセス速度に違いはありません; 2. comcn は国際ドメイン名であり、次のユーザーが使用するグローバル トップレベル ドメイン名です。商業機関、cn は中国企業のドメイン名、国内商業機関、国内ドメイン名、企業のみが登録可能; 3. 検索の優先順位は、cn が最初に .cn を検索することです。.cn サーバーが見つかった後、.cnサーバーは .com を検索します; 4. cn は cnnic China Internet Center Management によって提供されており、com の管理組織は海外にあります。
 php提交表单通过后,弹出的对话框怎样在当前页弹出,该如何解决
Jun 13, 2016 am 10:23 AM
php提交表单通过后,弹出的对话框怎样在当前页弹出,该如何解决
Jun 13, 2016 am 10:23 AM
php提交表单通过后,弹出的对话框怎样在当前页弹出php提交表单通过后,弹出的对话框怎样在当前页弹出而不是在空白页弹出?想实现这样的效果:而不是空白页弹出:------解决方案--------------------如果你的验证用PHP在后端,那么就用Ajax;仅供参考:HTML code
 Springboot 管理監視の役割と使用法は何ですか
May 25, 2023 pm 06:52 PM
Springboot 管理監視の役割と使用法は何ですか
May 25, 2023 pm 06:52 PM
該当するシナリオ: 1. プロジェクトの規模が大きくない 2. ユーザー数があまり多くなく、同時実行性の要件がそれほど強くない 3. 専任の運用保守要員が存在しない 4. チームの規模が絶妙である通常のプロジェクト、または企業の責任分担が明確ではない部門。多くの場合、システムは要件から設計、開発、テスト、そして最終的な立ち上げ、運用、保守へと進みます。多くの場合、タスクの 80% は開発チームによって完了されます。したがって、開発者はシステムの機能を実装するだけでなく、顧客の相談に応じ、質問に答え、生産上の問題を解決する必要もあります。想像してみてください。アプリケーションが起動された後は、監視手段が何もありません。ダッシュボードのない車を運転するのと同じように、このような道路では誰も安全を感じません。シンプルさと効率性のバランスをどう取るかは、考える価値のあることです。 1.スプリングブ
 このファイルを変更するには、管理者から提供されたアクセス許可が必要です。この問題を解決するにはどうすればよいですか?
Jul 26, 2023 am 10:56 AM
このファイルを変更するには、管理者から提供されたアクセス許可が必要です。この問題を解決するにはどうすればよいですか?
Jul 26, 2023 am 10:56 AM
このファイルを変更するには、管理者から提供されたアクセス許可が必要です。解決策: 1. ログイン インターフェイスで管理者アカウントを選択し、パスワードを入力すると、ファイルをスムーズに変更できます。2. ファイルを右クリックして、 「管理者として」の解決策: 3. ファイルのアクセス許可を変更し、ファイルを右クリックして「プロパティ」を選択し、「セキュリティ」タブをクリックして「編集」ボタンをクリックし、ユーザー名を選択して「フル コントロール」にチェックを入れます。オプション ; 4. コマンド プロンプトを使用して問題を解決します; 5. UA 権限を設定します。
 Flask-Admin を使用してバックグラウンド管理インターフェイスを実装する方法
Aug 03, 2023 pm 11:30 PM
Flask-Admin を使用してバックグラウンド管理インターフェイスを実装する方法
Aug 03, 2023 pm 11:30 PM
Flask-Admin を使用してバックエンド管理インターフェイスを実装する方法 背景の紹介: Web サイトやアプリケーションの開発に伴い、バックエンド管理インターフェイスの重要性がますます高まっています。開発プロセスでは、データ、ユーザー、その他の重要な情報を管理するために、便利で高速なバックエンド管理インターフェイスが必要になることがよくあります。 Flask-Admin は強力で使いやすい Flask 拡張機能で、バックグラウンド管理インターフェイスを迅速に実装するのに役立ちます。 Flask-Admin は、Flask と SQLAlchemy に基づいたオープンソース プロジェクトです。
 Win10 メールボックスに添付ファイルを挿入する方法のチュートリアル
Jan 07, 2024 pm 12:14 PM
Win10 メールボックスに添付ファイルを挿入する方法のチュートリアル
Jan 07, 2024 pm 12:14 PM
日常生活の中で仕事でメールを送信する必要があるユーザーは多く、コミュニケーションのためにさまざまなプラグイン素材を添付する必要があるユーザーもいます。以下の詳細なチュートリアルを見てみましょう。 Win10 メールボックスに添付ファイルを挿入する方法: 1. メールボックスを開きます。 2. 左上隅の「新規メール」アイコンをクリックします。 3. 右上隅にある「挿入」をクリックします。 4. 右上隅にある「添付ファイル」をクリックします。 . 必要な「添付ファイル」を選択します 6. 完了
