

1. はじめに
クローラーの予備調査とのことですが、実際にはクローラー関連のサードパーティライブラリは使用せず、主にnode.jsの基本モジュールhttpとWebページ解析ツールcherrioを使用しています。 httpを使用してURLパスに対応するWebページリソースを直接取得し、cherrioを使用して解析します。 ここでは、理解を深めるために私が研究した主なケースをタイプしました。コーディングプロセス中に、初めて forEach を使用して jq によって取得されたオブジェクトを直接走査し、エラーを直接報告しました。これは、jq には対応するメソッドがなく、js 配列しか呼び出すことができなかったためです。
2. 知識のポイント
①: Superagent は Web ページを取得するためのツールです。まだ使ったことがないんです。
②:cherrio Web解析ツール、構文は同じなのでサーバーサイドのjQueryと理解できます。
レンダリング
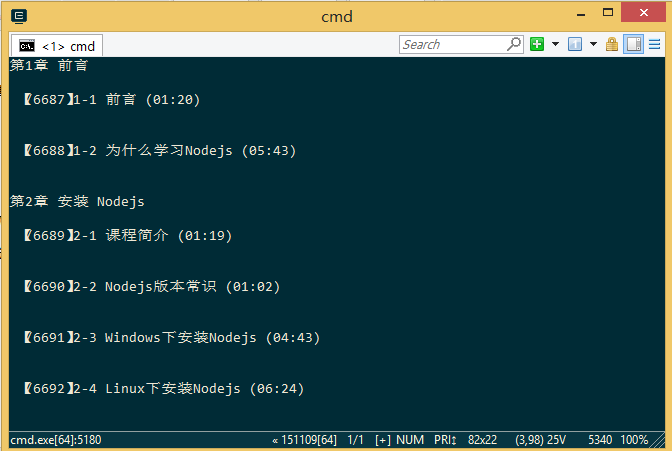
1. Web ページ全体をキャプチャします
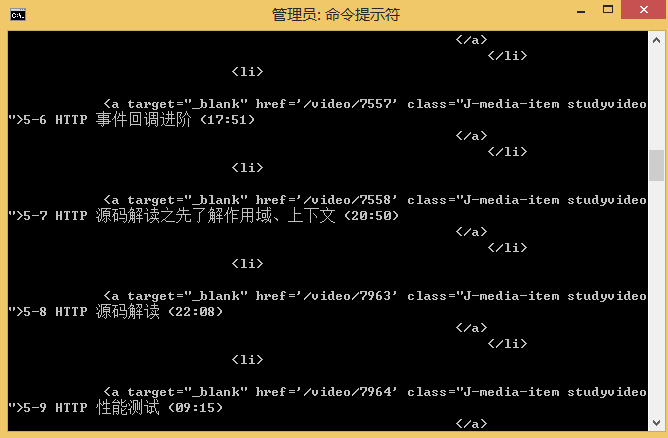
2. 分析データ、 提供されている例は実装例です。
クローラの初期ソースコード分析
var http=require('http');
var cheerio=require('cheerio');
var url='http://www.imooc.com/learn/348';
/****************************
打印得到的数据结构
[{
chapterTitle:'',
videos:[{
title:'',
id:''
}]
}]
********************************/
function printCourseInfo(courseData){
courseData.forEach(function(item){
var chapterTitle=item.chapterTitle;
console.log(chapterTitle+'\n');
item.videos.forEach(function(video){
console.log(' 【'+video.id+'】'+video.title+'\n');
})
});
}
/*************
分析从网页里抓取到的数据
**************/
function filterChapter(html){
var courseData=[];
var $=cheerio.load(html);
var chapters=$('.chapter');
chapters.each(function(item){
var chapter=$(this);
var chapterTitle=chapter.find('strong').text(); //找到章节标题
var videos=chapter.find('.video').children('li');
var chapterData={
chapterTitle:chapterTitle,
videos:[]
};
videos.each(function(item){
var video=$(this).find('.studyvideo');
var title=video.text();
var id=video.attr('href').split('/video')[1];
chapterData.videos.push({
title:title,
id:id
})
})
courseData.push(chapterData);
});
return courseData;
}
http.get(url,function(res){
var html='';
res.on('data',function(data){
html+=data;
})
res.on('end',function(){
var courseData=filterChapter(html);
printCourseInfo(courseData);
})
}).on('error',function(){
console.log('获取课程数据出错');
})
参考:
https://github.com/alotang/node-lessons/tree/master/lesson3
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



