

以前に書いた小さなクローラーは、現在では非常に不完全なように見えます。たとえば、Zhihu で質問をクリックしたときに、すべての回答が読み込まれるわけではありません。したがって、質問へのリクエスト リンクを直接送信すると、取得されるページは不完全になります。また、リンクを送信して画像をダウンロードする場合、画像が多すぎる場合は、スリープが終了した後でもダウンロードされます。また、nodejs を使用して作成したクローラーは、画像を 1 つずつダウンロードしません。 1 つは、nodejs の最も強力な非同期および同時実行機能が使用されないのは非常にもったいないことです。
想い
今回のクローラーは前回のクローラーのアップグレード版ですが、前回はシンプルでしたが、初心者が学ぶのに非常に適しています。今回のクローラーコードは私のgithub => NodeSpiderにあります。
クローラー全体の考え方は次のとおりです。最初に、リクエストの質問のリンクを通じてページ データの一部をクロールし、次にコード内で ajax リクエストをシミュレートして、そのデータをインターセプトしました。もちろん、残りのページは、小規模な非同期プロセス制御のために、ここで非同期的に実行することもできますが、ここでは使用しません。取得したページを分析することですべての画像のリンクを傍受し、非同期同時実行によりこれらの画像のバッチ ダウンロードを実装します。
ページの初期データをキャプチャするのは非常に簡単なので、ここではあまり説明しません
/*获取首屏所有图片链接*/
var getInitUrlList=function(){
request.get("https://www.zhihu.com/question/")
.end(function(err,res){
if(err){
console.log(err);
}else{
var $=cheerio.load(res.text);
var answerList=$(".zm-item-answer");
answerList.map(function(i,answer){
var images=$(answer).find('.zm-item-rich-text img');
images.map(function(i,image){
photos.push($(image).attr("src"));
});
});
console.log("已成功抓取"+photos.length+"张图片的链接");
getIAjaxUrlList();
}
});
} Ajax リクエストをシミュレートして完全なページを取得します
次のステップは、クリックしてさらにロードするときに発行される ajax リクエストをシミュレートする方法です。Zhihu にアクセスして見てください。
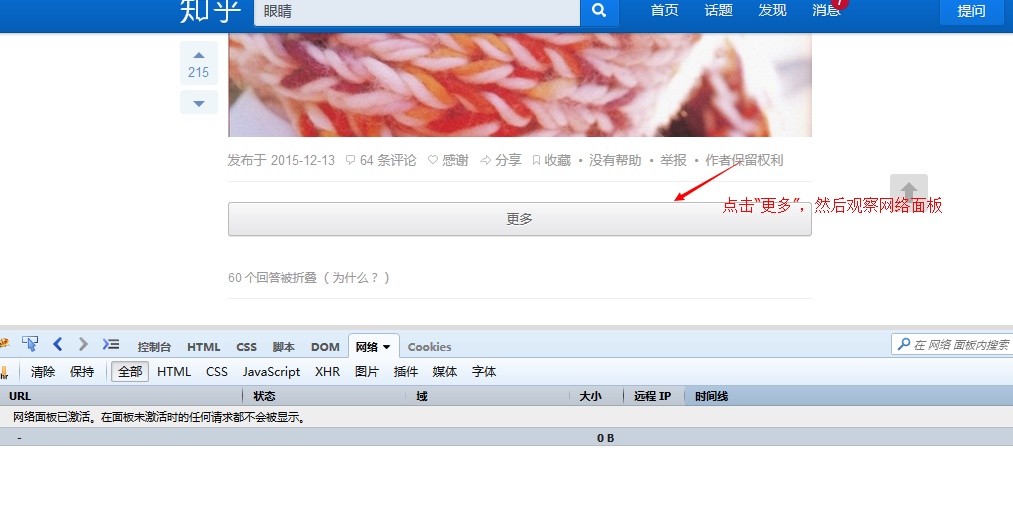
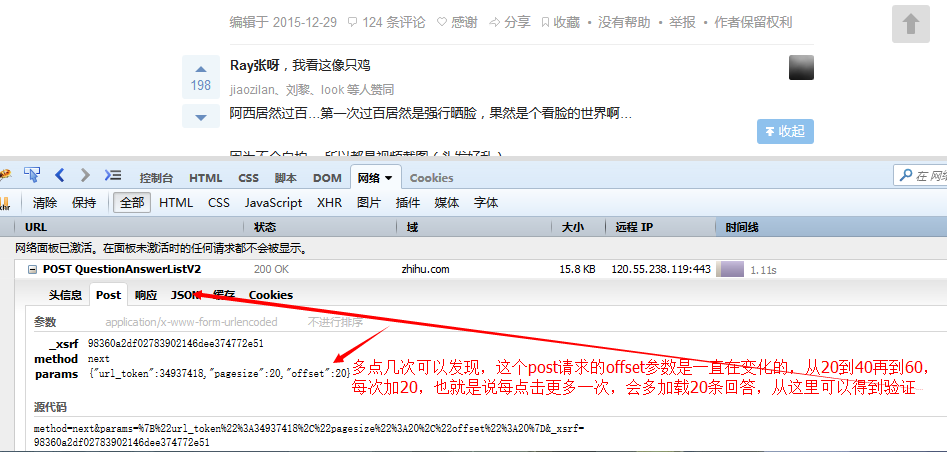
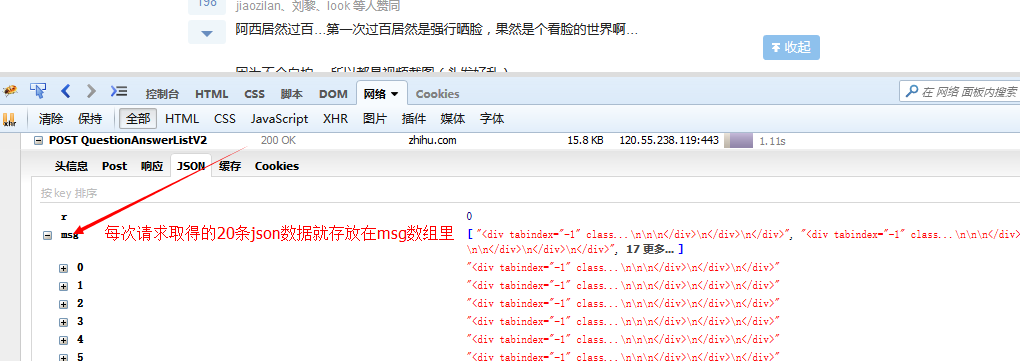
この情報を使用して、このデータを取得するために同じリクエストの送信をシミュレートできます。
/*每隔毫秒模拟发送ajax请求,并获取请求结果中所有的图片链接*/
var getIAjaxUrlList=function(offset){
request.post("https://www.zhihu.com/node/QuestionAnswerListV")
.set(config)
.send("method=next¶ms=%B%url_token%%A%C%pagesize%%A%C%offset%%A" +offset+ "%D&_xsrf=adfdeee")
.end(function(err,res){
if(err){
console.log(err);
}else{
var response=JSON.parse(res.text);/*想用json的话对json序列化即可,提交json的话需要对json进行反序列化*/
if(response.msg&&response.msg.length){
var $=cheerio.load(response.msg.join(""));/*把所有的数组元素拼接在一起,以空白符分隔,不要这样join(),它会默认数组元素以逗号分隔*/
var answerList=$(".zm-item-answer");
answerList.map(function(i,answer){
var images=$(answer).find('.zm-item-rich-text img');
images.map(function(i,image){
photos.push($(image).attr("src"));
});
});
setTimeout(function(){
offset+=;
console.log("已成功抓取"+photos.length+"张图片的链接");
getIAjaxUrlList(offset);
},);
}else{
console.log("图片链接全部获取完毕,一共有"+photos.length+"条图片链接");
// console.log(photos);
return downloadImg();
}
}
});
} このリクエストをコード https://www.zhihu.com/node/QuestionAnswerListV2 に投稿し、元のリクエスト ヘッダーとリクエスト パラメーターをリクエスト ヘッダーとリクエスト パラメーターとしてコピーし、スーパーエージェントの set メソッドではリクエストヘッダーの設定に使用でき、send メソッドはリクエストパラメータの送信に使用できます。最初にリクエストパラメータのオフセットを 20 に設定し、一定時間ごとにオフセットに 20 を加えてリクエストを再送信します。これは、一定時間ごとに ajax リクエストを送信し、毎回最新の 20 個のデータを取得するのと同じです。データを取得したら、データをある程度処理して HTML の段落全体に変換します。これにより、その後の抽出とリンクの処理が容易になります。 非同期同時実行制御が画像をダウンロードし、すべての画像リンクを取得した後、つまり、response.msg が空であると判断された場合、これらの画像を 1 つずつダウンロードします。ご覧のとおり、これらの画像を 1 つずつダウンロードすることは不可能です。写真は十分あります
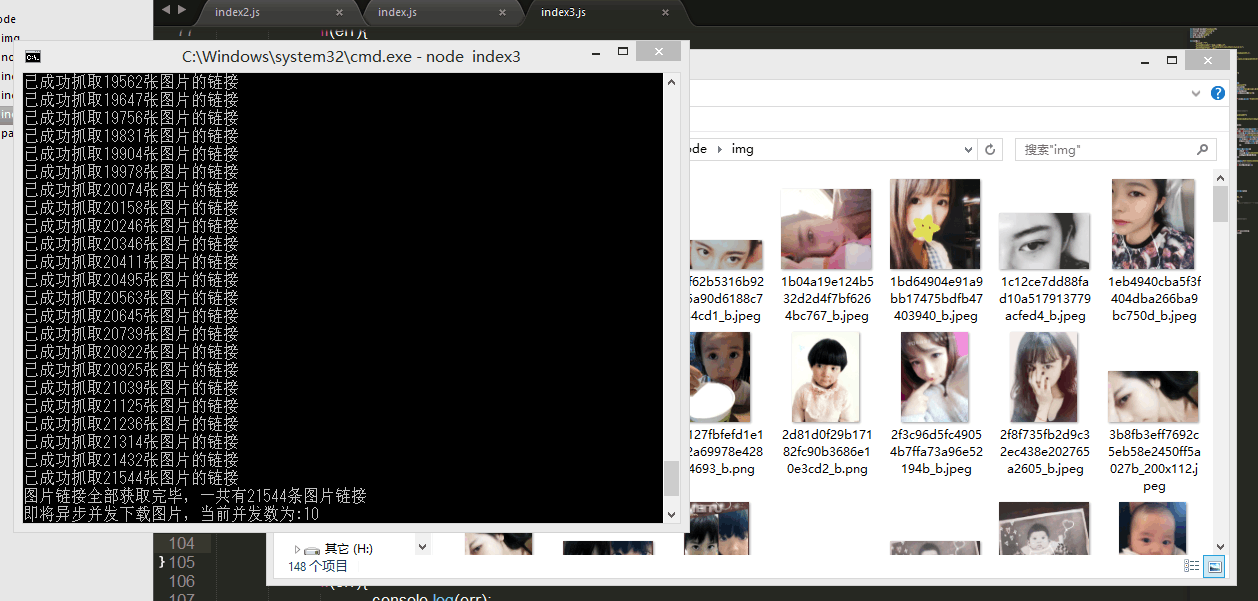
はい、20,000 枚以上の写真がありますが、幸いなことに、nodejs には魔法のシングルスレッド非同期機能があり、これらの写真を同時にダウンロードできます。しかし、今回は問題が発生しました。同時に送信されるリクエストが多すぎると、その IP アドレスが Web サイトによってブロックされると聞きました。これは本当ですか?わかりません、試したくないので試していません( ̄ー ̄〃) なので、この時点で非同期同時実行の数を制御する必要があります。
ここでは魔法のモジュール => async が使用されています。これは、保守が難しいコールバック ピラミッドの悪魔を取り除くだけでなく、非同期プロセスを簡単に管理するのにも役立ちます。詳細についてはドキュメントを参照してください。私自身は使い方がわからないので、ここでは強力な async.mapLimit メソッドのみを使用します。本当にすごいですね。
var requestAndwrite=function(url,callback){
request.get(url).end(function(err,res){
if(err){
console.log(err);
console.log("有一张图片请求失败啦...");
}else{
var fileName=path.basename(url);
fs.writeFile("./img/"+fileName,res.body,function(err){
if(err){
console.log(err);
console.log("有一张图片写入失败啦...");
}else{
console.log("图片下载成功啦");
callback(null,"successful !");
/*callback貌似必须调用,第二个参数将传给下一个回调函数的result,result是一个数组*/
}
});
}
});
}
var downloadImg=function(asyncNum){
/*有一些图片链接地址不完整没有“http:”头部,帮它们拼接完整*/
for(var i=;i<photos.length;i++){
if(photos[i].indexOf("http")===-){
photos[i]="http:"+photos[i];
}
}
console.log("即将异步并发下载图片,当前并发数为:"+asyncNum);
async.mapLimit(photos,asyncNum,function(photo,callback){
console.log("已有"+asyncNum+"张图片进入下载队列");
requestAndwrite(photo,callback);
},function(err,result){
if(err){
console.log(err);
}else{
// console.log(result);<=会输出一个有万多个“successful”字符串的数组
console.log("全部已下载完毕!");
}
});
};まずここを見てください=>
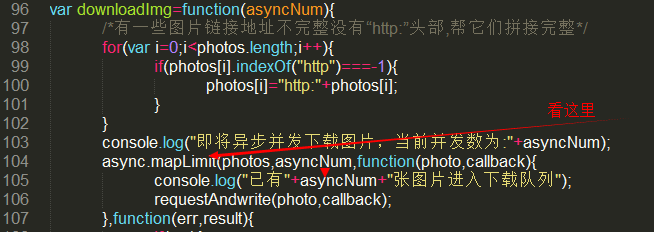
mapLimit メソッドの最初のパラメータ photos は、すべての画像リンクの配列であり、asyncNum は同時リクエストの数を制限します。このパラメータがないと、20,000 を超えるリクエストが送信されます。同時に、IP は正常にブロックされますが、このパラメーターの値が 10 の場合、一度に配列から 10 個のリンクをフェッチし、その後 10 個の同時リクエストを実行するだけです。リクエストに応答すると、次の 10 個のリクエストが送信されます。 Ni Meng に伝えてください。同時に 100 件のメッセージを送信しても大丈夫です。ダウンロード速度がさらに上がるかどうかはわかりません。教えてください。
上記では、Nodejs クローラーの上級チュートリアルで非同期同時実行制御の関連知識を紹介しました。お役に立てば幸いです。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



