

Python クローラー プログラミング フレームワーク Scrapy 入門学習チュートリアル

1. Scrapy の紹介
Scrapy は、Web サイトのデータをクロールし、構造化データを抽出するために作成されたアプリケーション フレームワークです。 データマイニング、情報処理、履歴データの保存などの一連のプログラムで使用できます。
元々はページ スクレイピング (具体的には Web スクレイピング) 用に設計されましたが、API (Amazon Associates Web Services など) や一般的な Web クローラーによって返されたデータを取得するためにも使用できます。 Scrapy は広く使用されており、データマイニング、モニタリング、自動テストに使用できます
Scrapy は、Twisted 非同期ネットワーク ライブラリを使用してネットワーク通信を処理します。全体の構成は大まかに以下の通りです
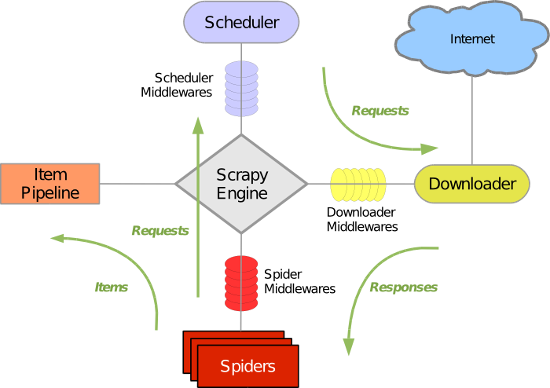
Scrapy には主に次のコンポーネントが含まれています:
(1) エンジン (Scrapy): システム全体のデータフロー処理を処理し、トランザクションをトリガーするために使用されます (コアフレームワーク)
(2) スケジューラー (Scheduler): エンジンからリクエストを受け入れ、キューにプッシュし、エンジンが再度リクエストしたときに返すために使用されます。URL (キャプチャされた Web ページの URL またはリンク) として想像できます。 ) 優先キュー。次にクロールする URL を決定し、重複する URL を削除します
(3) ダウンローダー: Web コンテンツをダウンロードし、Web コンテンツをスパイダーに返すために使用されます (Scrapy ダウンローダーは、ツイストされた効率的な非同期モデルに基づいて構築されています)
(4) スパイダー: クローラーは主に、いわゆるエンティティ (アイテム) である特定の Web ページから必要な情報を抽出するために使用されます。ユーザーはそこからリンクを抽出し、Scrapy に次のページのクロールを継続させることもできます
プロジェクト パイプライン (パイプライン): クローラーによって Web ページから抽出されたエンティティの処理を担当します。主な機能は、エンティティを永続化し、エンティティの有効性を検証し、不要な情報を削除することです。ページがクローラーによって解析されると、プロジェクト パイプラインに送信され、データはいくつかの特定のシーケンスを通じて処理されます。
(5) ダウンローダーミドルウェア: Scrapy エンジンとダウンローダーの間にあるフレームワークで、主に Scrapy エンジンとダウンローダー間のリクエストと応答を処理します。
(6) Spider Middlewares: Scrapy エンジンとクローラーの間のフレームワーク。その主な仕事は、スパイダーの応答入力と要求出力を処理することです。
(7) スケジューラ ミドルウェア: Scrapy エンジンとスケジューラの間のミドルウェアで、Scrapy エンジンからスケジューラにリクエストと応答を送信します。
Scrapyの操作プロセスは大まかに以下のとおりです:
まず、エンジンは後続のクロールのためにスケジューラーからリンク (URL) を取り出します
エンジンは URL をリクエスト (Request) にカプセル化し、それをダウンローダーに渡します。ダウンローダーはリソースをダウンロードし、それを応答パケット (Response) にカプセル化します。
次に、クローラーはレスポンスを解析します
エンティティ (項目) が解析されると、さらなる処理のためにエンティティ パイプラインに渡されます。
解析されたリンク(URL)が取得できたら、そのURLをスケジューラに渡してクロールを待ちます
2. Scrapyをインストールします
次のコマンドを使用します:
3. スクレイピーチュートリアル
スクレイピングする前に、コードを保存するディレクトリを入力して、新しい Scrapy プロジェクトを作成する必要があります:
リーリー
(1)scrapy.cfg:プロジェクト設定ファイル
(2) チュートリアル/: プロジェクト Python モジュール。後でここにコードを追加します
(3)tutorial/items.py:プロジェクトアイテムファイル
(4)tutorial/pipelines.py: プロジェクトパイプラインファイル
(5)tutorial/settings.py: プロジェクト設定ファイル
(6)tutorial/spiders: スパイダーを配置するディレクトリ
3.1. アイテムを定義する
Items はスクレイピングされたデータをロードするコンテナです。Python の辞書のように機能しますが、スペルミスを防ぐために未定義のフィールドをパディングするなど、より多くの保護を提供します。
scrapy.Item クラスを作成し、scrapy.Field.型のクラス属性を定義することで、Item を宣言します
リーリー
Spider は、ドメイン (またはドメイン グループ) から情報をクロールするために使用されるユーザー作成のクラスで、ダウンロード用の URL の予備リスト、リンクをたどる方法、アイテムを抽出するためにこれらの Web ページのコンテンツを解析する方法を定義します。
Spider を構築するには、scrapy.Spider 基本クラスを継承し、3 つの主要な必須プロパティを特定します。
name:爬虫的识别名,它必须是唯一的,在不同的爬虫中你必须定义不同的名字.
start_urls:包含了Spider在启动时进行爬取的url列表。因此,第一个被获取到的页面将是其中之一。后续的URL则从初始的URL获取到的数据中提取。我们可以利用正则表达式定义和过滤需要进行跟进的链接。
parse():是spider的一个方法。被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
这个方法负责解析返回的数据、匹配抓取的数据(解析为 item )并跟踪更多的 URL。
在 /tutorial/tutorial/spiders 目录下创建 dmoz_spider.py
import scrapy
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
filename = response.url.split("/")[-2]
with open(filename, 'wb') as f:
f.write(response.body)
3.3. 爬取
当前项目结构
├── scrapy.cfg └── tutorial ├── __init__.py ├── items.py ├── pipelines.py ├── settings.py └── spiders ├── __init__.py └── dmoz_spider.py
到项目根目录, 然后运行命令:
$ scrapy crawl dmoz
2014-12-15 09:30:59+0800 [scrapy] INFO: Scrapy 0.24.4 started (bot: tutorial)
2014-12-15 09:30:59+0800 [scrapy] INFO: Optional features available: ssl, http11
2014-12-15 09:30:59+0800 [scrapy] INFO: Overridden settings: {'NEWSPIDER_MODULE': 'tutorial.spiders', 'SPIDER_MODULES': ['tutorial.spiders'], 'BOT_NAME': 'tutorial'}
2014-12-15 09:30:59+0800 [scrapy] INFO: Enabled extensions: LogStats, TelnetConsole, CloseSpider, WebService, CoreStats, SpiderState
2014-12-15 09:30:59+0800 [scrapy] INFO: Enabled downloader middlewares: HttpAuthMiddleware, DownloadTimeoutMiddleware, UserAgentMiddleware, RetryMiddleware, DefaultHeadersMiddleware, MetaRefreshMiddleware, HttpCompressionMiddleware, RedirectMiddleware, CookiesMiddleware, ChunkedTransferMiddleware, DownloaderStats
2014-12-15 09:30:59+0800 [scrapy] INFO: Enabled spider middlewares: HttpErrorMiddleware, OffsiteMiddleware, RefererMiddleware, UrlLengthMiddleware, DepthMiddleware
2014-12-15 09:30:59+0800 [scrapy] INFO: Enabled item pipelines:
2014-12-15 09:30:59+0800 [dmoz] INFO: Spider opened
2014-12-15 09:30:59+0800 [dmoz] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2014-12-15 09:30:59+0800 [scrapy] DEBUG: Telnet console listening on 127.0.0.1:6023
2014-12-15 09:30:59+0800 [scrapy] DEBUG: Web service listening on 127.0.0.1:6080
2014-12-15 09:31:00+0800 [dmoz] DEBUG: Crawled (200) <GET http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/> (referer: None)
2014-12-15 09:31:00+0800 [dmoz] DEBUG: Crawled (200) <GET http://www.dmoz.org/Computers/Programming/Languages/Python/Books/> (referer: None)
2014-12-15 09:31:00+0800 [dmoz] INFO: Closing spider (finished)
2014-12-15 09:31:00+0800 [dmoz] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 516,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 16338,
'downloader/response_count': 2,
'downloader/response_status_count/200': 2,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2014, 12, 15, 1, 31, 0, 666214),
'log_count/DEBUG': 4,
'log_count/INFO': 7,
'response_received_count': 2,
'scheduler/dequeued': 2,
'scheduler/dequeued/memory': 2,
'scheduler/enqueued': 2,
'scheduler/enqueued/memory': 2,
'start_time': datetime.datetime(2014, 12, 15, 1, 30, 59, 533207)}
2014-12-15 09:31:00+0800 [dmoz] INFO: Spider closed (finished)
3.4. 提取Items
3.4.1. 介绍Selector
从网页中提取数据有很多方法。Scrapy使用了一种基于 XPath 或者 CSS 表达式机制: Scrapy Selectors
出XPath表达式的例子及对应的含义:
- /html/head/title: 选择HTML文档中 标签内的
元素</li> <li>/html/head/title/text(): 选择 <title> 元素内的文本</li> <li>//td: 选择所有的 <td> 元素</li> <li>//div[@class="mine"]: 选择所有具有class="mine" 属性的 div 元素</li> </ul> <p>等多强大的功能使用可以查看XPath tutorial</p> <p>为了方便使用 XPaths,Scrapy 提供 Selector 类, 有四种方法 :</p> <ul> <li>xpath():返回selectors列表, 每一个selector表示一个xpath参数表达式选择的节点.</li> <li>css() : 返回selectors列表, 每一个selector表示CSS参数表达式选择的节点</li> <li>extract():返回一个unicode字符串,该字符串为XPath选择器返回的数据</li> <li>re(): 返回unicode字符串列表,字符串作为参数由正则表达式提取出来</li> </ul> <p><strong>3.4.2. 取出数据<br /> </strong></p> <ul> <li>首先使用谷歌浏览器开发者工具, 查看网站源码, 来看自己需要取出的数据形式(这种方法比较麻烦), 更简单的方法是直接对感兴趣的东西右键审查元素, 可以直接查看网站源码</li> </ul> <p>在查看网站源码后, 网站信息在第二个<ul>内</p> <div class="jb51code"> <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'> <ul class="directory-url" style="margin-left:0;"> <li><a href="http://www.pearsonhighered.com/educator/academic/product/0,,0130260363,00%2Ben-USS_01DBC.html" class="listinglink">Core Python Programming</a> - By Wesley J. Chun; Prentice Hall PTR, 2001, ISBN 0130260363. For experienced developers to improve extant skills; professional level examples. Starts by introducing syntax, objects, error handling, functions, classes, built-ins. [Prentice Hall] <div class="flag"><a href="/public/flag?cat=Computers%2FProgramming%2FLanguages%2FPython%2FBooks&url=http%3A%2F%2Fwww.pearsonhighered.com%2Feducator%2Facademic%2Fproduct%2F0%2C%2C0130260363%2C00%252Ben-USS_01DBC.html"><img src="/static/imghw/default1.png" data-src="/img/flag.png" class="lazy" alt="Python クローラー プログラミング フレームワーク Scrapy 入門学習チュートリアル" title="report an issue with this listing"></a></div> </li> ...省略部分... </ul> </pre><div class="contentsignin">ログイン後にコピー</div></div> </p> <p>那么就可以通过一下方式进行提取数据</p> <div class="jb51code"> <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'> #通过如下命令选择每个在网站中的 <li> 元素: sel.xpath('//ul/li') #网站描述: sel.xpath('//ul/li/text()').extract() #网站标题: sel.xpath('//ul/li/a/text()').extract() #网站链接: sel.xpath('//ul/li/a/@href').extract() </pre><div class="contentsignin">ログイン後にコピー</div></div> </p> <p>如前所述,每个 xpath() 调用返回一个 selectors 列表,所以我们可以结合 xpath() 去挖掘更深的节点。我们将会用到这些特性,所以:</p> <div class="jb51code"> <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'> for sel in response.xpath('//ul/li') title = sel.xpath('a/text()').extract() link = sel.xpath('a/@href').extract() desc = sel.xpath('text()').extract() print title, link, desc </pre><div class="contentsignin">ログイン後にコピー</div></div> </p> <p>在已有的爬虫文件中修改代码</p> <div class="jb51code"> <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'> import scrapy class DmozSpider(scrapy.Spider): name = "dmoz" allowed_domains = ["dmoz.org"] start_urls = [ "http://www.dmoz.org/Computers/Programming/Languages/Python/Books/", "http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/" ] def parse(self, response): for sel in response.xpath('//ul/li'): title = sel.xpath('a/text()').extract() link = sel.xpath('a/@href').extract() desc = sel.xpath('text()').extract() print title, link, desc </pre><div class="contentsignin">ログイン後にコピー</div></div> </p> <p><strong>3.4.3. 使用item<br /> </strong>Item对象是自定义的python字典,可以使用标准的字典语法来获取到其每个字段的值(字段即是我们之前用Field赋值的属性)</p> <div class="jb51code"> <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'> >>> item = DmozItem() >>> item['title'] = 'Example title' >>> item['title'] 'Example title' </pre><div class="contentsignin">ログイン後にコピー</div></div> </p> <p>一般来说,Spider将会将爬取到的数据以 Item 对象返回, 最后修改爬虫类,使用 Item 来保存数据,代码如下</p> <div class="jb51code"> <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'> from scrapy.spider import Spider from scrapy.selector import Selector from tutorial.items import DmozItem class DmozSpider(Spider): name = "dmoz" allowed_domains = ["dmoz.org"] start_urls = [ "http://www.dmoz.org/Computers/Programming/Languages/Python/Books/", "http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/", ] def parse(self, response): sel = Selector(response) sites = sel.xpath('//ul[@class="directory-url"]/li') items = [] for site in sites: item = DmozItem() item['name'] = site.xpath('a/text()').extract() item['url'] = site.xpath('a/@href').extract() item['description'] = site.xpath('text()').re('-\s[^\n]*\\r') items.append(item) return items </pre><div class="contentsignin">ログイン後にコピー</div></div> </p> <p><strong>3.5. 使用Item Pipeline<br /> </strong>当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。<br /> 每个item pipeline组件(有时称之为ItemPipeline)是实现了简单方法的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。<br /> 以下是item pipeline的一些典型应用:</p> <ul> <li>清理HTML数据</li> <li>验证爬取的数据(检查item包含某些字段)</li> <li>查重(并丢弃)</li> <li>将爬取结果保存,如保存到数据库、XML、JSON等文件中</li> </ul> <p>编写你自己的item pipeline很简单,每个item pipeline组件是一个独立的Python类,同时必须实现以下方法:</p> <p>(1)process_item(item, spider) #每个item pipeline组件都需要调用该方法,这个方法必须返回一个 Item (或任何继承类)对象,或是抛出 DropItem异常,被丢弃的item将不会被之后的pipeline组件所处理。</p> <p>#参数:</p> <p>item: 由 parse 方法返回的 Item 对象(Item对象)</p> <p>spider: 抓取到这个 Item 对象对应的爬虫对象(Spider对象)</p> <p>(2)open_spider(spider) #当spider被开启时,这个方法被调用。</p> <p>#参数:</p> <p>spider : (Spider object) – 被开启的spider</p> <p>(3)close_spider(spider) #当spider被关闭时,这个方法被调用,可以再爬虫关闭后进行相应的数据处理。</p> <p>#参数:</p> <p>spider : (Spider object) – 被关闭的spider</p> <p>为JSON文件编写一个items</p> <div class="jb51code"> <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'> from scrapy.exceptions import DropItem class TutorialPipeline(object): # put all words in lowercase words_to_filter = ['politics', 'religion'] def process_item(self, item, spider): for word in self.words_to_filter: if word in unicode(item['description']).lower(): raise DropItem("Contains forbidden word: %s" % word) else: return item </pre><div class="contentsignin">ログイン後にコピー</div></div> </p> <p>在 settings.py 中设置ITEM_PIPELINES激活item pipeline,其默认为[]</p> <div class="jb51code"> <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'> ITEM_PIPELINES = {'tutorial.pipelines.FilterWordsPipeline': 1} </pre><div class="contentsignin">ログイン後にコピー</div></div> </p> <p><strong>3.6. 存储数据<br /> </strong>使用下面的命令存储为json文件格式</p> <p>scrapy crawl dmoz -o items.json</p> <p><strong>4.示例<br /> 4.1最简单的spider(默认的Spider)<br /> </strong>用实例属性start_urls中的URL构造Request对象<br /> 框架负责执行request<br /> 将request返回的response对象传递给parse方法做分析</p> <p>简化后的源码:</p> <div class="jb51code"> <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'> class Spider(object_ref): """Base class for scrapy spiders. All spiders must inherit from this class. """ name = None def __init__(self, name=None, **kwargs): if name is not None: self.name = name elif not getattr(self, 'name', None): raise ValueError("%s must have a name" % type(self).__name__) self.__dict__.update(kwargs) if not hasattr(self, 'start_urls'): self.start_urls = [] def start_requests(self): for url in self.start_urls: yield self.make_requests_from_url(url) def make_requests_from_url(self, url): return Request(url, dont_filter=True) def parse(self, response): raise NotImplementedError BaseSpider = create_deprecated_class('BaseSpider', Spider) </pre><div class="contentsignin">ログイン後にコピー</div></div> </p> <p>一个回调函数返回多个request的例子</p> <div class="jb51code"> <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'> import scrapyfrom myproject.items import MyItemclass MySpider(scrapy.Spider): name = 'example.com' allowed_domains = ['example.com'] start_urls = [ 'http://www.example.com/1.html', 'http://www.example.com/2.html', 'http://www.example.com/3.html', ] def parse(self, response): sel = scrapy.Selector(response) for h3 in response.xpath('//h3').extract(): yield MyItem(title=h3) for url in response.xpath('//a/@href').extract(): yield scrapy.Request(url, callback=self.parse) </pre><div class="contentsignin">ログイン後にコピー</div></div> </p> <p>构造一个Request对象只需两个参数: URL和回调函数</p> <p><strong>4.2CrawlSpider<br /> </strong>通常我们需要在spider中决定:哪些网页上的链接需要跟进, 哪些网页到此为止,无需跟进里面的链接。CrawlSpider为我们提供了有用的抽象——Rule,使这类爬取任务变得简单。你只需在rule中告诉scrapy,哪些是需要跟进的。<br /> 回忆一下我们爬行mininova网站的spider.</p> <div class="jb51code"> <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'> class MininovaSpider(CrawlSpider): name = 'mininova' allowed_domains = ['mininova.org'] start_urls = ['http://www.mininova.org/yesterday'] rules = [Rule(LinkExtractor(allow=['/tor/\d+']), 'parse_torrent')] def parse_torrent(self, response): torrent = TorrentItem() torrent['url'] = response.url torrent['name'] = response.xpath("//h1/text()").extract() torrent['description'] = response.xpath("//div[@id='description']").extract() torrent['size'] = response.xpath("//div[@id='specifications']/p[2]/text()[2]").extract() return torrent </pre><div class="contentsignin">ログイン後にコピー</div></div> </p> <p>上面代码中 rules的含义是:匹配/tor/\d+的URL返回的内容,交给parse_torrent处理,并且不再跟进response上的URL。<br /> 官方文档中也有个例子:</p> <div class="jb51code"> <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'> rules = ( # 提取匹配 'category.php' (但不匹配 'subsection.php') 的链接并跟进链接(没有callback意味着follow默认为True) Rule(LinkExtractor(allow=('category\.php', ), deny=('subsection\.php', ))), # 提取匹配 'item.php' 的链接并使用spider的parse_item方法进行分析 Rule(LinkExtractor(allow=('item\.php', )), callback='parse_item'), ) </pre><div class="contentsignin">ログイン後にコピー</div></div> <p>除了Spider和CrawlSpider外,还有XMLFeedSpider, CSVFeedSpider, SitemapSpider</p> <p></p> </div> </div> </div> </div> </div> </div> </div> </div> <div class="wzconShengming_sp"> <div class="bzsmdiv_sp">このウェブサイトの声明</div> <div>この記事の内容はネチズンが自主的に寄稿したものであり、著作権は原著者に帰属します。このサイトは、それに相当する法的責任を負いません。盗作または侵害の疑いのあるコンテンツを見つけた場合は、admin@php.cn までご連絡ください。</div> </div> </div> <ins class="adsbygoogle" style="display:block" data-ad-format="autorelaxed" data-ad-client="ca-pub-5902227090019525" data-ad-slot="2507867629"></ins> <script> (adsbygoogle = window.adsbygoogle || []).push({}); </script> <div class="AI_ToolDetails_main4sR"> <ins class="adsbygoogle" style="display:block" data-ad-client="ca-pub-5902227090019525" data-ad-slot="3653428331" data-ad-format="auto" data-full-width-responsive="true"></ins> <script> (adsbygoogle = window.adsbygoogle || []).push({}); </script> <!-- <div class="phpgenera_Details_mainR4"> <div class="phpmain1_4R_readrank"> <div class="phpmain1_4R_readrank_top"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" src="/static/imghw/hotarticle2.png" alt="" /> <h2>人気の記事</h2> </div> <div class="phpgenera_Details_mainR4_bottom"> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/ja/faq/1796793874.html" title="KB5055523を修正する方法Windows 11にインストールできませんか?" class="phpgenera_Details_mainR4_bottom_title">KB5055523を修正する方法Windows 11にインストールできませんか?</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <span>4週間前</span> <span>By DDD</span> </div> </div> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/ja/faq/1796793871.html" title="KB5055518を修正する方法Windows 10にインストールできませんか?" class="phpgenera_Details_mainR4_bottom_title">KB5055518を修正する方法Windows 10にインストールできませんか?</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <span>4週間前</span> <span>By DDD</span> </div> </div> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/ja/faq/1796797907.html" title="<🎜>:庭を育てる - 完全な突然変異ガイド" class="phpgenera_Details_mainR4_bottom_title"><🎜>:庭を育てる - 完全な突然変異ガイド</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <span>2週間前</span> <span>By DDD</span> </div> </div> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/ja/faq/1796797130.html" title="<🎜>:バブルガムシミュレーターインフィニティ - ロイヤルキーの取得と使用方法" class="phpgenera_Details_mainR4_bottom_title"><🎜>:バブルガムシミュレーターインフィニティ - ロイヤルキーの取得と使用方法</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <span>3週間前</span> <span>By 尊渡假赌尊渡假赌尊渡假赌</span> </div> </div> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/ja/faq/1796796771.html" title="KB5055612を修正する方法Windows 10にインストールできませんか?" class="phpgenera_Details_mainR4_bottom_title">KB5055612を修正する方法Windows 10にインストールできませんか?</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <span>3週間前</span> <span>By DDD</span> </div> </div> </div> <div class="phpgenera_Details_mainR3_more"> <a href="https://www.php.cn/ja/article.html">もっと見る</a> </div> </div> </div> --> <div class="phpgenera_Details_mainR3"> <div class="phpmain1_4R_readrank"> <div class="phpmain1_4R_readrank_top"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" src="/static/imghw/hottools2.png" alt="" /> <h2>ホットAIツール</h2> </div> <div class="phpgenera_Details_mainR3_bottom"> <div class="phpmain_tab2_mids_top"> <a href="https://www.php.cn/ja/ai/undresserai-undress" title="Undresser.AI Undress" class="phpmain_tab2_mids_top_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" class="lazy" data-src="https://img.php.cn/upload/ai_manual/001/246/273/173411540686492.jpg?x-oss-process=image/resize,m_fill,h_50,w_50" src="/static/imghw/default1.png" alt="Undresser.AI Undress" /> </a> <div class="phpmain_tab2_mids_info"> <a href="https://www.php.cn/ja/ai/undresserai-undress" title="Undresser.AI Undress" class="phpmain_tab2_mids_title"> <h3>Undresser.AI Undress</h3> </a> <p>リアルなヌード写真を作成する AI 搭載アプリ</p> </div> </div> <div class="phpmain_tab2_mids_top"> <a href="https://www.php.cn/ja/ai/ai-clothes-remover" title="AI Clothes Remover" class="phpmain_tab2_mids_top_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" class="lazy" data-src="https://img.php.cn/upload/ai_manual/001/246/273/173411552797167.jpg?x-oss-process=image/resize,m_fill,h_50,w_50" src="/static/imghw/default1.png" alt="AI Clothes Remover" /> </a> <div class="phpmain_tab2_mids_info"> <a href="https://www.php.cn/ja/ai/ai-clothes-remover" title="AI Clothes Remover" class="phpmain_tab2_mids_title"> <h3>AI Clothes Remover</h3> </a> <p>写真から衣服を削除するオンライン AI ツール。</p> </div> </div> <div class="phpmain_tab2_mids_top"> <a href="https://www.php.cn/ja/ai/undress-ai-tool" title="Undress AI Tool" class="phpmain_tab2_mids_top_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" class="lazy" data-src="https://img.php.cn/upload/ai_manual/001/246/273/173410641626608.jpg?x-oss-process=image/resize,m_fill,h_50,w_50" src="/static/imghw/default1.png" alt="Undress AI Tool" /> </a> <div class="phpmain_tab2_mids_info"> <a href="https://www.php.cn/ja/ai/undress-ai-tool" title="Undress AI Tool" class="phpmain_tab2_mids_title"> <h3>Undress AI Tool</h3> </a> <p>脱衣画像を無料で</p> </div> </div> <div class="phpmain_tab2_mids_top"> <a href="https://www.php.cn/ja/ai/clothoffio" title="Clothoff.io" class="phpmain_tab2_mids_top_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" class="lazy" data-src="https://img.php.cn/upload/ai_manual/001/246/273/173411529149311.jpg?x-oss-process=image/resize,m_fill,h_50,w_50" src="/static/imghw/default1.png" alt="Clothoff.io" /> </a> <div class="phpmain_tab2_mids_info"> <a href="https://www.php.cn/ja/ai/clothoffio" title="Clothoff.io" class="phpmain_tab2_mids_title"> <h3>Clothoff.io</h3> </a> <p>AI衣類リムーバー</p> </div> </div> <div class="phpmain_tab2_mids_top"> <a href="https://www.php.cn/ja/ai/video-swap" title="Video Face Swap" class="phpmain_tab2_mids_top_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" class="lazy" data-src="https://img.php.cn/upload/ai_manual/001/246/273/173414504068133.jpg?x-oss-process=image/resize,m_fill,h_50,w_50" src="/static/imghw/default1.png" alt="Video Face Swap" /> </a> <div class="phpmain_tab2_mids_info"> <a href="https://www.php.cn/ja/ai/video-swap" title="Video Face Swap" class="phpmain_tab2_mids_title"> <h3>Video Face Swap</h3> </a> <p>完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。</p> </div> </div> </div> <div class="phpgenera_Details_mainR3_more"> <a href="https://www.php.cn/ja/ai">もっと見る</a> </div> </div> </div> <script src="https://sw.php.cn/hezuo/cac1399ab368127f9b113b14eb3316d0.js" type="text/javascript"></script> <div class="phpgenera_Details_mainR4"> <div class="phpmain1_4R_readrank"> <div class="phpmain1_4R_readrank_top"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" src="/static/imghw/hotarticle2.png" alt="" /> <h2>人気の記事</h2> </div> <div class="phpgenera_Details_mainR4_bottom"> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/ja/faq/1796793874.html" title="KB5055523を修正する方法Windows 11にインストールできませんか?" class="phpgenera_Details_mainR4_bottom_title">KB5055523を修正する方法Windows 11にインストールできませんか?</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <span>4週間前</span> <span>By DDD</span> </div> </div> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/ja/faq/1796793871.html" title="KB5055518を修正する方法Windows 10にインストールできませんか?" class="phpgenera_Details_mainR4_bottom_title">KB5055518を修正する方法Windows 10にインストールできませんか?</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <span>4週間前</span> <span>By DDD</span> </div> </div> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/ja/faq/1796797907.html" title="<🎜>:庭を育てる - 完全な突然変異ガイド" class="phpgenera_Details_mainR4_bottom_title"><🎜>:庭を育てる - 完全な突然変異ガイド</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <span>2週間前</span> <span>By DDD</span> </div> </div> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/ja/faq/1796797130.html" title="<🎜>:バブルガムシミュレーターインフィニティ - ロイヤルキーの取得と使用方法" class="phpgenera_Details_mainR4_bottom_title"><🎜>:バブルガムシミュレーターインフィニティ - ロイヤルキーの取得と使用方法</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <span>3週間前</span> <span>By 尊渡假赌尊渡假赌尊渡假赌</span> </div> </div> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/ja/faq/1796796771.html" title="KB5055612を修正する方法Windows 10にインストールできませんか?" class="phpgenera_Details_mainR4_bottom_title">KB5055612を修正する方法Windows 10にインストールできませんか?</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <span>3週間前</span> <span>By DDD</span> </div> </div> </div> <div class="phpgenera_Details_mainR3_more"> <a href="https://www.php.cn/ja/article.html">もっと見る</a> </div> </div> </div> <div class="phpgenera_Details_mainR3"> <div class="phpmain1_4R_readrank"> <div class="phpmain1_4R_readrank_top"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" src="/static/imghw/hottools2.png" alt="" /> <h2>ホットツール</h2> </div> <div class="phpgenera_Details_mainR3_bottom"> <div class="phpmain_tab2_mids_top"> <a href="https://www.php.cn/ja/toolset/development-tools/92" title="メモ帳++7.3.1" class="phpmain_tab2_mids_top_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" class="lazy" data-src="https://img.php.cn/upload/manual/000/000/001/58ab96f0f39f7357.jpg?x-oss-process=image/resize,m_fill,h_50,w_72" src="/static/imghw/default1.png" alt="メモ帳++7.3.1" /> </a> <div class="phpmain_tab2_mids_info"> <a href="https://www.php.cn/ja/toolset/development-tools/92" title="メモ帳++7.3.1" class="phpmain_tab2_mids_title"> <h3>メモ帳++7.3.1</h3> </a> <p>使いやすく無料のコードエディター</p> </div> </div> <div class="phpmain_tab2_mids_top"> <a href="https://www.php.cn/ja/toolset/development-tools/93" title="SublimeText3 中国語版" class="phpmain_tab2_mids_top_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" class="lazy" data-src="https://img.php.cn/upload/manual/000/000/001/58ab97a3baad9677.jpg?x-oss-process=image/resize,m_fill,h_50,w_72" src="/static/imghw/default1.png" alt="SublimeText3 中国語版" /> </a> <div class="phpmain_tab2_mids_info"> <a href="https://www.php.cn/ja/toolset/development-tools/93" title="SublimeText3 中国語版" class="phpmain_tab2_mids_title"> <h3>SublimeText3 中国語版</h3> </a> <p>中国語版、とても使いやすい</p> </div> </div> <div class="phpmain_tab2_mids_top"> <a href="https://www.php.cn/ja/toolset/development-tools/121" title="ゼンドスタジオ 13.0.1" class="phpmain_tab2_mids_top_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" class="lazy" data-src="https://img.php.cn/upload/manual/000/000/001/58ab97ecd1ab2670.jpg?x-oss-process=image/resize,m_fill,h_50,w_72" src="/static/imghw/default1.png" alt="ゼンドスタジオ 13.0.1" /> </a> <div class="phpmain_tab2_mids_info"> <a href="https://www.php.cn/ja/toolset/development-tools/121" title="ゼンドスタジオ 13.0.1" class="phpmain_tab2_mids_title"> <h3>ゼンドスタジオ 13.0.1</h3> </a> <p>強力な PHP 統合開発環境</p> </div> </div> <div class="phpmain_tab2_mids_top"> <a href="https://www.php.cn/ja/toolset/development-tools/469" title="ドリームウィーバー CS6" class="phpmain_tab2_mids_top_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" class="lazy" data-src="https://img.php.cn/upload/manual/000/000/001/58d0e0fc74683535.jpg?x-oss-process=image/resize,m_fill,h_50,w_72" src="/static/imghw/default1.png" alt="ドリームウィーバー CS6" /> </a> <div class="phpmain_tab2_mids_info"> <a href="https://www.php.cn/ja/toolset/development-tools/469" title="ドリームウィーバー CS6" class="phpmain_tab2_mids_title"> <h3>ドリームウィーバー CS6</h3> </a> <p>ビジュアル Web 開発ツール</p> </div> </div> <div class="phpmain_tab2_mids_top"> <a href="https://www.php.cn/ja/toolset/development-tools/500" title="SublimeText3 Mac版" class="phpmain_tab2_mids_top_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" class="lazy" data-src="https://img.php.cn/upload/manual/000/000/001/58d34035e2757995.png?x-oss-process=image/resize,m_fill,h_50,w_72" src="/static/imghw/default1.png" alt="SublimeText3 Mac版" /> </a> <div class="phpmain_tab2_mids_info"> <a href="https://www.php.cn/ja/toolset/development-tools/500" title="SublimeText3 Mac版" class="phpmain_tab2_mids_title"> <h3>SublimeText3 Mac版</h3> </a> <p>神レベルのコード編集ソフト(SublimeText3)</p> </div> </div> </div> <div class="phpgenera_Details_mainR3_more"> <a href="https://www.php.cn/ja/ai">もっと見る</a> </div> </div> </div> <div class="phpgenera_Details_mainR4"> <div class="phpmain1_4R_readrank"> <div class="phpmain1_4R_readrank_top"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" onerror="this.onerror=''; this.src='/static/imghw/default1.png'" src="/static/imghw/hotarticle2.png" alt="" /> <h2>ホットトピック</h2> </div> <div class="phpgenera_Details_mainR4_bottom"> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/ja/faq/java-tutorial" title="Java チュートリアル" class="phpgenera_Details_mainR4_bottom_title">Java チュートリアル</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <div class="phpgenera_Details_mainR4_bottoms_infos"> <img src="/static/imghw/eyess.png" alt="" /> <span>1664</span> </div> <div class="phpgenera_Details_mainR4_bottoms_infos"> <img src="/static/imghw/tiezi.png" alt="" /> <span>14</span> </div> </div> </div> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/ja/faq/cakephp-tutor" title="CakePHP チュートリアル" class="phpgenera_Details_mainR4_bottom_title">CakePHP チュートリアル</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <div class="phpgenera_Details_mainR4_bottoms_infos"> <img src="/static/imghw/eyess.png" alt="" /> <span>1421</span> </div> <div class="phpgenera_Details_mainR4_bottoms_infos"> <img src="/static/imghw/tiezi.png" alt="" /> <span>52</span> </div> </div> </div> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/ja/faq/laravel-tutori" title="Laravel チュートリアル" class="phpgenera_Details_mainR4_bottom_title">Laravel チュートリアル</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <div class="phpgenera_Details_mainR4_bottoms_infos"> <img src="/static/imghw/eyess.png" alt="" /> <span>1315</span> </div> <div class="phpgenera_Details_mainR4_bottoms_infos"> <img src="/static/imghw/tiezi.png" alt="" /> <span>25</span> </div> </div> </div> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/ja/faq/php-tutorial" title="PHP チュートリアル" class="phpgenera_Details_mainR4_bottom_title">PHP チュートリアル</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <div class="phpgenera_Details_mainR4_bottoms_infos"> <img src="/static/imghw/eyess.png" alt="" /> <span>1266</span> </div> <div class="phpgenera_Details_mainR4_bottoms_infos"> <img src="/static/imghw/tiezi.png" alt="" /> <span>29</span> </div> </div> </div> <div class="phpgenera_Details_mainR4_bottoms"> <a href="https://www.php.cn/ja/faq/c-tutorial" title="C# チュートリアル" class="phpgenera_Details_mainR4_bottom_title">C# チュートリアル</a> <div class="phpgenera_Details_mainR4_bottoms_info"> <div class="phpgenera_Details_mainR4_bottoms_infos"> <img src="/static/imghw/eyess.png" alt="" /> <span>1239</span> </div> <div class="phpgenera_Details_mainR4_bottoms_infos"> <img src="/static/imghw/tiezi.png" alt="" /> <span>24</span> </div> </div> </div> </div> <div class="phpgenera_Details_mainR3_more"> <a href="https://www.php.cn/ja/faq/zt">もっと見る</a> </div> </div> </div> </div> </div> <div class="Article_Details_main2"> <div class="phpgenera_Details_mainL4"> <div class="phpmain1_2_top"> <a href="javascript:void(0);" class="phpmain1_2_top_title">Related knowledge<img src="/static/imghw/index2_title2.png" alt="" /></a> </div> <div class="phpgenera_Details_mainL4_info"> <div class="phphistorical_Version2_mids"> <a href="https://www.php.cn/ja/faq/1796797869.html" title="PHPおよびPython:さまざまなパラダイムが説明されています" class="phphistorical_Version2_mids_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/001/253/068/174490716137257.jpg?x-oss-process=image/resize,m_fill,h_207,w_330" alt="PHPおよびPython:さまざまなパラダイムが説明されています" /> </a> <a href="https://www.php.cn/ja/faq/1796797869.html" title="PHPおよびPython:さまざまなパラダイムが説明されています" class="phphistorical_Version2_mids_title">PHPおよびPython:さまざまなパラダイムが説明されています</a> <span class="Articlelist_txts_time">Apr 18, 2025 am 12:26 AM</span> <p class="Articlelist_txts_p">PHPは主に手順プログラミングですが、オブジェクト指向プログラミング(OOP)もサポートしています。 Pythonは、OOP、機能、手続き上のプログラミングなど、さまざまなパラダイムをサポートしています。 PHPはWeb開発に適しており、Pythonはデータ分析や機械学習などのさまざまなアプリケーションに適しています。</p> </div> <div class="phphistorical_Version2_mids"> <a href="https://www.php.cn/ja/faq/1796797864.html" title="PHPとPythonの選択:ガイド" class="phphistorical_Version2_mids_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/001/253/068/174490706146904.jpg?x-oss-process=image/resize,m_fill,h_207,w_330" alt="PHPとPythonの選択:ガイド" /> </a> <a href="https://www.php.cn/ja/faq/1796797864.html" title="PHPとPythonの選択:ガイド" class="phphistorical_Version2_mids_title">PHPとPythonの選択:ガイド</a> <span class="Articlelist_txts_time">Apr 18, 2025 am 12:24 AM</span> <p class="Articlelist_txts_p">PHPはWeb開発と迅速なプロトタイピングに適しており、Pythonはデータサイエンスと機械学習に適しています。 1.PHPは、単純な構文と迅速な開発に適した動的なWeb開発に使用されます。 2。Pythonには簡潔な構文があり、複数のフィールドに適しており、強力なライブラリエコシステムがあります。</p> </div> <div class="phphistorical_Version2_mids"> <a href="https://www.php.cn/ja/faq/1796797866.html" title="PHPとPython:彼らの歴史を深く掘り下げます" class="phphistorical_Version2_mids_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/001/253/068/174490710066424.jpg?x-oss-process=image/resize,m_fill,h_207,w_330" alt="PHPとPython:彼らの歴史を深く掘り下げます" /> </a> <a href="https://www.php.cn/ja/faq/1796797866.html" title="PHPとPython:彼らの歴史を深く掘り下げます" class="phphistorical_Version2_mids_title">PHPとPython:彼らの歴史を深く掘り下げます</a> <span class="Articlelist_txts_time">Apr 18, 2025 am 12:25 AM</span> <p class="Articlelist_txts_p">PHPは1994年に発信され、Rasmuslerdorfによって開発されました。もともとはウェブサイトの訪問者を追跡するために使用され、サーバー側のスクリプト言語に徐々に進化し、Web開発で広く使用されていました。 Pythonは、1980年代後半にGuidovan Rossumによって開発され、1991年に最初にリリースされました。コードの読みやすさとシンプルさを強調し、科学的コンピューティング、データ分析、その他の分野に適しています。</p> </div> <div class="phphistorical_Version2_mids"> <a href="https://www.php.cn/ja/faq/1796796853.html" title="Python vs. JavaScript:学習曲線と使いやすさ" class="phphistorical_Version2_mids_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/001/253/068/174473354083140.jpg?x-oss-process=image/resize,m_fill,h_207,w_330" alt="Python vs. JavaScript:学習曲線と使いやすさ" /> </a> <a href="https://www.php.cn/ja/faq/1796796853.html" title="Python vs. JavaScript:学習曲線と使いやすさ" class="phphistorical_Version2_mids_title">Python vs. JavaScript:学習曲線と使いやすさ</a> <span class="Articlelist_txts_time">Apr 16, 2025 am 12:12 AM</span> <p class="Articlelist_txts_p">Pythonは、スムーズな学習曲線と簡潔な構文を備えた初心者により適しています。 JavaScriptは、急な学習曲線と柔軟な構文を備えたフロントエンド開発に適しています。 1。Python構文は直感的で、データサイエンスやバックエンド開発に適しています。 2。JavaScriptは柔軟で、フロントエンドおよびサーバー側のプログラミングで広く使用されています。</p> </div> <div class="phphistorical_Version2_mids"> <a href="https://www.php.cn/ja/faq/1796796981.html" title="Sublime Code Pythonを実行する方法" class="phphistorical_Version2_mids_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/202412/09/2024120916311859115.jpg?x-oss-process=image/resize,m_fill,h_207,w_330" alt="Sublime Code Pythonを実行する方法" /> </a> <a href="https://www.php.cn/ja/faq/1796796981.html" title="Sublime Code Pythonを実行する方法" class="phphistorical_Version2_mids_title">Sublime Code Pythonを実行する方法</a> <span class="Articlelist_txts_time">Apr 16, 2025 am 08:48 AM</span> <p class="Articlelist_txts_p">PythonコードをSublimeテキストで実行するには、最初にPythonプラグインをインストールし、次に.pyファイルを作成してコードを書き込み、Ctrl Bを押してコードを実行する必要があります。コードを実行すると、出力がコンソールに表示されます。</p> </div> <div class="phphistorical_Version2_mids"> <a href="https://www.php.cn/ja/faq/1796796768.html" title="vscodeでコードを書く場所" class="phphistorical_Version2_mids_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/202407/31/2024073120544824396.jpg?x-oss-process=image/resize,m_fill,h_207,w_330" alt="vscodeでコードを書く場所" /> </a> <a href="https://www.php.cn/ja/faq/1796796768.html" title="vscodeでコードを書く場所" class="phphistorical_Version2_mids_title">vscodeでコードを書く場所</a> <span class="Articlelist_txts_time">Apr 15, 2025 pm 09:54 PM</span> <p class="Articlelist_txts_p">Visual Studioコード(VSCODE)でコードを作成するのはシンプルで使いやすいです。 VSCODEをインストールし、プロジェクトの作成、言語の選択、ファイルの作成、コードの書き込み、保存して実行します。 VSCODEの利点には、クロスプラットフォーム、フリーおよびオープンソース、強力な機能、リッチエクステンション、軽量で高速が含まれます。</p> </div> <div class="phphistorical_Version2_mids"> <a href="https://www.php.cn/ja/faq/1796798371.html" title="Golang vs. Python:パフォーマンスとスケーラビリティ" class="phphistorical_Version2_mids_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/001/253/068/174499313063650.jpg?x-oss-process=image/resize,m_fill,h_207,w_330" alt="Golang vs. Python:パフォーマンスとスケーラビリティ" /> </a> <a href="https://www.php.cn/ja/faq/1796798371.html" title="Golang vs. Python:パフォーマンスとスケーラビリティ" class="phphistorical_Version2_mids_title">Golang vs. Python:パフォーマンスとスケーラビリティ</a> <span class="Articlelist_txts_time">Apr 19, 2025 am 12:18 AM</span> <p class="Articlelist_txts_p">Golangは、パフォーマンスとスケーラビリティの点でPythonよりも優れています。 1)Golangのコンピレーションタイプの特性と効率的な並行性モデルにより、高い並行性シナリオでうまく機能します。 2)Pythonは解釈された言語として、ゆっくりと実行されますが、Cythonなどのツールを介してパフォーマンスを最適化できます。</p> </div> <div class="phphistorical_Version2_mids"> <a href="https://www.php.cn/ja/faq/1796797229.html" title="メモ帳でPythonを実行する方法" class="phphistorical_Version2_mids_img"> <img onerror="this.onerror=''; this.src='/static/imghw/default1.png'" src="/static/imghw/default1.png" class="lazy" data-src="https://img.php.cn/upload/article/202405/29/2024052914541688364.jpg?x-oss-process=image/resize,m_fill,h_207,w_330" alt="メモ帳でPythonを実行する方法" /> </a> <a href="https://www.php.cn/ja/faq/1796797229.html" title="メモ帳でPythonを実行する方法" class="phphistorical_Version2_mids_title">メモ帳でPythonを実行する方法</a> <span class="Articlelist_txts_time">Apr 16, 2025 pm 07:33 PM</span> <p class="Articlelist_txts_p">メモ帳でPythonコードを実行するには、Python実行可能ファイルとNPPEXECプラグインをインストールする必要があります。 Pythonをインストールしてパスを追加した後、nppexecプラグインでコマンド「python」とパラメーター "{current_directory} {file_name}"を構成して、メモ帳のショートカットキー「F6」を介してPythonコードを実行します。</p> </div> </div> <a href="https://www.php.cn/ja/be/" class="phpgenera_Details_mainL4_botton"> <span>See all articles</span> <img src="/static/imghw/down_right.png" alt="" /> </a> </div> </div> </div> </main> <footer> <div class="footer"> <div class="footertop"> <img src="/static/imghw/logo.png" alt=""> <p>福祉オンライン PHP トレーニング,PHP 学習者の迅速な成長を支援します!</p> </div> <div class="footermid"> <a href="https://www.php.cn/ja/about/us.html">私たちについて</a> <a href="https://www.php.cn/ja/about/disclaimer.html">免責事項</a> <a href="https://www.php.cn/ja/update/article_0_1.html">Sitemap</a> </div> <div class="footerbottom"> <p> © php.cn All rights reserved </p> </div> </div> </footer> <input type="hidden" id="verifycode" value="/captcha.html"> <script>layui.use(['element', 'carousel'], function () {var element = layui.element;$ = layui.jquery;var carousel = layui.carousel;carousel.render({elem: '#test1', width: '100%', height: '330px', arrow: 'always'});$.getScript('/static/js/jquery.lazyload.min.js', function () {$("img").lazyload({placeholder: "/static/images/load.jpg", effect: "fadeIn", threshold: 200, skip_invisible: false});});});</script> <script src="/static/js/common_new.js"></script> <script type="text/javascript" src="/static/js/jquery.cookie.js?1746722712"></script> <script src="https://vdse.bdstatic.com//search-video.v1.min.js"></script> <link rel='stylesheet' id='_main-css' href='/static/css/viewer.min.css?2' type='text/css' media='all' /> <script type='text/javascript' src='/static/js/viewer.min.js?1'></script> <script type='text/javascript' src='/static/js/jquery-viewer.min.js'></script> <script type="text/javascript" src="/static/js/global.min.js?5.5.53"></script> <script> var _paq = window._paq = window._paq || []; /* tracker methods like "setCustomDimension" should be called before "trackPageView" */ _paq.push(['trackPageView']); _paq.push(['enableLinkTracking']); (function () { var u = "https://tongji.php.cn/"; _paq.push(['setTrackerUrl', u + 'matomo.php']); _paq.push(['setSiteId', '9']); var d = document, g = d.createElement('script'), s = d.getElementsByTagName('script')[0]; g.async = true; g.src = u + 'matomo.js'; s.parentNode.insertBefore(g, s); })(); </script> <script> // top layui.use(function () { var util = layui.util; util.fixbar({ on: { mouseenter: function (type) { layer.tips(type, this, { tips: 4, fixed: true, }); }, mouseleave: function (type) { layer.closeAll("tips"); }, }, }); }); document.addEventListener("DOMContentLoaded", (event) => { // 定义一个函数来处理滚动链接的点击事件 function setupScrollLink(scrollLinkId, targetElementId) { const scrollLink = document.getElementById(scrollLinkId); const targetElement = document.getElementById(targetElementId); if (scrollLink && targetElement) { scrollLink.addEventListener("click", (e) => { e.preventDefault(); // 阻止默认链接行为 targetElement.scrollIntoView({ behavior: "smooth" }); // 平滑滚动到目标元素 }); } else { console.warn( `Either scroll link with ID '${scrollLinkId}' or target element with ID '${targetElementId}' not found.` ); } } // 使用该函数设置多个滚动链接 setupScrollLink("Article_Details_main1L2s_1", "article_main_title1"); setupScrollLink("Article_Details_main1L2s_2", "article_main_title2"); setupScrollLink("Article_Details_main1L2s_3", "article_main_title3"); setupScrollLink("Article_Details_main1L2s_4", "article_main_title4"); setupScrollLink("Article_Details_main1L2s_5", "article_main_title5"); setupScrollLink("Article_Details_main1L2s_6", "article_main_title6"); // 可以继续添加更多的滚动链接设置 }); window.addEventListener("scroll", function () { var fixedElement = document.getElementById("Article_Details_main1Lmain"); var scrollTop = window.scrollY || document.documentElement.scrollTop; // 兼容不同浏览器 var clientHeight = window.innerHeight || document.documentElement.clientHeight; // 视口高度 var scrollHeight = document.documentElement.scrollHeight; // 页面总高度 // 计算距离底部的距离 var distanceToBottom = scrollHeight - scrollTop - clientHeight; // 当距离底部小于或等于300px时,取消固定定位 if (distanceToBottom <= 980) { fixedElement.classList.remove("Article_Details_main1Lmain"); fixedElement.classList.add("Article_Details_main1Lmain_relative"); } else { // 否则,保持固定定位 fixedElement.classList.remove("Article_Details_main1Lmain_relative"); fixedElement.classList.add("Article_Details_main1Lmain"); } }); </script> <script> document.addEventListener('DOMContentLoaded', function() { const mainNav = document.querySelector('.Article_Details_main1Lmain'); const header = document.querySelector('header'); if (mainNav) { window.addEventListener('scroll', function() { const scrollPosition = window.scrollY; if (scrollPosition > 84) { mainNav.classList.add('fixed'); } else { mainNav.classList.remove('fixed'); } }); } }); </script> </body> </html>