

ゼロから数百億までのインターネット金融アーキテクチャの開発の歴史

振り返ってみると、会社の設立から最初のコード行が入力されてからほぼ 3 年が経ち、プラットフォームの技術アーキテクチャと技術システムも 4 回の大きなアップグレードと変革を経ました (現在、第 4 世代のアーキテクチャ システムが進行中です)。 )、年末が近づいているので、私も時間をかけて、取引ゼロだった中小企業が取引量 100 億を超えるまで成長した中小企業の背後にある技術の変化を振り返りたいと思います。
概要
100億元を超えるインターネット金融業界では、実際には大きなプラットフォームではなく、実際には、アーキテクチャのアップグレードには大きなビジネスの進歩が伴います。前世代のシステムアーキテクチャは、事業開発の過程でいくつかの優れた開発事例が蓄積されており、次世代システムの開発においてはアーキテクチャのアップグレードが強力に推進されます。移行をスムーズに行える一方で、社内リソースが強力なサポートを提供できると同時に、技術パートナーは最先端のテクノロジーを使用して開発の達成感を得ることができます。 、約 9 か月に 1 回、システム アーキテクチャを現在の構造にアップグレードできます。
多くのネチズンは、プラットフォームの TPS はどれくらいですか、最大同時実行数はどれくらいですか、パフォーマンスはどうですか、とよく尋ねます。正直に言うと、私たちは小規模な会社であり、最も誇張されているのは、数万人が入札を競っているということです。同時に、中規模のインターネットとして、金融プラットフォームがしなければならないことは本当にたくさんあります。明確に言えるのは、これらのパラメータだけではありません。私たちはハイエンドのプラットフォームではありません。また、私たちが使用しているテクノロジーも、現在は比較的主流のオープンソース製品ですが、会社の継続的な開発の過程で多くの問題にも遭遇しました。そのため、より主流のオープンソース ソリューションを使用するよう最善を尽くしてきました。システム全体を構築するのに適しています。ここでは、プラットフォームの開発の背景にあるテクノロジーのアップグレードについて共有し、さらに多くの提案をしたいと考えています。
私たちはアーキテクチャに 4 つの大きな変更を加えました。各世代のアーキテクチャは次の一文に要約されています。
第 1 世代アーキテクチャの特徴: ビジネスが比較的集中しており、機能は投資および財務管理のニーズに対応し、迅速な立ち上げが可能です。
第 2 世代アーキテクチャの特徴: 分散システムの変革、プラットフォーム化の具体化、さまざまな垂直型ビジネス システムの構築と立ち上げ、ユーザー投資の大幅な充実、ビッグ データ プラットフォームの研究と活用
第 3 世代アーキテクチャの特徴。Zookeeper を登録センターとして使用し、dubbo を監視およびディスパッチング センターとして使用し、シングル サインオンを実現し、権限制御に hiro を使用します。
第 4 世代アーキテクチャの特徴: 第 4 世代アーキテクチャの技術サポートとして springboot+springcloud テクノロジを使用して、マイクロサービス開発モデルを完全に有効にします。
詳しい紹介は以下
第一世代のシステムアーキテクチャ
2014 年はインターネット金融元年と見なされるべきですが、これまで多くのインターネット企業が生き残るためにさまざまなモデルを使用していましたが、2014 年に最初に人気を博したのは Pingdaizhijia と Pingdao Tianyan でした。この種のサードパーティ Web サイトのトラフィックが突然増加し、その後、さまざまなインターネット金融会社が XXX ドルの投資を受けたという報道が増え、その方針が徐々に明らかになりました。私たちを含め、大企業(団体)もこのブームに乗じてフォローアップしてきました。
第一世代のシステムの主な目的は、時間を確保することであり、その時までにモバイルの波がすでに始まっていたため、同社はシステムの立ち上げを優先することにしました。モバイル版、Webサイトは当面検討できませんでした。当時、同社には PHP と Java という 2 つの開発言語の技術的余裕があり、PHP は迅速な開発に大きな利点を持っていたため、フロントエンド PHP + バックエンド Java のモデルを採用することにしました。システムは 3 つの層に分かれています: ユーザー層: Android および IOS モバイル端末; インターフェイス層: PHP がユーザー インターフェイスとトランザクション インターフェイスを提供します; バックエンド: バックエンドには、バックグラウンドとタイミング システムの 2 つの部分があります。バックエンドは PHP 開発とインターフェイス層を使用して 1 つのシステムを共有し、もう 1 つはタイミング システムであり、利息の計算、配当金の分配、期限切れおよびその他のスケジュールされたタスクを担当し、Java を使用して開発されます。
基本的なサービスとミドルウェアについては、mysql は最も基本的なマスター/スレーブ サポートを提供します。第一世代のシステムは mysql のメイン データベースのみを使用し、スレーブ データベースはユーザーの同時実行の問題を処理するためにのみ使用されます。入札、この部分のみが流通市場の転送マッチングやその他の非同期メッセージ通知に使用されます。プロジェクトのデプロイ: PHP は Apache を使用してデプロイされ、タイミング サービスはアプリケーション サーバーとして tomcat6 を使用し、フロントエンドの Apache ロードとして lvs が使用されます。基本的に、これらのテクノロジは第 1 世代のアーキテクチャ図です。システム。

初代システムの稼働後、特にWebサイトやH5(モバイルブラウザまたはWeChat)システムの構築が目立つようになった同社は、インターネット金融会社として公式Webサイトを持たないことに耐えられず、WebサイトやH5の開発に着手した。この期間中、PHP がこれまで行っていたバックエンドを取り出し、Java を使用して再計画されました。これまでのところ、PHP は Web サイト、APP インターフェイス、および H5 のコア トランザクションの 3 つのシステムを担当しています。 3 つのシステムでは、Java が管理およびタイミング サービスのバックエンドを担当します。このアーキテクチャを一般に 1.1 世代アーキテクチャと呼びます。

第 1.1 世代のシステム アーキテクチャ図、緑色の部分が変更された部分です
第一世代のシステムの欠点は、業務が集中しすぎ、立ち上げが急ぐこと、後期に多くの問題が発生することです。
第二世代のシステムアーキテクチャ
第 2 世代システムの背景には、企業の事業量の急速な発展に伴い、初期段階で負っていた多くの技術的負債が爆発的に増加し、最も深刻な問題は個人への配当の繰り返しでした。と色々と叱られたのは今でも記憶に新しいです。一方で、さまざまな事業部門からは常に需要があり、会社の製品も常に需要があるため、現段階では垂直型ビジネスシステムの開発と並行して、さまざまな生産上の問題の解決に追われています。初代のシステムはクローズドで開発していたので、復帰してからまた発売するのが大変で、本当に辛かったです。
最初にオンライン化された垂直サブシステムは契約システムでした。当時は、ユーザーが入札を行っても契約は成立しませんでした。多くのユーザーは非常に不安を抱えていました。その後、契約システムだけでも 3 つのバージョンに変更されました。最初のバージョンでは PDF のみが生成され、第 2 段階では電子署名が追加され、カスタマイズされて動的に生成された PDF が開発されました。ユーザー招待、投資およびその他の生産ポイントを現金クーポンなどと交換するために使用できます。メッセージ システムを抽出します。サイト メッセージ、テキスト メッセージ、電子メールなど。オンライン監視システム、ビジネス監視およびサービス監視、およびビジネスを開始します。失敗の早期警告、各事業部門は要求を高め、オンライン化を継続する 金融システム:財務スタッフが金額を計算し、販売のための販売システムを開発し、外部アクセスシステムを開発する。多くのサードパーティ システムを使用します。
第一世代のシステムは急いで構築され、製品のインターフェースはひどいものでした。その後、フロントエンド システムのニーズに応えて、Web サイト 2.0、APP2.0、H52.0 の計画が始まりました。プロジェクトや企業の発表、ニュースなどを公開するバックエンドのシステム。一般に、第 2 世代の製品側は、多くのビッグデータ分析のニーズを計画し、投資の優先順位と投資金額が完了した後、公式 Web サイトに表示されます。フロントエンドでは地図を使って表示するほか、個人向けの返済や収集したデータの分析など、大量のデータを実行する必要があるため、オフラインで処理できるように設計されています。計画中に、データは mysql スレーブ ライブラリから mongodb クラスターに同期され、mongdo の Mapreduce テクノロジーが大量のデータを処理するために使用されます。

MySQL は tungsten-relicator を使用して mongodb にリアルタイムで同期され、mysql サーバー側で監視エージェントを起動し、同時にサーバー側でも mysql の binlog ログを監視します。上の図に示すように、データが変更された後、サーバーがそれを解析して mongodb クラスターに挿入します。それを紹介する記事: ビッグ データの実践 - データ同期 tungsten-relicator (mysql ->mongo)、実際、このツールの使用は特に安定していませんが、幸いなことに、最初はそれほど多くのオプションはありませんでした。徐々に慣れてきたら安定してきました。
データ クリーニング システムの開発に golang を大胆に使用しました。当時使用していた golang のバージョンは 1.3 でしたが、幸いにも golang 言語自体をトレーニングすることができました。非常にシンプルで効率的ですが、N を踏んでしまいました。たくさんの落とし穴がありましたが、最終的には予定どおりに本番環境に投入しました。その後、beego フレームワークに基づいたバックエンドを開発するために golang を使用しました。その後、ビッグデータ分析システムは別の世代にアップグレードされ、UI ユーザー層は、activeMQ 送信を通じてユーザー データを収集し、最終的に mongodb に保存しました。データ、クリーンアップされた結果は、フロントエンド ビジネス システムで使用するために結果データベースに保存されました。その後、beego+echart を使用して新しいバージョンのデータ分析システムが構築されました。
ビッグデータシステムのアーキテクチャ図

バックエンド データベースへの負荷が増大し続けるため、バックエンド管理システムとビジネス システムはマスターとスレーブから分離され、バックエンド管理システムはキャッシュを追加し、独立したイメージ サーバーを開始しました。 nginx を使用して構築; 第 2 世代のシステム開発 その過程では、多くの活動がオンラインで開始され、会社の最も急速な成長段階でもありました。
第 2 世代のシステム アーキテクチャ図:

すぐに要約しましょう:
第二世代アーキテクチャは、さまざまなビジネスシステムを立ち上げ、マスターとスレーブを分離し、将来のより多くのデータ処理のための技術的基盤を提供するビッグデータプラットフォームを構築しました
短所: 各ビジネスシステムが分割されると、各プロジェクト間の呼び出しが複雑になります。多くのバックエンドシステムがあり、プラットフォームの動作監視を完了するために各システム間で操作を切り替える必要があります。
第 2 世代システムの開発が完了した後、私たちには 3 つの厄介な問題が残されました。1 つ目は、ビジネス システムが増加し続けるにつれて、第 3 世代システムの初期にはシステム間の呼び出し関係が急激に増加したことです。多くの基本コンポーネントが追加されているため、この問題はさらに悪化しています。2 番目の問題は 1 番目の問題を補完するものであり、システム間の呼び出し関係が多すぎるため、サブシステムの 1 つを移動する場合は、その構成ファイルを変更する必要がある可能性があります。関連するシステムを削除してサービスを再起動します。多くの場合、1 つのシステムを更新するために他のシステムも受動的に更新する必要があり、問題が発生した場合の運用開始と切り替えが複雑になります。各サブシステムには独自のアカウント センターがあり、ビジネス スタッフは日々の業務を完了するために何度もログインする必要があるため、この問題はますます顕著になってきています。
そこで、調査とシステムの選択などを開始しました。解決すべき最初の課題は、SOA サービス ガバナンスを導入し、サービスの登録と検出を通じてシステム間のデカップリングを解決することでした。当時、私たちは多くの検討を行い、最終的にダボを選択したのは他に理由がありませんでした。多くの人が基本的な水を使って水の中を歩きました。 2番目の問題を解決するために、構成センターを導入しました。そのとき、360のQihoo360/QConf、Springのspring-cloud-config、Taobaoのdiamond、Baiduのdisconfを調査しました。長い間悩んだ結果、最終的にdisconfを選択しました。これは Spring Cloud に最適でしたが、ここから Spring-cloud と Spring-boot が第 4 世代のアーキテクチャ選択の基礎を築いていることに気づきました。 3 番目の問題を解決するのはアカウント センターです。アカウント センターは、シングル サインオンを実装するために cas を使用し、権限制御に hiro を使用し、ログイン後の権限リストなどのサーバー インターフェイスを提供するために dubbo を使用します。
変換後のアーキテクチャ図

その後、同社はクラウドファンディング プラットフォームの構築を開始し、今回のシステムは完全に Java 言語で開発され、アプリ側はすべての第 1 レベルのページがネイティブで開発され、第 2 レベルのページはすべてネイティブで開発されました。このモデルでは、すべてのバックエンドがサービスに dubbo を使用します。最終的なアーキテクチャは次のとおりです。

第 3 世代システムでは、SOA サービス ガバナンスが導入され、統合されたアカウント センターと基本コンポーネントが導入されました。欠点は、開発環境がより複雑であることです。
人々は常に不満を抱いており、テクノロジーは常に最高のアーキテクチャ システムを使用することを望んでいます。第 3 世代のシステム アーキテクチャの開発中に、私は Spring Cloud と Spring Boot について学びました。その後、その利便性をますます認識するようになりました。 Spring Boot は、開発が迅速であるという利点が非常に気に入っています。また、Spring クラウド システムは、マイクロサービスの概念が常に提案されています。一方、国は、P2P 企業に銀行への預金を厳しく要求し始めています。銀行の関連インターフェースを分析した結果、ルールに厳密に従うには、同時にシステムの大幅な変革が必要であることがわかりました。同社は規制要件を満たしており、Baitiao 関連製品も開発しています。これも大きなプロジェクトです。上記の 2 つの背景を活用して、銀行預金と Baitiao のプロジェクトに取り組みながら、マイクロサービスを本格的に採用することにしました。
なぜ dubbo を放棄して Spring Cloud を全面的に採用するのかというと、3 つの理由があります。 1. Dubbo は長年更新されておらず、Spring Cloud は常に更新およびアップグレードされています。 2. Dubbo は主にサービスの管理と監視を行います。クラウドはほぼすべてのマイクロサービスを考慮します。統合された構成センターやルーティング センターなど、あらゆる側面が必要です。3. Spring クラウドは非侵入的であり、他の Spring プロジェクトと完全に統合されているため、開発がより効率的になります。
Spring Boot + Spring Cloud を使用して変革を行うことを選択し、マイクロサービス テクノロジの選択が決まりました。結局のところ、新世代のシステム変革が同時に元のビジネスに影響を与えてはなりません。最も重要なことは、元のシステムが分散開発モデルに従って開発されているにもかかわらず、一部のシステムは古いシステムのため、依然としてデータベースを共有しており、各独立したサブシステムが独自の独立したライブラリ操作を必要とすることです。システムはサブシステム データを変更またはクエリする必要があり、サービス間インターフェイス呼び出しを通じてそれを取得する必要があります。したがって、新しく開発されたプロジェクトと変換が必要なプロジェクトから Springcloud プロジェクトを開始する予定であり、他のシステムは一時的にルーター モードを介して通信します。 最終的なシステム アーキテクチャ図は次のとおりです。

アーキテクチャの道に終着点はありません。アーキテクチャのアップグレードは、ビジネスをより良くサポートすることです。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7467
7467
 15
1376
52
77
11
18
20
15
1376
52
77
11
18
20

 深層学習アーキテクチャの比較分析
May 17, 2023 pm 04:34 PM
深層学習アーキテクチャの比較分析
May 17, 2023 pm 04:34 PM
深層学習の概念は人工ニューラル ネットワークの研究に由来しており、複数の隠れ層を含む多層パーセプトロンが深層学習構造です。ディープラーニングは、低レベルの特徴を組み合わせて、データのカテゴリや特性を表すより抽象的な高レベルの表現を形成します。データの分散された特徴表現を検出できます。ディープラーニングは機械学習の一種であり、機械学習は人工知能を実現する唯一の方法です。では、さまざまな深層学習システム アーキテクチャの違いは何でしょうか? 1. 完全接続ネットワーク (FCN) 完全接続ネットワーク (FCN) は、一連の完全接続層で構成され、各層のすべてのニューロンが別の層のすべてのニューロンに接続されています。その主な利点は、「構造に依存しない」ことです。つまり、入力に関する特別な仮定が必要ありません。この構造にとらわれないことにより、完全な
 この「間違い」は実際には間違いではありません。Transformer アーキテクチャ図の何が「間違っている」のかを理解するには、4 つの古典的な論文から始めてください。
Jun 14, 2023 pm 01:43 PM
この「間違い」は実際には間違いではありません。Transformer アーキテクチャ図の何が「間違っている」のかを理解するには、4 つの古典的な論文から始めてください。
Jun 14, 2023 pm 01:43 PM
少し前に、Transformer のアーキテクチャ図と Google Brain チームの論文「Attending IsAllYouNeed」のコードとの間の矛盾を指摘したツイートが多くの議論を引き起こしました。セバスチャンの発見は意図せぬ間違いだったのではないかと考える人もいるが、これもまた驚くべきことである。結局のところ、Transformer 論文の人気を考慮すると、この矛盾については何千回も言及されるべきでした。 Sebastian Raschka氏はネチズンのコメントに答えて、「最もオリジナルな」コードは確かにアーキテクチャ図と一致していたが、2017年に提出されたコードバージョンは修正されたものの、アーキテクチャ図は同時に更新されていなかったと述べた。これが議論の「齟齬」の根本原因でもある。
 マルチパス、マルチドメイン、すべてを網羅! Google AI がマルチドメイン学習一般モデル MDL をリリース
May 28, 2023 pm 02:12 PM
マルチパス、マルチドメイン、すべてを網羅! Google AI がマルチドメイン学習一般モデル MDL をリリース
May 28, 2023 pm 02:12 PM
視覚タスク (画像分類など) の深層学習モデルは、通常、単一の視覚領域 (自然画像やコンピューター生成画像など) からのデータを使用してエンドツーエンドでトレーニングされます。一般に、複数のドメインのビジョン タスクを完了するアプリケーションは、個別のドメインごとに複数のモデルを構築し、それらを個別にトレーニングする必要があります。データは異なるドメイン間で共有されません。推論中、各モデルは特定のドメインの入力データを処理します。たとえそれらが異なる分野を指向しているとしても、これらのモデル間の初期層のいくつかの機能は類似しているため、これらのモデルの共同トレーニングはより効率的です。これにより、遅延と消費電力が削減され、各モデル パラメーターを保存するためのメモリ コストが削減されます。このアプローチはマルチドメイン学習 (MDL) と呼ばれます。さらに、MDL モデルは単一モデルよりも優れたパフォーマンスを発揮します。
 Spring Data JPA のアーキテクチャと動作原理は何ですか?
Apr 17, 2024 pm 02:48 PM
Spring Data JPA のアーキテクチャと動作原理は何ですか?
Apr 17, 2024 pm 02:48 PM
SpringDataJPA は JPA アーキテクチャに基づいており、マッピング、ORM、トランザクション管理を通じてデータベースと対話します。そのリポジトリは CRUD 操作を提供し、派生クエリによりデータベース アクセスが簡素化されます。さらに、遅延読み込みを使用して必要な場合にのみデータを取得するため、パフォーマンスが向上します。
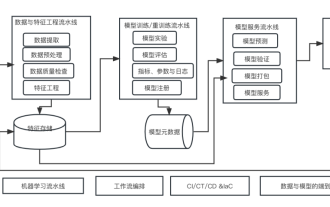 機械学習システムアーキテクチャの 10 の要素
Apr 13, 2023 pm 11:37 PM
機械学習システムアーキテクチャの 10 の要素
Apr 13, 2023 pm 11:37 PM
今は AI エンパワーメントの時代であり、機械学習は AI を実現するための重要な技術的手段です。では、普遍的な機械学習システム アーキテクチャは存在するのでしょうか?経験豊富なプログラマの認識範囲内では、特にシステム アーキテクチャに関しては何でもありません。ただし、ほとんどの機械学習駆動システムまたはユースケースに適用できる場合、スケーラブルで信頼性の高い機械学習システム アーキテクチャを構築することは可能です。機械学習のライフサイクルの観点から見ると、このいわゆるユニバーサル アーキテクチャは、機械学習モデルの開発から、トレーニング システムやサービス システムの運用環境への展開まで、主要な機械学習段階をカバーします。このような機械学習システムのアーキテクチャを 10 個の要素の次元から記述してみることができます。 1.
 1.3ミリ秒には1.3ミリ秒かかります。清華社の最新オープンソース モバイル ニューラル ネットワーク アーキテクチャ RepViT
Mar 11, 2024 pm 12:07 PM
1.3ミリ秒には1.3ミリ秒かかります。清華社の最新オープンソース モバイル ニューラル ネットワーク アーキテクチャ RepViT
Mar 11, 2024 pm 12:07 PM
論文のアドレス: https://arxiv.org/abs/2307.09283 コードのアドレス: https://github.com/THU-MIG/RepViTRepViT は、モバイル ViT アーキテクチャで優れたパフォーマンスを発揮し、大きな利点を示します。次に、この研究の貢献を検討します。記事では、主にモデルがグローバル表現を学習できるようにするマルチヘッド セルフ アテンション モジュール (MSHA) のおかげで、軽量 ViT は一般的に視覚タスクにおいて軽量 CNN よりも優れたパフォーマンスを発揮すると述べられています。ただし、軽量 ViT と軽量 CNN のアーキテクチャの違いは十分に研究されていません。この研究では、著者らは軽量の ViT を効果的なシステムに統合しました。
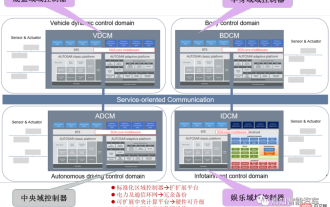 SOA におけるソフトウェア アーキテクチャ設計とソフトウェアとハードウェアの分離方法論
Apr 08, 2023 pm 11:21 PM
SOA におけるソフトウェア アーキテクチャ設計とソフトウェアとハードウェアの分離方法論
Apr 08, 2023 pm 11:21 PM
次世代の集中電子および電気アーキテクチャでは、セントラル + ゾーンの中央コンピューティング ユニットと地域コントローラー レイアウトの使用が、さまざまな OEM または Tier1 プレーヤーにとって必須のオプションとなっています。中央コンピューティング ユニットのアーキテクチャに関しては、3 つあります。方法: SOC の分離、ハードウェアの分離、ソフトウェアの仮想化。集中型の中央コンピューティング ユニットは、自動運転、スマート コックピット、車両制御の 3 つの主要領域の中核となるビジネス機能を統合し、標準化された地域コントローラーは、配電、データ サービス、地域ゲートウェイの 3 つの主要な役割を担います。したがって、中央演算装置には高スループットのイーサネット スイッチが統合されます。車両全体の統合度がますます高くなるにつれて、より多くの ECU 機能が徐々に地域コントローラーに吸収されるようになります。そしてプラットフォーム化
 Golang フレームワーク アーキテクチャの学習曲線はどれくらい急ですか?
Jun 05, 2024 pm 06:59 PM
Golang フレームワーク アーキテクチャの学習曲線はどれくらい急ですか?
Jun 05, 2024 pm 06:59 PM
Go フレームワーク アーキテクチャの学習曲線は、Go 言語とバックエンド開発への慣れ、選択したフレームワークの複雑さ、つまり Go 言語の基本の十分な理解によって決まります。バックエンドの開発経験があると役立ちます。フレームワークの複雑さが異なると、学習曲線も異なります。
