

Java の改善 (13) -----文字列

文字列操作はコンピュータープログラミングにおいて最も一般的な動作であることが証明できます。
1. String
まず第一に、String は基本データ型ではなくオブジェクトであり、不変オブジェクトであることを明確にする必要があります。ソース コードを見ると、String クラスが Final であることがわかります (もちろん継承できません)。JDK ドキュメントを見ると、String オブジェクトを変更するほぼすべての操作で、実際には新しいクラスが作成されることがわかります。文字列オブジェクト。
String はオブジェクトなので、初期化前の値は null です。 ""、null、new String() の違いについて言及する必要があります。 null は文字列がまだ新しくないことを意味します。つまり、オブジェクトへの参照がまだ作成されておらず、メモリ空間が割り当てられていないことを意味します。ただし、"" と new String() は、文字列が新しいことを示します。内部的には空ですが、オブジェクトへの参照にはメモリ領域の割り当てが必要です。例: 空のグラス、中には空気があるので、中には何もないとは言えません。もちろん、真空、ヌル、「」にすることもできます。 "、 new String() の違いは真空と空気のようなものです。
string には非常に特別な場所があります。それが string プールです。 string オブジェクトを作成するときは、まず、文字列プールがあるかどうかを確認します。文字列プールに同じ値を持つ文字列が存在する場合は、それを作成せず、オブジェクトへの参照を文字列プールに直接入れます。このメカニズムは、効率を向上させ、メモリ領域の使用量を削減できるため、必要な場合を除き、直接割り当て (つまり、String s="aa") を使用することをお勧めします。文字列オブジェクトが作成されます (つまり、文字列 s = 新しい文字列("aa"))。
文字列の使用は次の側面にすぎません:
1. 文字列の比較
------内容が同じかどうかの判定?
CompareToIgno reCase(String int) ------- 比較するときに文字の大文字と小文字を無視します。
== ------ 内容とアドレスが同じかどうかを判断します。
equalsIgnoreCase() ------ 大文字と小文字を区別せずに内容が同じかどうかを判定します。
regionMatches() ------ 文字列の一部が同じかどうかを比較します (詳細については API を参照してください)。
2. 文字列検索
charAt(intindex) -------指定されたインデックスインデックス位置にある文字を返します。インデックス範囲は 0 から始まります。
indexOf(String str)-----文字列の先頭から str を取得し、最初に出現する位置を返します。出現しない場合は、-1 を返します。 ️ indexOf(String str, int fromIndex);-----文字列の fromIndex 番目の文字から始まる str を取得します。
lastIndexOf(String str)-----最後の出現位置を検索します。
lastIndexOf(String str, int fromIndex)----文字列の fromIndex 番目の文字から最後に出現する位置を検索します。
starWith(String prefix, int toffset)-----指定されたインデックスから始まるこの文字列の部分文字列が指定されたプレフィックスで始まるかどうかをテストします。
starWith(String prefix)------この文字列が指定されたプレフィックスで始まるかどうかをテストします。
endsWith(String suffix)------この文字列が指定されたサフィックスで終わるかどうかをテストします。
3. 文字列インターセプト
begin public String subString(intIndex)-----この文字列部分文字列の 1 つである新しい文字列を返します。 IPublic String Substring (int Beginindex, int Endindex) ------ 返される戻り文字列は、Beginindex から Endindex-1 までの文字列です。
4. 文字列置換
public String replace(char oldChar, char newChar)。
public String replace(CharSequence target,CharSequence replace)------ 原来の etarget 子配列置換を置換配列に置き換え、新しい串を返します。
public String replaceAll(String regex, String replace)------正規表現を使用して文字列を照合します。 replaceAll の最初のパラメータは正規表現であることに注意してください。私はこれで非常に苦労しました。
5. その他のメソッドについては、API を参照してください
2. StringBuffer
StringBuffer は、String と同様に、格納するために使用されます。 StringBuffer の場合、文字列の処理時に変更しても新しい文字列が生成されないため、メモリの点で String よりも優れています。使用法。
実際、StringBuffer の多くのメソッドは String クラスのメソッドに似ており、それらが表す関数は、変更するときに StringBuffer 自体が変更されるのに対し、String クラスは新しいオブジェクトを生成する点を除いて、ほぼまったく同じです。これが両者の最大の違いです。
同時に、StringBuffer は = を使用して初期化することはできません。StringBuffer インスタンスを生成する必要があります。つまり、その構築メソッドを通じて初期化する必要があります。
StringBuffer の使用に関しては、追加、変更、削除などの文字列の変更に重点を置いています。 対応するメソッドは次のとおりです:1: 指定されたコンテンツを追加します。現在の StringBuffer オブジェクトの最後では、文字列の連結と同様に、StringBuffer オブジェクトの内容が変更されます。
2. insert: このメソッドは主に StringBuffer オブジェクトにコンテンツを挿入します。
3. delete: このメソッドは主に StringBuffer オブジェクトのコンテンツを削除するために使用されます。
inStringBuilder の
StringBuilder も StringBuffer とは異なり、安全でないスレッドであるため、一般に StringBuffer よりも速度が優れています。 StringBuffer と同様、StringBuider の主な操作も追加メソッドと挿入メソッドです。どちらのメソッドも、指定されたデータを効果的に文字列に変換し、その文字列の文字を文字列ジェネレーターに追加または挿入します。
上記は String、StringBuffer、StringBuilder の簡単な紹介に過ぎません。実際には、これら 3 つの違いを明確にすることによってのみ、これらをより良く使用できるようになります。
4. String、StringBuffer、StringBuilderの正しい使い方 始めましょう 以下の表を参照してください。 :
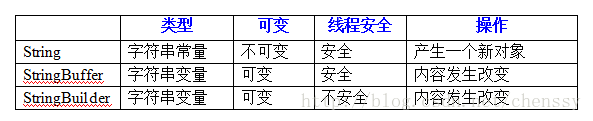
ここで String がスレッドセーフであるかどうかについてはよくわかりません。その理由は次のとおりです。文字列は不変であり、すべての操作でその値を変更することはできません。スレッドセーフであるかどうかを判断するのは非常に困難です。しかし、スレッドが安全かどうかを主張する場合、コンテンツは不変であるため、スレッドは常に安全です。
使用に関しては、String を変更するたびに新しいオブジェクトが必要となるため、頻繁に内容を変更する必要がある文字列には StringBuffer または StringBuilder を選択するのが最善です。StringBuffer の場合、各操作は StringBuffer オブジェクトに対して実行されます。 StringBuffer は、それ自体では新しいオブジェクトを生成しないため、文字列の内容が頻繁に変更される状況に特に適しています。
ただし、すべての String 文字列操作が StringBuffer よりも遅いわけではありません。一部の特殊なケースでは、String 文字列の結合が StringBuilder オブジェクトの結合に解析されます。この場合、String の速度は StringBuffer よりも高速になります。文字列バッファ。例:
String name = ”I ” + ”am ” + ”chenssy ” ;
StringBuffer name = new StringBuffer(”I ”).append(” am ”).append( ” chenssy ”);
これら 2 つのメソッドでは、最初のメソッドが 2 番目のメソッドよりもはるかに高速であり、StringBuffer の利点がここでは失われていることがわかります。本当の理由は、JVM が何らかの最適化を行っているためです。実際、JVM の目では String name = "I am chenssy" になります。 、JVM の場合、本当に時間はかかりません。しかし、これに String オブジェクトを追加すると、JVM は元の仕様に従って String オブジェクトを構築します。
これら 3 つが使用されるシナリオは次のように要約されます (参考:「品質コードの作成: Java プログラムを改善するための 151 の提案」):
1. 文字列はあまり使用されません。 String クラスは、定数の宣言、少数の変数操作など、変化するシナリオで使用できます。
文字列バッファ 2.バッファ: 文字列操作 (スプライシング、置換、削除など) を頻繁に実行し、マルチスレッド環境で実行する場合は、XML 解析、HTTP パラメータ解析、およびカプセル化を待ちます。
3. StringBuilder: 文字列操作 (スプライシング、置換、削除など) を頻繁に実行し、マルチスレッド環境で実行する場合は、SQL ステートメントのアセンブル、JSON カプセル化などの StringBuffer の使用を検討できます。 (これら 2 つは |StringBuffer も使用しているようです)。 それらの違いの詳細については、http://www.php.cn/ を参照してください。余計な余計な贅沢は一切加えません。 文字列の場合、多くの場合、+ 、 concat() 、および append() メソッドの 3 つのアセンブリ メソッドが追加されています。 。これら 3 つの違いは何ですか?まず次の例を見てください: 上記の実行結果から、append() が最も速く、concat() が 2 番目であることがわかります。 、+ が最も遅いです。理由は以下の内訳をご覧ください: (1) + 文字列を結合する方法 () StringBuilder が StringBuffer よりも高速であることはわかっていますが、なぜでしょうか。走るスピードは同じですか?主な理由は、コンパイラが append() メソッドを使用して toString() で String 文字列に追加し、変換するためです。つまり、 str += "b" は str = new StringBuilder(str) と同等です。 .append( "b").toString(); (2) 文字列を結合する concat() メソッド これは concat() のソースコードです。次のようになります。 a デジタル コピーの形式では、配列の処理が非常に高速であることがわかりますが、メソッドは次のようになります。 return new String(0, count + otherLen, buf); これにより、ルートとなる 10W の文字列オブジェクトも作成されます。遅さの原因。 (3) 文字列を結合するappend()メソッド
5. 文字列の結合メソッド
public class StringTest {
/**
* @desc 使用+、concat()、append()方法循环10W次
* @author chenssy
* @data 2013-11-16
* @param args
* @return void
*/
public static void main(String[] args) {
//+
long start_01 = System.currentTimeMillis();
String a = "a";
for(int i = 0 ; i < 100000 ; i++){
a += "b";
}
long end_01 = System.currentTimeMillis();
System.out.println(" + 所消耗的时间:" + (end_01 - start_01) + "毫米");
//concat()
long start_02 = System.currentTimeMillis();
String c = "c";
for(int i = 0 ; i < 100000 ; i++){
c = c.concat("d");
}
long end_02 = System.currentTimeMillis();
System.out.println("concat所消耗的时间:" + (end_02 - start_02) + "毫米");
//append
long start_03 = System.currentTimeMillis();
StringBuffer e = new StringBuffer("e");
for(int i = 0 ; i < 100000 ; i++){
e.append("d");
}
long end_03 = System.currentTimeMillis();
System.out.println("append所消耗的时间:" + (end_03 - start_03) + "毫米");
}
}
------------
Output:
+ 所消耗的时间:19080毫米
concat所消耗的时间:9089毫米
append所消耗的时间:10毫米public class StringTest {
/**
* @desc 使用+、concat()、append()方法循环10W次
* @author chenssy
* @data 2013-11-16
* @param args
* @return void */
public static void main(String[] args) { //+
long start_01 = System.currentTimeMillis();
String a = "a"; for(int i = 0 ; i < 100000 ; i++){
a += "b";
} long end_01 = System.currentTimeMillis();
System.out.println(" + 所消耗的时间:" + (end_01 - start_01) + "毫米");
//concat()
long start_02 = System.currentTimeMillis();
String c = "c"; for(int i = 0 ; i < 100000 ; i++){
c = c.concat("d");
} long end_02 = System.currentTimeMillis();
System.out.println("concat所消耗的时间:" + (end_02 - start_02) + "毫米");
//append
long start_03 = System.currentTimeMillis();
StringBuffer e = new StringBuffer("e"); for(int i = 0 ; i < 100000 ; i++){
e.append("d");
} long end_03 = System.currentTimeMillis();
System.out.println("append所消耗的时间:" + (end_03 - start_03) + "毫米");
}
}------------Output: + 所消耗的时间:19080毫米
concat所消耗的时间:9089毫米
append所消耗的时间:10毫米public String concat(String str) {
int otherLen = str.length();
if (otherLen == 0) {
return this;
}
char buf[] = new char[count + otherLen];
getChars(0, count, buf, 0);
str.getChars(0, otherLen, buf, count);
return new String(0, count + otherLen, buf);
}
public synchronized StringBuffer append(String str) { super.append(str); return this;
}public AbstractStringBuilder append(String str) {
if (str == null) str = "null";
int len = str.length();
if (len == 0) return this;
int newCount = count + len;
if (newCount > value.length)
expandCapacity(newCount);
str.getChars(0, len, value, count);
count = newCount;
return this;
}
concat() メソッドと同様に、文字配列を処理し、それを拡張してからコピーします。ただし、最終的には返され、新しい文字列を返す代わりに、それ自体を返すことに注意してください。つまり、この 100,000 回のループ中に新しい文字列オブジェクトは生成されません。
上記の分析を通じて、適切な場所で適切な文字列結合メソッドを選択する必要がありますが、必ずしも append() メソッドと concat() メソッドを選択する必要はありません。 append() メソッドと concat() メソッドの使用がシステムの効率に本当に役立つ場合にのみ考慮します。同時に、 concat() メソッドを使用したことはありません。
上記は Java 改善章 (13)-----String の内容です。その他の関連コンテンツについては、PHP 中国語 Web サイト (www.php.cn) に注目してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1662
1662
 14
1418
52
1311
25
1261
29
1234
24
14
1418
52
1311
25
1261
29
1234
24

 Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8は、Stream APIを導入し、データ収集を処理する強力で表現力のある方法を提供します。ただし、ストリームを使用する際の一般的な質問は次のとおりです。 従来のループにより、早期の中断やリターンが可能になりますが、StreamのForeachメソッドはこの方法を直接サポートしていません。この記事では、理由を説明し、ストリーム処理システムに早期終了を実装するための代替方法を調査します。 さらに読み取り:JavaストリームAPIの改善 ストリームを理解してください Foreachメソッドは、ストリーム内の各要素で1つの操作を実行する端末操作です。その設計意図はです
 PHP:Web開発の重要な言語
Apr 13, 2025 am 12:08 AM
PHP:Web開発の重要な言語
Apr 13, 2025 am 12:08 AM
PHPは、サーバー側で広く使用されているスクリプト言語で、特にWeb開発に適しています。 1.PHPは、HTMLを埋め込み、HTTP要求と応答を処理し、さまざまなデータベースをサポートできます。 2.PHPは、ダイナミックWebコンテンツ、プロセスフォームデータ、アクセスデータベースなどを生成するために使用され、強力なコミュニティサポートとオープンソースリソースを備えています。 3。PHPは解釈された言語であり、実行プロセスには語彙分析、文法分析、編集、実行が含まれます。 4.PHPは、ユーザー登録システムなどの高度なアプリケーションについてMySQLと組み合わせることができます。 5。PHPをデバッグするときは、error_reporting()やvar_dump()などの関数を使用できます。 6. PHPコードを最適化して、キャッシュメカニズムを使用し、データベースクエリを最適化し、組み込み関数を使用します。 7
 PHP対Python:違いを理解します
Apr 11, 2025 am 12:15 AM
PHP対Python:違いを理解します
Apr 11, 2025 am 12:15 AM
PHP and Python each have their own advantages, and the choice should be based on project requirements. 1.PHPは、シンプルな構文と高い実行効率を備えたWeb開発に適しています。 2。Pythonは、簡潔な構文とリッチライブラリを備えたデータサイエンスと機械学習に適しています。
 PHP対その他の言語:比較
Apr 13, 2025 am 12:19 AM
PHP対その他の言語:比較
Apr 13, 2025 am 12:19 AM
PHPは、特に迅速な開発や動的なコンテンツの処理に適していますが、データサイエンスとエンタープライズレベルのアプリケーションには良くありません。 Pythonと比較して、PHPはWeb開発においてより多くの利点がありますが、データサイエンスの分野ではPythonほど良くありません。 Javaと比較して、PHPはエンタープライズレベルのアプリケーションでより悪化しますが、Web開発により柔軟性があります。 JavaScriptと比較して、PHPはバックエンド開発により簡潔ですが、フロントエンド開発のJavaScriptほど良くありません。
 PHP対Python:コア機能と機能
Apr 13, 2025 am 12:16 AM
PHP対Python:コア機能と機能
Apr 13, 2025 am 12:16 AM
PHPとPythonにはそれぞれ独自の利点があり、さまざまなシナリオに適しています。 1.PHPはWeb開発に適しており、組み込みのWebサーバーとRich Functionライブラリを提供します。 2。Pythonは、簡潔な構文と強力な標準ライブラリを備えたデータサイエンスと機械学習に適しています。選択するときは、プロジェクトの要件に基づいて決定する必要があります。
 カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルは3次元の幾何学的図形で、両端にシリンダーと半球で構成されています。カプセルの体積は、シリンダーの体積と両端に半球の体積を追加することで計算できます。このチュートリアルでは、さまざまな方法を使用して、Javaの特定のカプセルの体積を計算する方法について説明します。 カプセルボリュームフォーミュラ カプセルボリュームの式は次のとおりです。 カプセル体積=円筒形の体積2つの半球体積 で、 R:半球の半径。 H:シリンダーの高さ(半球を除く)。 例1 入力 RADIUS = 5ユニット 高さ= 10単位 出力 ボリューム= 1570.8立方ユニット 説明する 式を使用してボリュームを計算します。 ボリューム=π×R2×H(4
 PHPの影響:Web開発など
Apr 18, 2025 am 12:10 AM
PHPの影響:Web開発など
Apr 18, 2025 am 12:10 AM
phphassiblasifly-impactedwebdevevermentandsbeyondit.1)itpowersmajorplatformslikewordpratsandexcelsindatabase interactions.2)php'sadaptableability allowsitale forlargeapplicationsusingframeworkslikelavel.3)
 PHP:多くのウェブサイトの基礎
Apr 13, 2025 am 12:07 AM
PHP:多くのウェブサイトの基礎
Apr 13, 2025 am 12:07 AM
PHPが多くのWebサイトよりも優先テクノロジースタックである理由には、その使いやすさ、強力なコミュニティサポート、広範な使用が含まれます。 1)初心者に適した学習と使用が簡単です。 2)巨大な開発者コミュニティと豊富なリソースを持っています。 3)WordPress、Drupal、その他のプラットフォームで広く使用されています。 4)Webサーバーとしっかりと統合して、開発の展開を簡素化します。
