

Java 改善章 (20)-----大家族を集める

Java プログラムを作成するとき、8 つの基本データ型と String オブジェクトに加えて、最も一般的にコレクション クラスがプログラム内のあらゆる場所に使用されます。 Java には、一般的に使用される ArrayList、HashMap、HashSet だけでなく、あまり使用されない Stack と Queue、スレッド セーフな Vector と HashTable、スレッド セーフでない LinkedList、TreeMap など、コレクション ファミリのメンバーが多数あります。 、など!
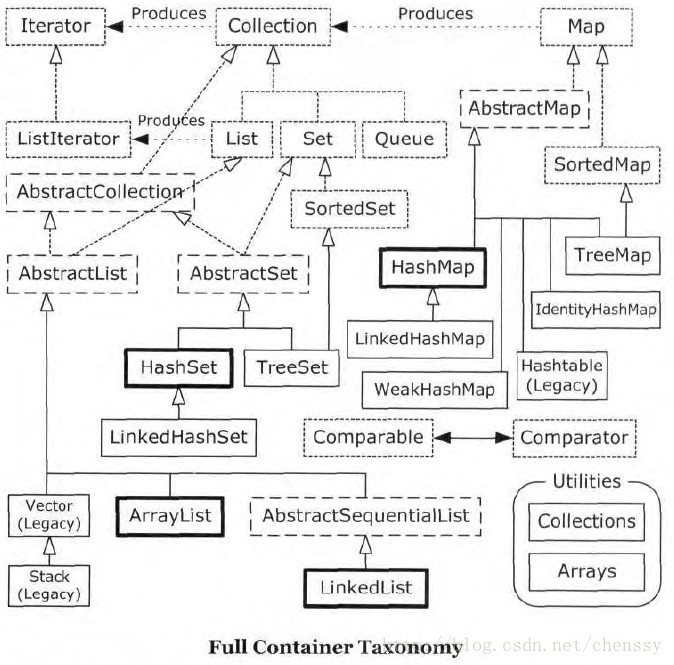
上の写真は、コレクションファミリー全体のメンバーとそれらの間の関係を示しています。以下に、上記の各インターフェイスと基本クラスについて簡単に説明します (主に各コレクションの特徴と違いを紹介します)。より詳細な紹介は、近いうちに 1 つずつ説明します。
1. コレクションインターフェイス
Collection インターフェイスは、最も基本的なコレクションインターフェイスです。Java SDK によって提供されるクラスはすべて、Collection から継承された「サブインターフェイス」です。リストとセットとして。コレクションはルールを表し、コレクションに含まれる要素は 1 つ以上のルールに従う必要があります。たとえば、重複を許可するものとできないもの、順番に挿入する必要があるもの、ハッシュを持つもの、並べ替えをサポートするものとサポートしないものなどです。 A Java で Collection インターフェイスを実装するすべてのクラスは、2 つの標準コンストラクター セットを提供する必要があります。1 つは空のコレクションを作成するために使用される非パラメーターであり、もう 1 つは新しいコレクションを作成するために使用される COLLECTION パラメーターを持つ参加関数です。渡されたコレクションと同じ要素を持ちます。
2. リストインターフェース
リストインターフェースはコレクションの直接インターフェースです。 List は順序付けされたコレクションを表します。つまり、要素の順序を維持するために特定の挿入順序を使用します。ユーザーはリスト内の各要素の挿入位置を正確に制御でき、整数インデックス (リスト内の位置) に基づいて要素にアクセスし、リスト内の要素を検索できます。 List インターフェイスを実装するコレクションには、主に ArrayList、LinkedList、Vector、Stack が含まれます。
2.1, ArrayList
ArrayList は動的配列であり、最も一般的に使用されるコレクションでもあります。ルールに準拠する任意の要素 (null も含む) を挿入できます。各 ArrayList には初期容量 (10) があり、これは配列のサイズを表します。コンテナ内の要素が増加し続けると、コンテナのサイズも増加します。コンテナに要素が追加されるたびに容量がチェックされ、オーバーフローしそうになると容量が拡張されます。したがって、挿入する要素の数がわかっている場合は、時間と効率を無駄にする過剰な拡張操作を避けるために、初期容量値を指定することが最善です
。size、isEmpty、get、set、iterator、listIterator の各操作はすべて固定時間で実行されます。追加操作は償却定数時間で実行されます。つまり、n 個の要素の追加には O(n) 時間がかかります (スケーリングを考慮しているため、償却定数時間のオーバーヘッドが発生する要素の追加ほど単純ではありません)。 ArrayList はランダムアクセスに優れています。同時に、ArrayList は非同期です。
2.2、LinkedList
LinkedList も List インターフェイスを実装していますが、ArrayList が動的配列であるのに対し、LinkedList は二重リンク リストです。したがって、ArrayList の基本的な操作メソッドに加えて、LinkedList の先頭または末尾に追加の get、remove、insert メソッドも提供されます。
実装方法が異なるため、LinkedList にランダムにアクセスすることはできず、そのすべての操作は二重リンク リストのニーズに従って実行する必要があります。リスト内のインデックス付け操作は、リストの先頭または末尾 (指定されたインデックスに近い末尾から) をスキャンします。この利点は、リスト内での挿入および削除操作を低コストで実行できることです。
ArrayList、LinkedList と同様に非同期です。複数のスレッドが同時にリストにアクセスする場合、スレッド自体がアクセス同期を実装する必要があります。解決策の 1 つは、リストの作成時に同期されたリストを構築することです:
List list = Collections.synchronizedList(new LinkedList(...)); ただし、Vector は同期されます。したがって、Vector はスレッドセーフな動的配列です。動作は ArrayList とほぼ同じです。
2.4, Stack
Stack は Vector から継承し、後入れ先出しスタックを実装します。 Stack には、Vector をスタックとして使用できるようにする 5 つの追加メソッドが用意されています。基本的なプッシュ メソッドとポップ メソッド、およびピーク メソッドはスタックの先頭にある要素を取得し、空のメソッドはスタックが空かどうかをテストし、検索メソッドはスタック内の要素の位置を検出します。スタックは、作成後の空のスタックです。
3. Setインターフェース
Setは、繰り返しの要素を含まないコレクションです。独自の内部順序を維持するため、ランダム アクセスは意味がありません。 List と同様に、null の存在も受け入れますが、1 つだけです。 Set インターフェイスの特殊性により、Set コレクションに渡されるすべての要素は異なる必要があります。同時に、 e1.equals(e2)==true が発生する場合は注意が必要です。コレクション内の要素を含めるには、特定の問題が発生します。 Set インターフェイスを実装するコレクションには、EnumSet、HashSet、および TreeSet が含まれます。
3.1、EnumSet
は列挙のための特別なセットです。すべての要素は列挙型です。
3.2, HashSet
HashSet は、HashCode で内部実装されているため、最速のクエリ セットと呼ぶことができます。内部要素の順序はハッシュ コードによって決定されるため、特にセットの反復順序は保証されず、順序が永続的であることも保証されません。
3.3, TreeSet
TreeMapをベースに、常にソートされた状態にあるセットを生成し、TreeMapで内部実装されています。使用されるコンストラクターに応じて、自然な順序を使用するか、Set の作成時に提供される に従って要素を並べ替えます。
4. Map インターフェイス
ComparatorMap は、List インターフェイスや Set インターフェイスとは異なり、キーから値へのマッピングを提供する、一連のキーと値のペアで構成されるコレクションです。同時に、Collection も継承しません。 Map では、キーと値の 1 対 1 の対応が保証されます。つまり、キーは値に対応するため、同じキー値を持つことはできませんが、もちろん値の値は同じにすることができます。マップの実装には、HashMap、TreeMap、HashTable、Properties、および EnumMap が含まれます。
4.1、HashMap
オブジェクトを検索するときに、その位置がハッシュ関数を通じて計算され、ハッシュ テーブル配列が定義されます。内部 (Entry[] テーブル) では、要素はハッシュ変換関数を通じて要素のハッシュ アドレスを配列に格納されたインデックスに変換します。競合がある場合は、同じハッシュ アドレスを持つすべての要素が Entry[] テーブルにまとめられます。ハッシュ リンク リストの形式。おそらく HashMap.Entry のソース コードを見ると、単一リンク リスト構造です。
4.3、ハッシュテーブル
キューは主に 2 つのカテゴリに分類されます。1 つはキューがいっぱいになった後に要素が挿入された場合、例外がスローされます。これには、主に ArrayBlockQueue、PriorityBlockingQueue、LinkedBlockingQueue が含まれます。もう 1 つのタイプのキューは両端キューです。これは、主に ArrayDeque、LinkedBlockingDeque、LinkedList などの先頭と末尾での要素の挿入と削除をサポートします。
6. 類似点と相違点
出典: http://www.php.cn/
6.1、Vector と ArrayList
1. ベクトルはスレッドは同期なのでスレッドセーフでもありますが、arraylist はスレッド非同期で安全ではありません。スレッドの安全性要素が考慮されていない場合は、通常、arraylist を使用する方が効率的です。
2. コレクション内の要素の数が現在のコレクション配列の長さよりも大きい場合、ベクトルの増加率は現在の配列の長さの 100%、配列リストの増加率は現在の配列の長さの 50% になります。現在の配列の長さ コレクション内のデータを使用する場合、比較的大量のデータの場合、ベクトルを使用するといくつかの利点があります。 3. 指定した場所のデータを検索する場合、vector と arraylist で使用される時間は同じで、どちらも 0(1) です。この時点では、vector または arraylist のどちらかを使用できます。指定された場所にデータを移動するのにかかる時間が 0(n-i) n が全長である場合、指定された場所にデータを移動するには 0(1) かかり、クエリ 指定された場所のデータを取得するのにかかる時間は 0(i) です。
ArrayList と Vector は配列を使用してデータを格納するため、実際に格納されるデータよりも多くの要素を追加および挿入できますが、データの挿入にはメモリが必要です。 Vector は同期メソッド (スレッド セーフ) を使用するため、インデックス作成に双方向のリンク リストを使用する ArrayList よりもパフォーマンスが悪くなります。シリアル番号によるデータは前方または後方への走査が必要ですが、データの挿入この時点では、この項目の前後の項目を記録するだけでよいので、複数回挿入した方が速いです。
6.2、Aarraylist と Linkedlist
1.ArrayList は動的配列に基づくデータ構造であり、LinkedList はリンク リストに基づくデータ構造です。
2. LinkedList はポインタを移動する必要があるため、取得および設定のためのランダム アクセスでは、LinkedList よりも ArrayList の方が優れていると感じます。
3. 新規および削除操作の追加および削除では、ArrayList はデータを移動する必要があるため、LinedList が有利です。 これは実際の状況によって異なります。単一のデータを挿入または削除するだけの場合は、ArrayList の方が LinkedList よりも高速です。ただし、データをバッチでランダムに挿入および削除する場合、データの一部が ArrayList に挿入されるたびに、挿入ポイントとその後のすべてのデータを移動する必要があるため、LinkedList の速度は ArrayList よりもはるかに優れています。
6.3. HashMap と TreeMap
1. TreeMap 内のすべての要素は、結果を取得する必要がある場合にハッシュコードを使用します。順序に応じて、TreeMap を使用する必要があります (HashMap 内の要素の順序は固定されていません)。 HashMap 内の要素の順序は固定されていません)。
2. HashMap はハッシュコードを使用してコンテンツを迅速に検索しますが、TreeMap 内のすべての要素は特定の固定順序を維持します。順序付けされた結果を取得する必要がある場合は、TreeMap を使用する必要があります (HashMap では要素の順序は変わりません)。修理済み)。 「コレクション フレームワーク」は、HashMap と TreeMap という 2 つの従来の Map 実装を提供します (TreeMap は SortedMap インターフェイスを実装します)
3. Map 内で要素を挿入、削除、配置するには、HashMap が最適な選択です。 HashMap を使用するには、ツリーが明確に定義されている hashCode() およびquals() の実装が必要です。6.4、hashtable と hashmap
1. 歴史的な理由: Hashtable は古い Dictionary クラスに基づいており、HashMap は Java 1.2 で導入された Map インターフェイスの実装です。
2. 同期性: Hashtable はスレッド セーフです。つまり、同期されていますが、HashMap はスレッド セーフであり、同期されていません。3. 値: HashMap のみ、null 値を値として使用できます。テーブルエントリのキーまたは値
7. セットの選択
7.1. ランダムクエリの場合 反復走査操作では、配列より高速です。したがって、ArrayList は通常、ランダム アクセスに使用されます
が、LinkedList は要素の追加と削除を非常に適切にサポートします。 3. Vector の場合、通常は
の使用を避けます。 結局のところ、List の頻繁な挿入と削除によりパフォーマンスが低下する場合は、ArrayList のみを使用することを検討してください。 7.2. Set の選択
1. HashSet は HashCode を使用して実装されるため、特に追加および検索操作において、ある程度のパフォーマンスが常に優れています。
3. TreeSet は HashSet ほど優れたパフォーマンスはありませんが、要素の順序を維持できるため、それでも用途はあります。
7.3. マップの選択
1. HashMap は HashSet と同様に高速クエリをサポートします。 HashTable は遅くはありませんが、HashMap よりもわずかに遅いため、HashMap はクエリ内の HashTable を置き換えることができます。
2. TreeMap は内部要素の順序を維持する必要があるため、通常は HashMap や HashTable よりも遅くなります。
上記の内容は、PHP 中国語 Web サイト (www.php.cn) に注目してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7569
7569
 15
1386
52
87
11
28
107
15
1386
52
87
11
28
107


 ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
Java の Weka へのガイド。ここでは、weka java の概要、使い方、プラットフォームの種類、利点について例を交えて説明します。

 Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
この記事では、Java Spring の面接で最もよく聞かれる質問とその詳細な回答をまとめました。面接を突破できるように。
 Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8は、Stream APIを導入し、データ収集を処理する強力で表現力のある方法を提供します。ただし、ストリームを使用する際の一般的な質問は次のとおりです。 従来のループにより、早期の中断やリターンが可能になりますが、StreamのForeachメソッドはこの方法を直接サポートしていません。この記事では、理由を説明し、ストリーム処理システムに早期終了を実装するための代替方法を調査します。 さらに読み取り:JavaストリームAPIの改善 ストリームを理解してください Foreachメソッドは、ストリーム内の各要素で1つの操作を実行する端末操作です。その設計意図はです
 Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプに関するガイド。ここでは、Java でタイムスタンプを日付に変換する方法とその概要について、例とともに説明します。
 カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルは3次元の幾何学的図形で、両端にシリンダーと半球で構成されています。カプセルの体積は、シリンダーの体積と両端に半球の体積を追加することで計算できます。このチュートリアルでは、さまざまな方法を使用して、Javaの特定のカプセルの体積を計算する方法について説明します。 カプセルボリュームフォーミュラ カプセルボリュームの式は次のとおりです。 カプセル体積=円筒形の体積2つの半球体積 で、 R:半球の半径。 H:シリンダーの高さ(半球を除く)。 例1 入力 RADIUS = 5ユニット 高さ= 10単位 出力 ボリューム= 1570.8立方ユニット 説明する 式を使用してボリュームを計算します。 ボリューム=π×R2×H(4
 Spring Tool Suiteで最初のSpring Bootアプリケーションを実行するにはどうすればよいですか?
Feb 07, 2025 pm 12:11 PM
Spring Tool Suiteで最初のSpring Bootアプリケーションを実行するにはどうすればよいですか?
Feb 07, 2025 pm 12:11 PM
Spring Bootは、Java開発に革命をもたらす堅牢でスケーラブルな、生産対応のJavaアプリケーションの作成を簡素化します。 スプリングエコシステムに固有の「構成に関する慣習」アプローチは、手動のセットアップを最小化します。
