

Java 改良章 (23)-----HashMap

& gt; & gt; & gt; には、多数のコレクションが存在します。キーと値の形式。 HashMap では、キーと値は常に全体として処理され、システムはハッシュ アルゴリズムに従ってキーと値の保存場所を計算し、キーを通じて値を常に迅速に保存および取得できます。 HashMapのアクセスを解析してみましょう。
1. 定義
HashMap は Map インターフェースを実装し、AbstractMap を継承します。 Map インターフェイスはキーを値にマッピングするためのルールを定義しますが、AbstractMap クラスは、このインターフェイスの実装に必要な作業を最小限に抑えるために Map インターフェイスのバックボーン実装を提供します。実際、AbstractMap クラスはすでに Map を実装しており、ここでマークされています。 LZ はもっと明確にすべきだと考えています。
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializableログイン後にコピー
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable2. コンストラクター
HashMap は 3 つのコンストラクターを提供します:
H ashMap(): デフォルトのイニシャルを使用してマップを構築します容量 (16) とデフォルトのロード空の HashMap係数 (0.75) を使用します。
HashMap(intInitialCapacity): 指定された初期容量とデフォルトの負荷係数 (0.75) を使用して空の HashMap を構築します。
HashMap(intInitialCapacity, floatloadFactor): 指定された初期容量と負荷係数を使用して空の HashMap を構築します。
ここでは、初期容量と負荷係数という 2 つのパラメーターについて説明します。これら 2 つのパラメーターは、HashMap のパフォーマンスに影響を与える重要なパラメーターです。容量はハッシュ テーブル内のバケットの数を表し、初期容量はハッシュ テーブルが作成されるときの容量、負荷係数はハッシュ テーブルがどの程度満たされるかを表します。容量が自動的に増加する前に、ハッシュ テーブルのスペース使用量を測定するスケール。負荷係数が大きいほど、ハッシュ テーブルの充填レベルは高くなります。また、その逆も同様です。リンク リスト方式を使用したハッシュ テーブルの場合、要素の検索にかかる平均時間は O(1+a) であるため、負荷係数が大きいほど、スペースはより完全に利用されます。検索効率が低下し、負荷係数が大きすぎると、スペースが最大限に活用されてしまい、ハッシュ テーブル内のデータがまばらになり、スペースが大幅に浪費されます。システムのデフォルトの負荷係数は 0.75 であり、通常はこれを変更する必要はありません。
HashMap は、高速アクセスをサポートするデータ構造です。そのパフォーマンスを理解するには、そのデータ構造を理解する必要があります。 Java で最も一般的に使用される 2 つの構造は、配列とシミュレートされたポインター (参照) であることがわかっています。ほとんどすべてのデータ構造でこれを使用できます。この 2 つは組み合わせて実装されており、HashMap にも同じことが当てはまります。実際、HashMap は「リンク リスト ハッシュ」です。以下はそのデータ構造です:
上の図から、HashMap の基礎となる実装は依然として配列であることがわかりますが、それぞれ配列の項目はチェーンです。パラメータinitialCapacityは配列の長さを表します。以下は HashMap コンストラクターのソース コードです:
public HashMap(int initialCapacity, float loadFactor) {
//初始容量不能<0
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: "
+ initialCapacity);
//初始容量不能 > 最大容量值,HashMap的最大容量值为2^30
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//负载因子不能 < 0
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: "
+ loadFactor);
// 计算出大于 initialCapacity 的最小的 2 的 n 次方值。
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
//设置HashMap的容量极限,当HashMap的容量达到该极限时就会进行扩容操作
threshold = (int) (capacity * loadFactor);
//初始化table数组
table = new Entry[capacity];
init();
}ソース コードからわかるように、HashMap が作成されるたびに、テーブル配列が初期化されます。 。テーブル配列の要素はエントリ ノードです。
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
final int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
.......
}
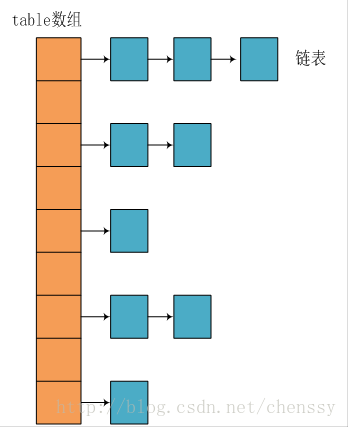
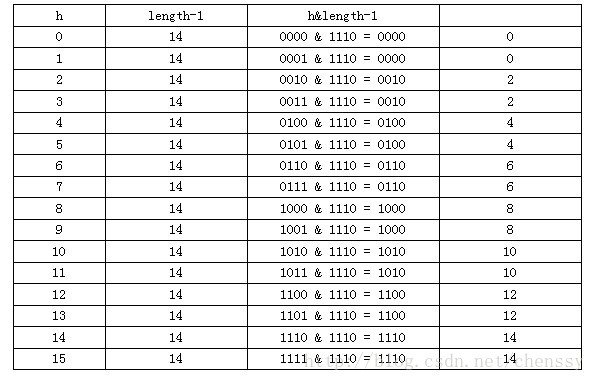
Entry は、キー、値、次のノード、次のハッシュ値を含む HashMap の内部クラスです。これは、Entry がテーブル配列を構成する項目であるため、非常に重要です。リンクされたリストです。 上面简单分析了HashMap的数据结构,下面将探讨HashMap是如何实现快速存取的。 首先我们先看源码 通过源码我们可以清晰看到HashMap保存数据的过程为:首先判断key是否为null,若为null,则直接调用putForNullKey方法。若不为空则先计算key的hash值,然后根据hash值搜索在table数组中的索引位置,如果table数组在该位置处有元素,则通过比较是否存在相同的key,若存在则覆盖原来key的value,否则将该元素保存在链头(最先保存的元素放在链尾)。若table在该处没有元素,则直接保存。这个过程看似比较简单,其实深有内幕。有如下几点: 1、 先看迭代处。此处迭代原因就是为了防止存在相同的key值,若发现两个hash值(key)相同时,HashMap的处理方式是用新value替换旧value,这里并没有处理key,这就解释了HashMap中没有两个相同的key。 2、 在看(1)、(2)处。这里是HashMap的精华所在。首先是hash方法,该方法为一个纯粹的数学计算,就是计算h的hash值。 我们知道对于HashMap的table而言,数据分布需要均匀(最好每项都只有一个元素,这样就可以直接找到),不能太紧也不能太松,太紧会导致查询速度慢,太松则浪费空间。计算hash值后,怎么才能保证table元素分布均与呢?我们会想到取模,但是由于取模的消耗较大,HashMap是这样处理的:调用indexFor方法。 HashMap的底层数组长度总是2的n次方,在构造函数中存在:capacity <<= 1;这样做总是能够保证HashMap的底层数组长度为2的n次方。当length为2的n次方时,h&(length - 1)就相当于对length取模,而且速度比直接取模快得多,这是HashMap在速度上的一个优化。至于为什么是2的n次方下面解释。 我们回到indexFor方法,该方法仅有一条语句:h&(length - 1),这句话除了上面的取模运算外还有一个非常重要的责任:均匀分布table数据和充分利用空间。 这里我们假设length为16(2^n)和15,h为5、6、7。 当n=15时,6和7的结果一样,这样表示他们在table存储的位置是相同的,也就是产生了碰撞,6、7就会在一个位置形成链表,这样就会导致查询速度降低。诚然这里只分析三个数字不是很多,那么我们就看0-15。 从上面的图表中我们看到总共发生了8此碰撞,同时发现浪费的空间非常大,有1、3、5、7、9、11、13、15处没有记录,也就是没有存放数据。这是因为他们在与14进行&运算时,得到的结果最后一位永远都是0,即0001、0011、0101、0111、1001、1011、1101、1111位置处是不可能存储数据的,空间减少,进一步增加碰撞几率,这样就会导致查询速度慢。而当length = 16时,length – 1 = 15 即1111,那么进行低位&运算时,值总是与原来hash值相同,而进行高位运算时,其值等于其低位值。所以说当length = 2^n时,不同的hash值发生碰撞的概率比较小,这样就会使得数据在table数组中分布较均匀,查询速度也较快。 这里我们再来复习put的流程:当我们想一个HashMap中添加一对key-value时,系统首先会计算key的hash值,然后根据hash值确认在table中存储的位置。若该位置没有元素,则直接插入。否则迭代该处元素链表并依此比较其key的hash值。如果两个hash值相等且key值相等(e.hash == hash && ((k = e.key) == key || key.equals(k))),则用新的Entry的value覆盖原来节点的value。如果两个hash值相等但key值不等 ,则将该节点插入该链表的链头。具体的实现过程见addEntry方法,如下: 这个方法中有两点需要注意: 一是链的产生。这是一个非常优雅的设计。系统总是将新的Entry对象添加到bucketIndex处。如果bucketIndex处已经有了对象,那么新添加的Entry对象将指向原有的Entry对象,形成一条Entry链,但是若bucketIndex处没有Entry对象,也就是e==null,那么新添加的Entry对象指向null,也就不会产生Entry链了。 二、扩容问题。 随着HashMap中元素的数量越来越多,发生碰撞的概率就越来越大,所产生的链表长度就会越来越长,这样势必会影响HashMap的速度,为了保证HashMap的效率,系统必须要在某个临界点进行扩容处理。该临界点在当HashMap中元素的数量等于table数组长度*加载因子。但是扩容是一个非常耗时的过程,因为它需要重新计算这些数据在新table数组中的位置并进行复制处理。所以如果我们已经预知HashMap中元素的个数,那么预设元素的个数能够有效的提高HashMap的性能。 相对于HashMap的存而言,取就显得比较简单了。通过key的hash值找到在table数组中的索引处的Entry,然后返回该key对应的value即可。 在这里能够根据key快速的取到value除了和HashMap的数据结构密不可分外,还和Entry有莫大的关系,在前面就提到过,HashMap在存储过程中并没有将key,value分开来存储,而是当做一个整体key-value来处理的,这个整体就是Entry对象。同时value也只相当于key的附属而已。在存储的过程中,系统根据key的hashcode来决定Entry在table数组中的存储位置,在取的过程中同样根据key的hashcode取出相对应的Entry对象。
以上就是java提高篇(二三)-----HashMap的内容,更多相关内容请关注PHP中文网(www.php.cn)! 四、存储实现:put(key,vlaue)
public V put(K key, V value) {
//当key为null,调用putForNullKey方法,保存null与table第一个位置中,这是HashMap允许为null的原因
if (key == null)
return putForNullKey(value);
//计算key的hash值
int hash = hash(key.hashCode()); ------(1)
//计算key hash 值在 table 数组中的位置
int i = indexFor(hash, table.length); ------(2)
//从i出开始迭代 e,找到 key 保存的位置
for (Entry<K, V> e = table[i]; e != null; e = e.next) {
Object k;
//判断该条链上是否有hash值相同的(key相同)
//若存在相同,则直接覆盖value,返回旧value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value; //旧值 = 新值
e.value = value;
e.recordAccess(this);
return oldValue; //返回旧值
}
}
//修改次数增加1
modCount++;
//将key、value添加至i位置处
addEntry(hash, key, value, i);
return null;
}static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}static int indexFor(int h, int length) {
return h & (length-1);
}
void addEntry(int hash, K key, V value, int bucketIndex) {
//获取bucketIndex处的Entry
Entry<K, V> e = table[bucketIndex];
//将新创建的 Entry 放入 bucketIndex 索引处,并让新的 Entry 指向原来的 Entry
table[bucketIndex] = new Entry<K, V>(hash, key, value, e);
//若HashMap中元素的个数超过极限了,则容量扩大两倍
if (size++ >= threshold)
resize(2 * table.length);
} 五、读取实现:get(key)
public V get(Object key) {
// 若为null,调用getForNullKey方法返回相对应的value
if (key == null)
return getForNullKey();
// 根据该 key 的 hashCode 值计算它的 hash 码
int hash = hash(key.hashCode());
// 取出 table 数组中指定索引处的值
for (Entry<K, V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) {
Object k;
//若搜索的key与查找的key相同,则返回相对应的value
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7652
7652
 15
1393
52
91
11
37
110
15
1393
52
91
11
37
110


 ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
Java の Weka へのガイド。ここでは、weka java の概要、使い方、プラットフォームの種類、利点について例を交えて説明します。

 Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
この記事では、Java Spring の面接で最もよく聞かれる質問とその詳細な回答をまとめました。面接を突破できるように。
 Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8は、Stream APIを導入し、データ収集を処理する強力で表現力のある方法を提供します。ただし、ストリームを使用する際の一般的な質問は次のとおりです。 従来のループにより、早期の中断やリターンが可能になりますが、StreamのForeachメソッドはこの方法を直接サポートしていません。この記事では、理由を説明し、ストリーム処理システムに早期終了を実装するための代替方法を調査します。 さらに読み取り:JavaストリームAPIの改善 ストリームを理解してください Foreachメソッドは、ストリーム内の各要素で1つの操作を実行する端末操作です。その設計意図はです
 Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプに関するガイド。ここでは、Java でタイムスタンプを日付に変換する方法とその概要について、例とともに説明します。
 カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルは3次元の幾何学的図形で、両端にシリンダーと半球で構成されています。カプセルの体積は、シリンダーの体積と両端に半球の体積を追加することで計算できます。このチュートリアルでは、さまざまな方法を使用して、Javaの特定のカプセルの体積を計算する方法について説明します。 カプセルボリュームフォーミュラ カプセルボリュームの式は次のとおりです。 カプセル体積=円筒形の体積2つの半球体積 で、 R:半球の半径。 H:シリンダーの高さ(半球を除く)。 例1 入力 RADIUS = 5ユニット 高さ= 10単位 出力 ボリューム= 1570.8立方ユニット 説明する 式を使用してボリュームを計算します。 ボリューム=π×R2×H(4
 未来を創る: まったくの初心者のための Java プログラミング
Oct 13, 2024 pm 01:32 PM
未来を創る: まったくの初心者のための Java プログラミング
Oct 13, 2024 pm 01:32 PM
Java は、初心者と経験豊富な開発者の両方が学習できる人気のあるプログラミング言語です。このチュートリアルは基本的な概念から始まり、高度なトピックに進みます。 Java Development Kit をインストールしたら、簡単な「Hello, World!」プログラムを作成してプログラミングを練習できます。コードを理解したら、コマンド プロンプトを使用してプログラムをコンパイルして実行すると、コンソールに「Hello, World!」と出力されます。 Java の学習はプログラミングの旅の始まりであり、習熟が深まるにつれて、より複雑なアプリケーションを作成できるようになります。
