

Buffer は実際にはコンテナ オブジェクトであり、書き込まれるか読み取られるデータが含まれます。 Buffer オブジェクトを NIO に追加すると、新しいライブラリと元の I/O の間の重要な違いが反映されます。ストリーム指向の I/O では、データを Stream オブジェクトに直接書き込みまたは読み取ります。
NIO ライブラリでは、すべてのデータはバッファーで処理されます。データを読み取る場合、データはバッファに直接読み込まれます。データが書き込まれる場合、データはバッファに書き込まれます。 NIO 内のデータにアクセスするときは常に、データをバッファーに入れます。
バッファは本質的には配列です。通常はバイト配列ですが、他の種類の配列も使用できます。しかし、バッファは単なる配列ではありません。バッファはデータへの構造化されたアクセスを提供し、システムの読み取り/書き込みプロセスを追跡することもできます。
最も一般的に使用されるバッファー タイプは ByteBuffer です。 ByteBuffer は、その基礎となるバイト配列に対して get/set 操作 (つまり、バイトの取得と設定) を実行できます。
ByteBuffer は NIO の唯一のバッファー タイプではありません。実際、すべての基本的な Java 型にはバッファ型があります (対応するバッファ クラスを持たないのはブール型のみです):
ByteBuffer
CharBuffer
ShortBuffer
IntBuffer
LongBuffer
FloatBuffer
DoubleBuffer
すべての Buffer クラスは Buffer インターフェイスのインスタンスです。 ByteBuffer を除いて、各 Buffer クラスはまったく同じ操作を行いますが、扱うデータ型が異なります。ほとんどの標準 I/O 操作は ByteBuffer を使用するため、すべての共有バッファー操作といくつかの固有の操作が含まれます。 Buffer のクラス階層図を見てみましょう: 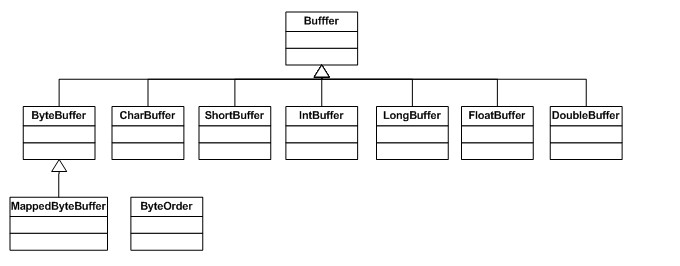
各 Buffer には次の属性があります:
capacity
この Buffer が保持できるデータの最大量。容量は通常、バッファの作成時に指定されます。
limit
バッファ上で実行される読み取りおよび書き込み操作は、この添字を超えることはできません。データをバッファに書き込む場合、リミットは通常、容量と同じになります。データを読み取る場合、リミットはバッファ内の有効なデータの長さを表します。
position
position 変数は、バッファーに書き込まれた、またはバッファーから読み取られたデータの量を追跡します。
より正確には、チャネルからバッファにデータを読み取るとき、次のデータが配列のどの要素に配置されるかを示します。たとえば、チャネルからバッファに 3 バイトを読み取る場合、バッファの位置は 3 に設定され、配列の 4 番目の要素を指します。逆に、書き込みチャネルのバッファからデータを取得すると、次のデータが配列のどの要素から取得されたのかがわかります。たとえば、バッファからチャネルに 5 バイトを書き込むと、バッファの位置は 5 に設定され、配列の 6 番目の要素を指します。
マーク
一時的な保管場所のインデックス。 mark() を呼び出すと、mark が現在の位置の値に設定され、後でreset() を呼び出すと、position プロパティが mark の値に設定されます。 mark の値は常に、position の値以下になります。position の値が mark よりも小さく設定されている場合、現在の mark 値は破棄されます。
これらのプロパティは常に次の条件を満たします:
0 <= mark <= position <= limit <= capacity
バッファの内部実装メカニズム:
入力チャネルから出力チャネルにデータをコピーする例をとって、各変数を詳細に分析し、それらがどのように連携するかを説明しましょう:
初期変数 :
Weまず、新しく作成されたバッファを観察します。例として ByteBuffer を取り上げます。バッファのサイズが 8 バイトであると仮定すると、ByteBuffer の初期状態は次のようになります。
この例では、制限が容量を超えてはいけないことを思い出してください。両方の値は 8 に設定されます。これを、配列の末尾 (スロット 8) の後に指定することで説明します。 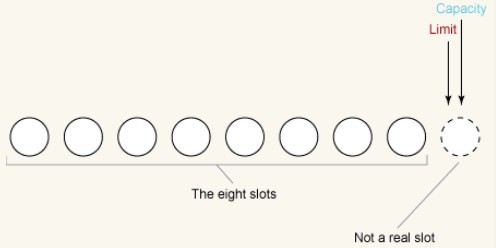
もう一度位置を0に設定しましょう。バッファにデータを読み込んだ場合、次に読み取られるデータはスロット 0 に入力されることを示します。バッファからデータを書き込む場合、バッファから読み取られる次のバイトはスロット 0 からです。位置の設定は以下の通りです。 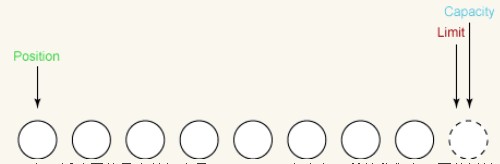
バッファの最大データ容量は変わらないので、以下の説明では無視して構いません。
最初の読み取り:
これで、新しく作成されたバッファーで読み取り/書き込み操作を開始できます。まず、入力チャネルからバッファにデータを読み取ります。最初の読み取りでは 3 バイトが取得されます。これらは、0 に設定された位置から始まる配列に配置されます。読み取り後、以下に示すように位置は 3 に増加しましたが、制限は変更されませんでした。 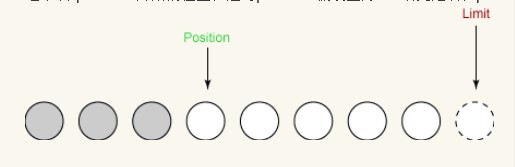
2 回目の読み取り:
2 回目の読み取りでは、さらに 2 バイトを入力チャネルからバッファーに読み取ります。これらの 2 バイトは、position で指定された場所に格納されるため、position は 2 増加しますが、limit は変更されません。 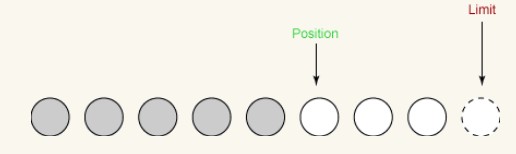
フリップ:
今度は、データを出力チャンネルに書き込みたいと思います。その前に、flip() メソッドを呼び出す必要があります。 ソース コードは次のとおりです。
public final Buffer flip()
{
limit = position;
position = 0;
mark = -1;
return this;
}
这个方法做两件非常重要的事:
i 它将limit设置为当前position。
ii 它将position设置为0。 前の図は反転前のバッファを示しています。反転後のバッファは次のとおりです: 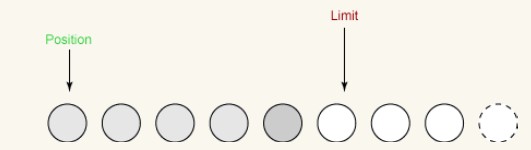
これで、バッファからチャネルにデータを書き込むことができます。位置は 0 に設定されます。これは、次に取得するバイトが最初のバイトであることを意味します。制限は元の位置に設定されています。これは、以前に読み取られたすべてのバイトが含まれ、それ以上のバイトは含まれないことを意味します。
最初の書き込み:
最初の書き込みでは、バッファから 4 バイトを取り出し、出力チャネルに書き込みます。これにより、以下のように、制限は変更されないまま、位置が 4 に増加します: 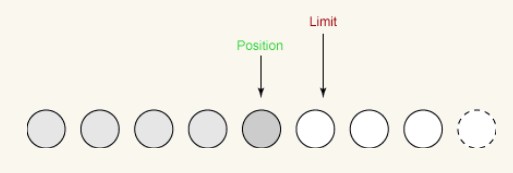
2 番目の書き込み:
書き込むバイトが 1 バイトだけ残っています。 flick() を呼び出すと、limit は 5 に設定され、position は limit を超えることはできません。 したがって、最後の書き込み操作はバッファからバイトを取得し、それを出力チャネルに書き込みます。これにより、次のように、制限は変更されずに、位置が 5 に増加します: 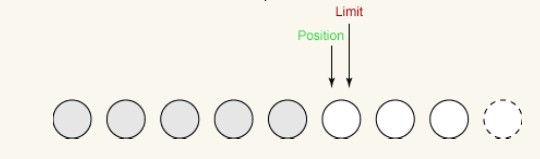
clear:
最後のステップは、バッファの clear() メソッドを呼び出すことです。このメソッドは、より多くのバイトを受信するためにバッファをリセットします。ソースコードは次のとおりです:
public final Buffer clear()
{
osition = 0;
limit = capacity;
mark = -1;
return this;
}clear は 2 つの非常に重要な機能を実行します:
i 制限を容量と同じに設定します。
ii 位置を0に設定します。
下の図は、clear()を呼び出した後のバッファのステータスを示しています。バッファは新しいデータを受信する準備ができています。 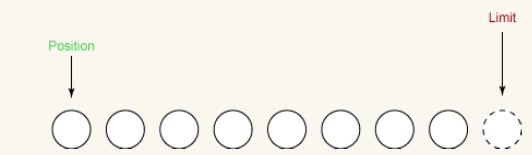
これまで、あるチャンネルから別のチャンネルにデータを転送するためにバッファーのみを使用してきましたが、多くの場合、プログラムはデータを直接処理する必要があります。たとえば、ユーザー データをディスクに保存する必要がある場合があります。この場合、このデータをバッファに直接入れてから、チャネルを使用してバッファをディスクに書き込む必要があります。 あるいは、ディスクからユーザー データを読み取ることもできます。この場合、チャネルからデータをバッファに読み取り、バッファにデータがあるかどうかを確認します。実際、各基本タイプのバッファには、バッファ内のデータに直接アクセスするためのメソッドが用意されています。ByteBuffer を例として、バッファ内のデータに直接アクセスするために提供される get() メソッドと put() メソッドの使用方法を分析してみましょう。バッファ。
a) get()
ByteBuffer クラスには 4 つの get() メソッドがあります:
byte get(); ByteBuffer get( byte dst[] ); ByteBuffer get( byte dst[], int offset, int length ); byte get( int index );
第一个方法获取单个字节。第二和第三个方法将一组字节读到一个数组中。第四个方法从缓冲区中的特定位置获取字节。那些返回ByteBuffer的方法只是返回调用它们的缓冲区的this值。 此外,我们认为前三个get()方法是相对的,而最后一个方法是绝对的。“相对”意味着get()操作服从limit和position值,更明确地说, 字节是从当前position读取的,而position在get之后会增加。另一方面,一个“绝对”方法会忽略limit和position值,也不会 影响它们。事实上,它完全绕过了缓冲区的统计方法。 上面列出的方法对应于ByteBuffer类。其他类有等价的get()方法,这些方法除了不是处理字节外,其它方面是是完全一样的,它们处理的是与该缓冲区类相适应的类型。
注:这里我们着重看一下第二和第三这两个方法
ByteBuffer get( byte dst[] ); ByteBuffer get( byte dst[], int offset, int length );
这两个get()主要用来进行批量的移动数据,可供从缓冲区到数组进行的数据复制使用。第一种形式只将一个数组 作为参数,将一个缓冲区释放到给定的数组。第二种形式使用 offset 和 length 参数来指 定目标数组的子区间。这些批量移动的合成效果与前文所讨论的循环是相同的,但是这些方法 可能高效得多,因为这种缓冲区实现能够利用本地代码或其他的优化来移动数据。
buffer.get(myArray)
等价于:
buffer.get(myArray,0,myArray.length);
注:如果您所要求的数量的数据不能被传送,那么不会有数据被传递,缓冲区的状态保持不 变,同时抛出 BufferUnderflowException 异常。因此当您传入一个数组并且没有指定长度,您就相当于要求整个数组被填充。如果缓冲区中的数据不够完全填满数组,您会得到一个 异常。这意味着如果您想将一个小型缓冲区传入一个大数组,您需要明确地指定缓冲区中剩 余的数据长度。上面的第一个例子不会如您第一眼所推出的结论那样,将缓冲区内剩余的数据 元素复制到数组的底部。例如下面的代码:
String str = "com.xiaoluo.nio.MultipartTransfer";
ByteBuffer buffer = ByteBuffer.allocate(50);
for(int i = 0; i < str.length(); i++)
{
buffer.put(str.getBytes()[i]);
}
buffer.flip();byte[] buffer2 = new byte[100];
buffer.get(buffer2);
buffer.get(buffer2, 0, length);
System.out.println(new String(buffer2));这里就会抛出java.nio.BufferUnderflowException异常,因为数组希望缓存区的数据能将其填满,如果填不满,就会抛出异常,所以代码应该改成下面这样:
//得到缓冲区未读数据的长度
int length = buffer.remaining();
byte[] buffer2 = new byte[100];
buffer.get(buffer2, 0, length);
b) put()ByteBuffer类中有五个put()方法:
ByteBuffer put( byte b );
ByteBuffer put( byte src[] );
ByteBuffer put( byte src[], int offset, int length );
ByteBuffer put( ByteBuffer src );
ByteBuffer put( int index, byte b );第一个方法 写入(put)单个字节。第二和第三个方法写入来自一个数组的一组字节。第四个方法将数据从一个给定的源ByteBuffer写入这个 ByteBuffer。第五个方法将字节写入缓冲区中特定的 位置 。那些返回ByteBuffer的方法只是返回调用它们的缓冲区的this值。 与get()方法一样,我们将把put()方法划分为“相对”或者“绝对”的。前四个方法是相对的,而第五个方法是绝对的。上面显示的方法对应于ByteBuffer类。其他类有等价的put()方法,这些方法除了不是处理字节之外,其它方面是完全一样的。它们处理的是与该缓冲区类相适应的类型。
c) 类型化的 get() 和 put() 方法
除了前些小节中描述的get()和put()方法, ByteBuffer还有用于读写不同类型的值的其他方法,如下所示:
getByte()
getChar()
getShort()
getInt()
getLong()
getFloat()
getDouble()
putByte()
putChar()
putShort()
putInt()
putLong()
putFloat()
putDouble()
事实上,这其中的每个方法都有两种类型:一种是相对的,另一种是绝对的。它们对于读取格式化的二进制数据(如图像文件的头部)很有用。
下面的内部循环概括了使用缓冲区将数据从输入通道拷贝到输出通道的过程。
while(true)
{
//clear方法重设缓冲区,可以读新内容到buffer里
buffer.clear();
int val = inChannel.read(buffer);
if(val == -1)
{
break;
}
//flip方法让缓冲区的数据输出到新的通道里面
buffer.flip();
outChannel.write(buffer);
}read()和write()调用得到了极大的简化,因为许多工作细节都由缓冲区完成了。clear()和flip()方法用于让缓冲区在读和写之间切换。
好了,缓冲区的内容就暂且写到这里,下一篇我们将继续NIO的学习–通道(Channel).
以上就是Java NIO 缓冲区学习笔记 的内容,更多相关内容请关注PHP中文网(www.php.cn)!
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



