

1. MySql 操作に接続します
接続: mysql -h ホストアドレス -u ユーザー名 -p ユーザーパスワード (注: u と root は可能です)スペースを追加する必要はありません。他の場合も同様です) 切断: exit (Enter) cmdを開き、mysql -h 127.0.0.1 -u root -pと入力し、パスワードを入力します。ローカルの MySql データベースに接続できます。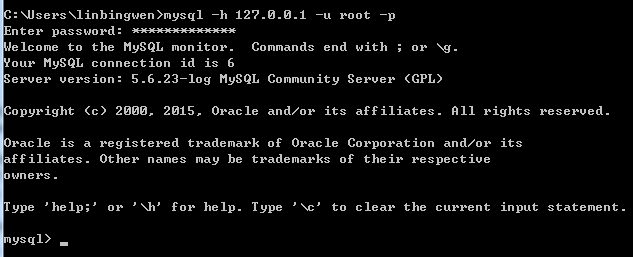
2. ユーザーの作成:
コマンド: CREATE USER 'username'@'host' IDENTIFIED BY 'password'; 説明: username - 作成するユーザー名、host - を指定します。ユーザーがログインできるホスト。ローカル ユーザーの場合は、localhost を使用できます。ユーザーが任意のリモート ホストからログインできるようにするには、ワイルドカード %.パスワード (ユーザーのログイン パスワード) を使用できます。パスワードは空でもかまいません。空の場合、ユーザーはパスワードなしでサーバーにログインできます ログインするときは、まず現在のパスワードを終了してから、次のCREATE USER 'lin'@'localhost' IDENTIFIED BY '123456'; CREATE USER 'pig'@'192.168.1.101_' IDENDIFIED BY '123456'; CREATE USER 'pig'@'%' IDENTIFIED BY '123456'; CREATE USER 'pig'@'%' IDENTIFIED BY ''; CREATE USER 'pig'@'%';
を入力します。
3. 権限: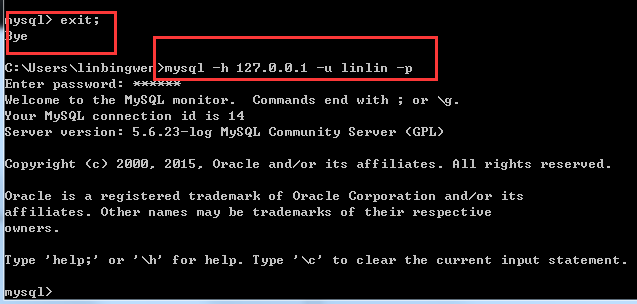
説明:
権限 - SELECT、INSERT、UPDATE などのユーザーの操作権限 (を参照)詳細なリストについては、この記事の最後を参照してください)。すべての権限を付与する場合は、「;databasename - データベース名」、「tablename - テーブル名」を使用します。すべてのデータベースとテーブルに対する対応する操作権限を付与します。 *.* などの * を使用できます。例:mysql -h 127.0.0.1 -u linlin -p 密码 mysql -h 127.0.0.1 -u pig -p 密码
GRANT SELECT, INSERT ON school.* TO 'lin' @'%'; GRANT ALL ON *.* TO 'pig'@'%';
4ユーザーのパスワードを設定および変更します
コマンド: SET PASSWORD FOR 'username'@'host' = PASSWORD('newpassword' ); 現在ログインしているユーザーの場合は、SET PASSWORD = PASSWORD("newpassword"); を使用します。例: SET PASSWORD FOR 'lin'@'%' = PASSWORD("123456");
5. ユーザー権限を取り消します
 コマンド: REVOKE ON データベース名.テーブル名 FROM 'ユーザー名'@' host';
コマンド: REVOKE ON データベース名.テーブル名 FROM 'ユーザー名'@' host';
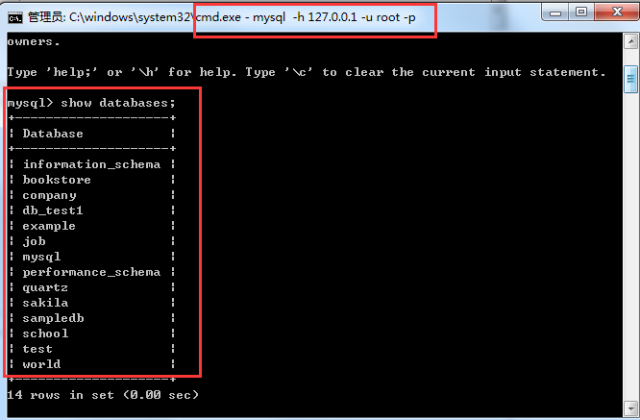
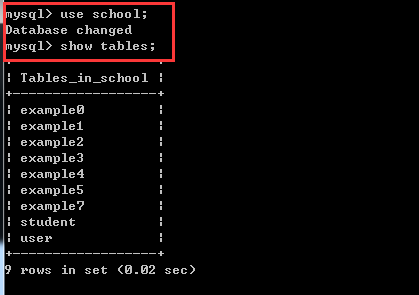
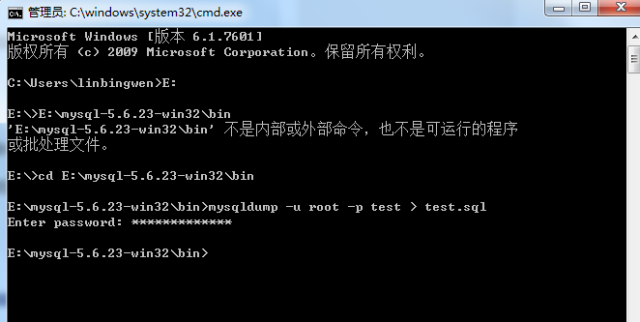
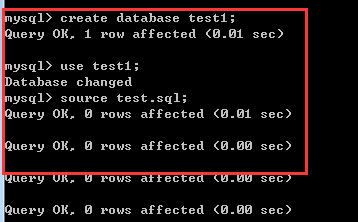
説明: 権限、データベース名、テーブル名 - 認可部分と同じです。 例子: REVOKE SELECT ON *.* FROM 'pig'@'%'; 注意: 假如你在给用户'pig'@'%'授权的时候是这样的(或类似的):GRANT SELECT ON test.user TO 'pig'@'%', 则在使用REVOKE SELECT ON *.* FROM 'pig'@'%';命令并不能撤销该用户对test数据库中user表的SELECT 操作.相反,如果授权使用的是GRANT SELECT ON *.* TO 'pig'@'%';则REVOKE SELECT ON test.user FROM 'pig'@'%';命令也不能撤销该用户对test数据库中user表的Select 权限. 具体信息可以用命令SHOW GRANTS FOR 'pig'@'%'; 查看. 6、删除用户 命令: DROP USER 'username'@'host'; 1、数据库显示、创建、删除 显示数据库:show databases; 创建库:create database 库名; 删除库:drop database 库名; 使用库(选中库):use 库名; 2、表显示、创建、删除 显示数据表:show tables; (要先用use 数据库名选定数据库) 显示表结构:describe 表名;或者desc 表名 创建表:create table 表名 (字段设定列表); 删除表:drop table 表名; 句法:DROP DATABASE [IF EXISTS] db_name 功能:DROP DATABASE删除数据库中的所有表和数据库。要小心地使用这个命令! DROP DATABASE返回从数据库目录被删除的文件的数目。通常,这3倍于表的数量,因为每张表对应于一个“.MYD”文件、一个“.MYI”文件和一个“.frm”文件。 在MySQL 3.22或以后版本中,你可以使用关键词IF EXISTS阻止一个错误的发生,如果数据库不存在。 假设现在有表books: 1.复制表结构 1.1 含有主键等信息的完整表结构 CREATE table 新表名 LIKE book; 1.2 只有表结构,没有主键等信息 テーブルを作成 新しいテーブル名 select * frombooks; または create table 新しいテーブル名 as(select * from book); or create table 新しいテーブル名 select * frombooks where1=2; 2. 古いテーブルから新しいテーブルにデータを注ぎます INSERT INTO new table SELECT * FROM old table; 注: 新しいテーブルはすでに存在している必要があります 3. DDL ステートメントを入力してテーブルを作成します show create table テーブル名; 4. テーブル データをクリア truncate table テーブル名; 5. データベースをバックアップします たとえば、ライブラリ データベースをバックアップします Mysql のディレクトリ E:mysql-5.6.23 -win32bin 「mysqldump -u ユーザー名 -p データベース名>バックアップ名」を使用してデータベースをファイルにエクスポートします C:Program FilesMySQLMySQL Server 5.5bin>mysqldump -u root -p test >test.sql パスワードを入力してください: *** それだけです E:mysql-5.6.23-win32bin directory 6. データベースを復元します テーブル名を切り詰める; 效率上truncate比delete快,但truncate删除后不记录mysql日志,不可以恢复数据。 delete的效果有点像将mysql表中所有记录一条一条删除到删完, 而truncate相当于保留mysql表的结构,重新创建了这个表,所有的状态都相当于新表。 2、删除表中的某些数据 delete from命令格式:delete from 表名 where 表达式 例如,删除表 MyClass中编号为1 的记录: 代码如下: 1、给列更名 >alter table 表名称 change 字段名称 字段名称 例如: alter table pet change weight wei; 2、给表更名 >alter table 表名称 rename 表名称 例如: alter table tbl_name rename new_tbl 3、修改某个表的字段类型及指定为空或非空 >alter table 表名称 change 字段名称字段名称 字段类型 [是否允许非空]; >alter table 表名称 modify 字段名称字段类型 [是否允许非空]; 4、修改某个表的字段名称及指定为空或非空 >alter table 表名称 change 字段原名称字段新名称 字段类型 [是否允许非空]; 例如: 修改表expert_info中的字段birth,允许其为空 代码如下: 1.增加一个字段(一列) alter table table_name add column column_name type default value; type指该字段的类型,value指该字段的默认值 例如: 代码如下: 2.更改一个字段名字(也可以改变类型和默认值) alter table table_name change sorce_col_name dest_col_name type defaultvalue; source_col_name指原来的字段名称,dest_col_name 指改后的字段名称 例如: 代码如下: 3.改变一个字段的默认值 alter table table_name alter column_name set default value; 例如: 代码如下: 4.改变一个字段的数据类型 alter table table_name change column column_name column_name type; 例如: 代码如下: 5.向一个表中增加一个列做为主键 alter table table_name add column column_name type auto_increment PRIMARYKEY; 例如: 代码如下: 6.数据库某表的备份,在命令行中输入: mysqldump -u root -p database_name table_name > bak_file_name 例如: 代码如下: 7.导出数据 select_statment into outfile”dest_file”; 例如: 代码如下: 8.导入数据 load data infile”file_name” into table table_name; 例如: 代码如下: 9.将两个表里的数据拼接后插入到另一个表里。下面的例子说明将t1表中的com2和t2表中的com1字段的值拼接后插入到tx表对应的字段里。 例如: 代码如下:二、数据库与表显示、创建、删除
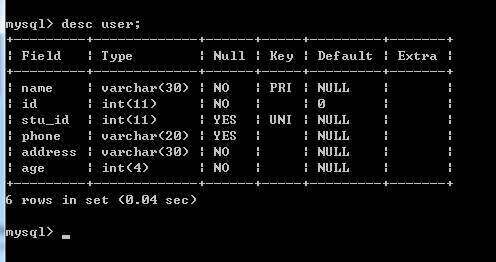
CR EATE TABLE
USER
(
name VARCHAR(30) NOT NULL,
id INT DEFAULT '0' NOT NULL,
stu_id INT,
phone VARCHAR(20),
address VARCHAR(30) NOT NULL,
age INT(4) NOT NULL,
PRIMARY KEY (name),
CONSTRAINT stu_id UNIQUE (stu_id)
)
ENGINE=InnoDB D EFAULT CHARSET=utf8;
三、表复制及备份还原

4. データベーステーブルのデータ操作
1. mysqlテーブルのデータを削除mysql> delete from MyClass where id=1;
五、修改表的列与表名
>alter table expert_info change birth birth varchar(20) null;
六、修改表中的数据
alter table mybook add column publish_house varchar(10) default ”;
alter table Board_Info change IsMobile IsTelphone int(3) unsigned default1;
alter table book alter flag set default '0′;
alter table userinfo change column username username varchar(20)
alter table book add column id int(10) auto_increment PRIMARY KEY;
mysqldump -u root -p f_info user_info > user_info.dat
select cooperatecode,createtime from publish limit 10 intooutfile”/home/mzc/temp/tempbad.txt”;
load data infile”/home/mzc/temp/tempbad.txt” into table pad;
insert into tx select t1.com1,concat(t1.com2,t2.com1) from t1,t2;
10.删除字段
alter table form1 drop column 列名;
mysql查询的五种子句
where(条件查询)、having(筛选)、group by(分组)、order by(排序)、limit(限制结果数)
1、查询数值型数据:
SELECT * FROM tb_name WHERE sum > 100;
查询谓词:>,=,<,<>,!=,!>,!<,=>,=<
2、查询字符串
tb_stuからsselect *ここでsname = 'xiaoliu'select * tb_stuからsname from sname like' liu% 'select * tb_stu from suname' sname from tb_stu from sunam %'3. 日付型データのクエリ
SELECT * FROM tb_stu WHERE date = '2011-04-08'
注: データベースごとに日付型データが異なります: :(1)MySQL: SELECT * from tb_name WHERE 誕生日 = '2011-04-08'(2)SQL Server:SELECT * from tb_name WHERE 誕生日 = '2011-04-08'(3)Access:SELECT * from tb_name WHERE 誕生日 = # 2011-04-08#4. 論理データのクエリ
SELECT * FROM tb_name WHERE type = 'T'
SELECT * FROM tb_name WHERE type = 'F'論理演算子: and or not5. 空でないデータをクエリします
SELECT * FROM tb_name WHERE address <>'' order by addtime desc
注: <> は、PHP 6 の !=に相当します。変数を使用します。数値をクエリします。 data
SELECT * FROM tb_name WHERE id = '$_POST[text]'
注: 変数を使用してデータをクエリする場合、SQL に渡される変数を引用符で囲む必要はありません。文字列と値は引用符で囲まれる必要がありません。 PHP では、型データを接続する場合、プログラムは自動的に数値データを文字列に変換し、接続する文字列と接続します7. 変数を使用して文字列データをクエリします
SELECT * FROM tb_name WHERE name LIKE '% $_POST[name]%'
完全一致メソッド "%%" は、どこにでも出現できることを意味します8. 最初の n レコードをクエリします
SELECT * FROM tb_name LIMIT 0,$N;
limitステートメント order by や他のステートメントなどの他のステートメントと組み合わせて使用すると、SQL ステートメントはさまざまな方法で使用され、プログラムが非常に柔軟になります9. クエリ後の n レコード
SELECT * FROM tb_stu ORDER BY id ASC LIMIT $n
10 , 指定された位置から始まる n 件のレコードをクエリ
SELECT * FROM tb_stu ORDER BY id ASC LIMIT $_POST[begin],$n
注: データの ID は次から始まります011. 統計結果のクエリ
の最初の n レコード
SELECT * ,(yw+sx+wy) AS total FROM tb_score ORDER BY (yw+sx+wy) DESC LIMIT 0,$num
12. 指定された期間のデータをクエリします
SELECT 対象のフィールドFROM テーブル名 WHERE フィールド名 BETWEEN 初期値 AND 終了値
SELECT * FROM tb_stu WHERE age BETWEEN 0 AND 18
13. 月ごとの統計データをクエリ
SELECT * FROM tb_stu WHERE month(date) = ' $_POST[ date]' ORDER BY date ;
注: SQL 言語には、年、月、日による簡単なクエリに使用できる次の関数が用意されています
year(data): データ式で西暦年を返します。分に対応する値
month(data): データ式の月と分に対応する値を返します
day(data): データ式の日付に対応する値を返します
14。指定された条件レコードより大きいです
SELECT * FROM tb_stu WHERE age>$_POST[age] ORDER BY age;
15。クエリ結果には重複レコードは表示されません
SELECT DISTINCT フィールド名 FROM テーブル名 WHERE クエリ条件
注: SQL ステートメント内の DISTINCT は、WHERE 句と組み合わせて使用する必要があります。そうしないと、出力情報は変更されず、フィールドを *
16 と組み合わせた条件クエリの述語で置き換えることはできません。 (1)NOT BERWEEN… AND... 開始値と終了値の間のデータをクエリする場合、行クエリは <開始値 AND > に変更できます
(2)IS NOT NULL 以外のクエリ-null 値
(3)IS NULL null 値のクエリ
(4)NOT IN この式は、使用されたキーワードがリストに含まれるかリストから除外されるかに基づいて式の検索を指定します。式は定数または列名にすることができ、列名は定数のセットにすることもできますが、多くの場合はサブクエリになります
17 データテーブル内の重複レコードとレコード数を表示します。 SELECT name,age,count(*),age FROM tb_stu WHERE age = ' 19' 日付でグループ化
18. データを降順/昇順でクエリしますSELECT フィールド名 FROM tb_stu WHERE 条件 ORDER BY フィールド DESC 降順
SELECT フィールド名 FROM tb_stu WHERE 条件 ORDER BY フィールド ASC 昇順
注: フィールドを並べ替えるときに並べ替え方法を指定しない場合、デフォルトはデータに対する複数条件クエリ
19 です。SELECT フィールド名 FROM tb_stu WHERE 条件 ORDER BY フィールド 1 ASC フィールド 2 DESC... 注: 複数の条件によってクエリ情報を並べ替える目的は、一般に、レコードの出力を制限することです。単一の条件であっても、出力効果にはいくつかの違いがあります。
20. 統計結果のソート
関数SUM([ALL]フィールド名)またはSUM([DISTINCT]フィールド名)は、関数がALLの場合、このフィールドのすべてのレコードになります。合計 (DISTINCT の場合) は、このフィールド内のすべての一意のレコードのフィールドを合計します
例: SELECT name,SUM(price) AS sumprice FROM tb_price GROUP BY name
SELECT * FROM tb_name ORDER BY mount DESC,price ASC
21. 単一列データのグループ化統計
SELECT id,name,SUM(price) AS title,date FROM tb_price GROUP BY pid ORDER BY title DESC
注: グループ化ステートメントの group by sort ステートメントの order by SQL ステートメント内に同時に出現する場合は、グループ化ステートメントを並べ替えステートメントの前に記述する必要があります。そうしないとエラーが発生します
22。複数列データのグループ化統計
複数列データのグループ化統計は、次のようなものです。単一列データのグループ化統計
SELECT *, SUM( フィールド 1*フィールド 2) AS (新しいフィールド 1) FROM テーブル名 GROUP BY フィールド ORDER BY 新しいフィールド 1 DESC
SELECT id,name,SUM(price*num) AS sumprice FROM tb_price GROUP BY pid ORDER BY sumprice DESC
注: 通常、group by ステートメントの後には、集計関数ではないシーケンスが続きます。つまり、グループ化される列ではありません
23。テーブルグループ化統計
SELECT a.name,AVG(a.price),b.name,AVG( b.price) FROM tb_demo058 AS a,tb_demo058_1 AS b WHERE a.id=b.id GROUP BY b.type;
上記は MySQL、ステートメント集の内容です。その他の関連コンテンツについては、PHP 中国語 Web サイト (www.php .cn) に注目してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



