

MySQL の InnoDB インデックス原理の詳細な説明

要約:
この記事では、さまざまなツリーからインデックスの原則、ストレージの詳細まで、Mysql の InnoDB インデックスに関連する知識を紹介します。
InnoDBはMysqlのデフォルトのストレージエンジンです(Mysql5.5.5以前はMyISAMでした、ドキュメント)。効率的な学習を目的として、この記事では主に InnoDB を紹介し、比較のために少量の MyISAM を紹介します。
この記事は主に書籍やブログから抜粋したものです(参考文献を記載します) 記載に誤りがある場合はご指摘ください。
1 さまざまなツリー構造
インターネット上にはすでに関連記事が多すぎるため、当初は二分探索ツリーから始めるつもりはありませんでしたが、明確な図は問題を理解し、完全性を確保するのに非常に役立つことを考慮して、記事の 、最後にこの部分を追加しました。
まずいくつかのツリー構造を見てみましょう:
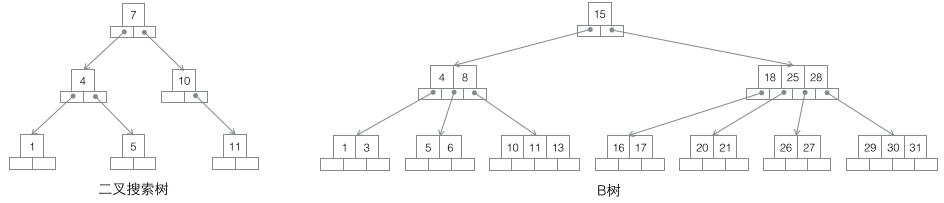
1 探索二分木: 各ノードには 2 つの子ノードがあります データ量の増加は必然的に高さの急激な増加につながります。大量のデータを保存するための基本構造。
2 B-tree: m-order B-tree はバランスのとれた m-way 探索ツリーです。最も重要な特性は、各非ルート ノードに含まれるキーワード j の数が次の条件を満たすことです。 ┌m/2┐ - 1
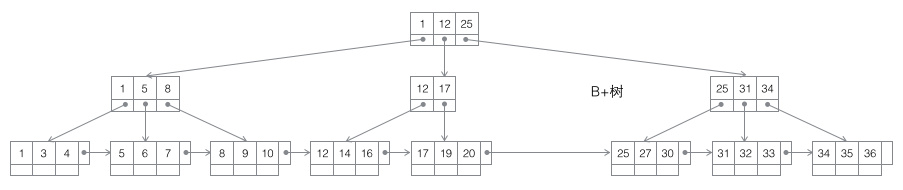
3 B+ ツリー: m 次 B ツリーは、バランスのとれた m-way 探索ツリーです。最も重要な特性は、各非ルート ノードに含まれるキーワード j の数が次の条件を満たすことです。 ┌m/2┐ - 1
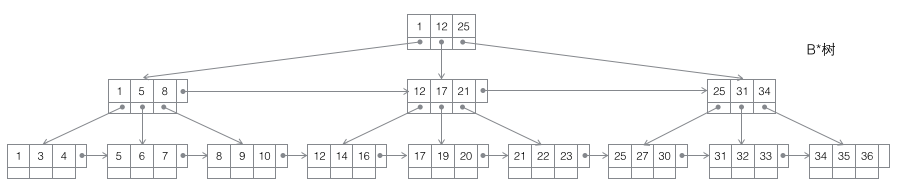
4 B* ツリー: m 次 B ツリーは、バランスのとれた m-way 探索ツリーです。最も重要なプロパティは 2 つです。 1. 各非ルート ノードに含まれるキーワード j の数は、次の条件を満たします。 ┌m2/3┐ - 1
B/B+/B* の 3 つのツリーは、ノードの取得/挿入/削除などの同様の操作を行います。ここでは、ノードを挿入する状況のみに焦点を当て、現在のノードがいっぱいになった場合の挿入操作のみを分析します。これは、このアクションが少し複雑で、複数のツリー間の違いを完全に反映する可能性があるためです。対照的に、ノードの取得は実装が比較的簡単ですが、ノードの削除には挿入の逆のプロセスを完了するだけで済みます (実際のアプリケーションでは、削除は挿入の完全な逆の操作ではなく、多くの場合、データは削除されるだけで、後続のデータのためにスペースが予約されます)。使用)。
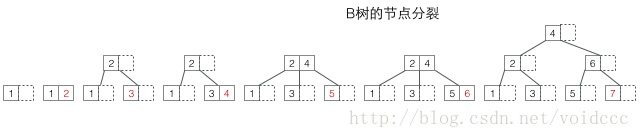
まず、B ツリーの分割を見てみましょう。下図の赤い値は、毎回新しく挿入されるノードです。ノードがいっぱいになると、必ず分割を行う必要があります (分割は再帰的なプロセスです。B ツリーの非リーフ ノードにもキーが格納されるため、以下の 7 の挿入を参照してください)。値、分割後の完全なノード値は 3 つの場所に分散されます: 1. 元のノード、2. 元のノードの親ノード、3. 元のノードの新しい兄弟ノード (「 5、7の挿入工程)。分割により木の高さが高くなる場合(3、7の挿入工程を参照)、または木の高さに影響を与えない場合(5、6の挿入工程を参照)があります。
B+ ツリー分割: ノードがいっぱいになったら、新しいノードを割り当て、元のノードのデータの 1/2 を新しいノードにコピーし、最後に新しいノードを親ノードに追加します。ポイント; B+ ツリーの分割は元のノードと親ノードにのみ影響し、兄弟ノードには影響しないため、兄弟ノードへのポインターは必要ありません。
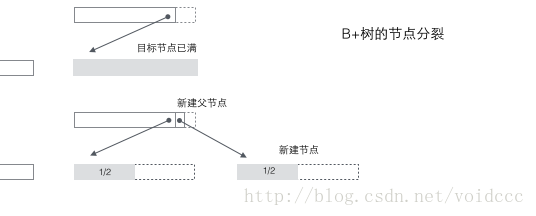
B* ツリー分割: ノードがいっぱいのとき、次の兄弟ノードがいっぱいでない場合は、データの一部を兄弟ノードに移動し、元のノードにキーワードを挿入し、最後に親ノードを変更します。兄弟のキーワードノード (兄弟ノードのキーワード範囲が変更されたため)。兄弟ノードもいっぱいの場合は、元のノードと兄弟ノードの間に新しいノードを追加し、データの 1/3 を新しいノードにコピーし、最後に新しいノードのポインタを親ノードに追加します。 B* ツリーの分割は非常に賢明であることがわかります。B* ツリーでは、分割ノードがまだ 2/3 残っていることを確認する必要があるためです。B+ ツリー手法を使用する場合、完全なノードを 2 つに分割するだけで済むからです。各ノードは 1/2 しか満たされておらず、B* ツリーの要件を満たしていません。したがって、B* ツリーが採用する戦略は、現在のノードがいっぱいになった後も、兄弟ノードもいっぱいになるまで兄弟ノードを挿入し続けることです (これが、B* ツリーが非リーフ ノードで兄弟間のリンク リストを追加する必要がある理由です)。満たされてから、兄弟ノードをプルアップすると、新しいノードを確立するために 1/3 が寄与し、その結果、3 つのノードがちょうど 2/3 になり、B* ツリーの要件を満たします。そしてみんなが幸せです。
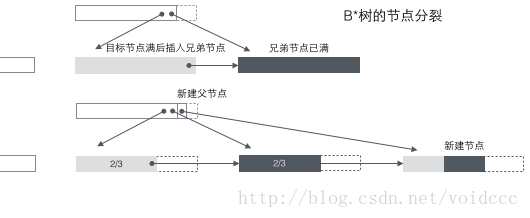
B+ツリーがデータベースの基本構造として適しているのは、その全体がコンピュータのメモリと機械式ハードディスクの二層の記憶構造によるものである。メモリは高速なランダム アクセス (ランダム アクセスとは、任意のアドレスを与え、そのアドレスに格納されているデータを返すことを意味します) を実行できますが、容量は小さいです。ハードディスクのランダムアクセスには機械的な動作(1ヘッド移動、2ディスク回転)が必要であり、アクセス効率はメモリに比べて数桁劣りますが、ハードディスクの方が大容量です。一般的なデータベース容量は使用可能なメモリ サイズを大幅に超えているため、B+ ツリー内のデータを取得するには、完了するまでに複数のディスク IO 操作が必要になる可能性があります。以下の図に示すように: 通常、ノードを読み取るアクションはディスク IO 操作である可能性がありますが、アクセスを高速化するために、非リーフ ノードは通常、初期段階でメモリにロードされます。同時に、ノード間の水平走査の速度を向上させるために、図の青色の CPU 計算/メモリ読み取りを実際のデータベースの二分探索ツリー (InnoDB のページ ディレクトリ機構) に最適化することができます。
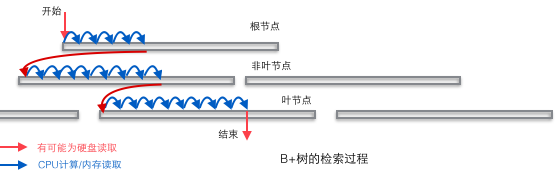
実際のデータベースの B+ ツリーは非常に平坦であるはずです。十分なデータをテーブルに順次挿入することで、InnoDB の B+ ツリーがどの程度平坦であるかを確認できます。以下に示すように、CREATE ステートメントを使用して単純なフィールドのみを含むテスト テーブルを作成し、引き続きデータを追加してこのテーブルを埋めます。以下の図の統計データを通じて、いくつかの直感的な結論を分析できます (出典については参考文献 1 を参照)。これらの結論は、データベース内の B+ ツリーの規模を巨視的に示しています。
1 各リーフノードには 468 行のデータが格納され、各非リーフノードには約 1200 個のキー値が格納されます。これはバランスの取れた 1200 方向の検索ツリーです。
2 22.1G の容量を持つテーブルの場合、それを格納するには高さ 3 の B+ ツリーのみが必要です。この容量はおそらく多くのアプリケーションのニーズを満たすことができます。高さを 4 に増やすと、B+ ツリーのストレージ容量はすぐに 25.9T という巨大な容量に増加します。
3 22.1G の容量を持つテーブルの場合、B+ ツリーの高さは 3 です。すべての非リーフ ノードをメモリにロードしたい場合、必要なメモリは 18.8M 未満だけです (これをどのように描くか)結論は、高さが 2 の場合、ツリーでは 1203 個のリーフ ノードに必要なスペースは 18.8M だけであり、22.1G のセカンダリ テーブルの高さは 3 であり、同時に 1204 個の非リーフ ノードがあると想定されます。リーフ ノードにはキーと少量のデータしかないのではなく、リーフ ノードには行が格納されるため、リーフ ノードのサイズは非リーフ ノードのサイズよりも大きくなります。)、使用できるメモリの量は非常に少量です。必要なデータを取得するために必要なディスク IO 操作は 1 つだけなので、非常に効率的です。
2 Mysql ストレージエンジンとインデックス
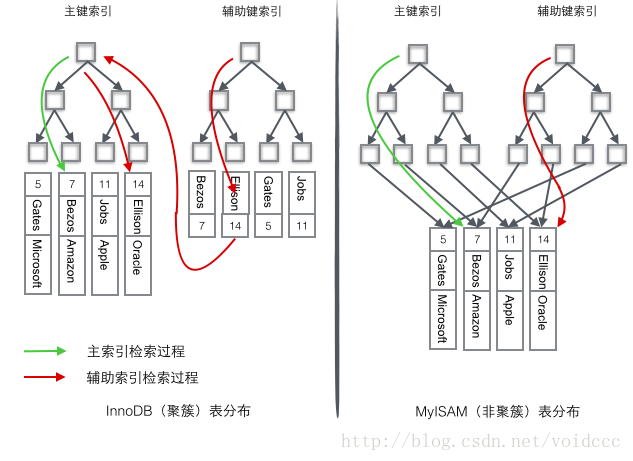
データベースにはインデックスが必要であると言えます。インデックスがないと、検索プロセスは O(n) の時間計算量でほとんど耐えられなくなります。キーがツリーのノードに格納されている限り、B+ ツリーを使用して 1 つのキーのみで構成されるテーブルにどのようにインデックスを付けることができるかを想像するのは非常に簡単です。データベース レコードに複数のフィールドが含まれる場合、B+ ツリーは主キーのみを格納できます。非主キー フィールドが取得されると、主キー インデックスはその機能を失い、再び順次検索になります。この時点で、取得する 2 番目の列に 2 番目のインデックス セットを確立する必要があります。 このインデックスは、独立した B+ ツリーによって構成されています。複数の B+ ツリーが同じテーブル データ セットにアクセスする問題を解決するには 2 つの一般的な方法があります。1 つはクラスター化インデックス (クラスター化インデックス) と呼ばれ、もう 1 つは非クラスター化インデックス (セカンダリ インデックス) と呼ばれます。これら 2 つの名前は両方ともインデックスと呼ばれますが、これらは別個のインデックス タイプではなく、データの保存方法です。クラスター化インデックス ストレージの場合、行データと主キー B+ ツリーは一緒に保存されます。副キー B+ ツリーは副キーのみを保存し、主キーと非主キー B+ ツリーはほぼ 2 種類のツリーになります。非クラスター化インデックス ストレージの場合、主キー B+ ツリーは、主キーの代わりに実際のデータ行へのポインターをリーフ ノードに保存します。
InnoDB はクラスター化インデックスを使用して主キーを B+ ツリーに編成し、行データはリーフ ノードに保存されます。「where id = 14」という条件を使用して主キーを見つける場合は、次の検索に従います。 B+ ツリー このアルゴリズムは、対応するリーフ ノードを見つけて、行データを取得します。 Name 列で条件付き検索を実行する場合は、2 つの手順が必要です。最初の手順では、補助インデックス B+ ツリーで Name を取得し、そのリーフ ノードに到達して、対応する主キーを取得します。 2 番目のステップでは、主キーを使用して主インデックス B+ ツリー種に対して別の B+ ツリー取得操作を実行し、最後にリーフ ノードに到達してデータ行全体を取得します。
MyISM は非クラスター化インデックスを使用します。非クラスター化インデックスの 2 つの B+ ツリーは見た目はまったく同じですが、主キー インデックスの B+ ツリーのノードは異なります。主キーと副キーを格納します。インデックス B+ ツリーには副キーが格納されます。テーブル データは別の場所に格納されます。テーブル データの場合、2 つの B+ ツリーのリーフ ノードはアドレスを使用して実際のテーブル データを指します。インデックスツリーは独立しているため、副キーによる検索では主キーのインデックスツリーにアクセスする必要はありません。
これら 2 つのインデックスの違いをより明確に説明するために、以下に示すように 4 行のデータを格納するテーブルを想像してみましょう。このうち、Id はプライマリ インデックスとして機能し、Name はセカンダリ インデックスとして機能します。この図は、クラスター化インデックスと非クラスター化インデックスの違いを明確に示しています。
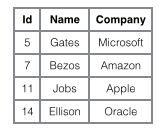
クラスター化インデックスに焦点を当てます。クラスター化インデックスの効率は、非クラスター化インデックスよりも明らかに低いようです。これは、補助インデックスを使用して取得するたびに、 B+ ツリー検索を 2 回実行しますが、これは不必要ではありません。クラスター化インデックスの利点は何ですか?
1 行データと葉ノードが一緒に格納されているため、葉ノードが見つかった場合は、データが に従って整理されていれば、すぐに行データを返すことができます。主キー ID を指定すると、データをより速く取得できます。
2 補助インデックスは、アドレス値をポインタとして使用するのではなく、主キーを「ポインタ」として使用するため、行の移動やデータページの分割が発生した場合の補助インデックスのメンテナンス作業が軽減されるという利点があります。キー値をポインタとして使用すると、補助インデックスが作成されます。より多くのスペースを必要としますが、行を移動するときに InnoDB が補助インデックスの「ポインタ」を更新する必要がないという利点があります。つまり、データベース内のデータが変更されると (前の B+ ツリー ノード分割とページ分割)、行の位置 (実装では 16K ページに配置されます。これについては後で説明します) が変更されます。クラスター化インデックスを使用できます。主キー B+ ツリーのノードがどのように変更されても、補助インデックス ツリーは影響を受けません。
3ページ構成
前の内容が原理の説明に偏っていれば、後の内容は具体的な実装に関わる内容になっていきます。
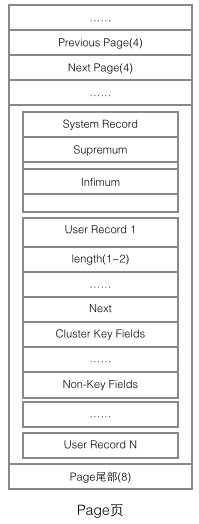
InnoDB の実装を理解するには、ページ構造について言及する必要があります。ページは InnoDB ストレージ全体の最も基本的なコンポーネントであり、データベースに関連するすべてのコンテンツはこのページ構造に保存されます。ページはいくつかのタイプに分類されます。一般的なページ タイプには、データ ページ (B ツリー ノード)、アンドゥ ページ (アンドゥ ログ ページ)、システム ページ (システム ページ)、トランザクション データ ページ (トランザクション システム ページ) などがあります。単一ページのサイズは 16K です (コンパイル マクロ UNIV_PAGE_SIZE によって制御されます)。各ページは 32 ビット int 値によって一意に識別されます。これは、InnoDB の最大ストレージ容量 64TB (16Kib * 2^32 = 64Tib) に対応します。ページの基本構造は以下のとおりです:
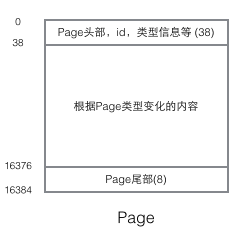
どのページにも共通の先頭と末尾がありますが、中間の内容はページの種類に応じて変わります。ページのヘッダーには、重要なデータが含まれています。次の図は、ページのヘッダーの詳細情報を示しています。
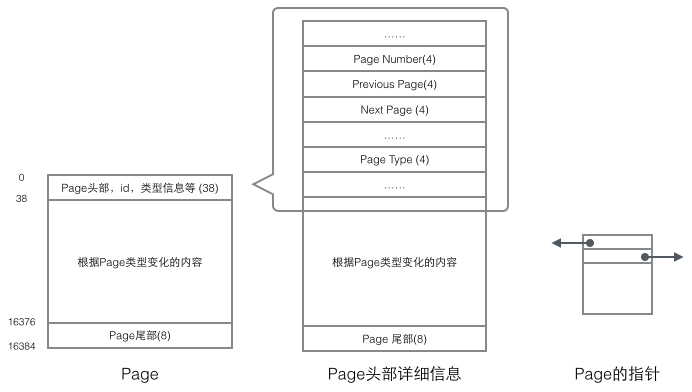
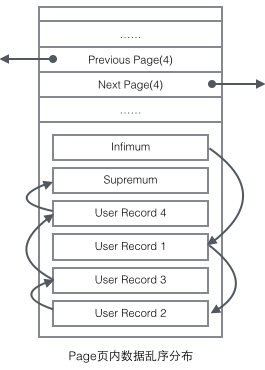
データ構成構造に関連するフィールドに焦点を当てます: ページのヘッダーは保存されます。 2 ポインタはそれぞれ前のページと次のページを指します。ヘッダーには、ページを一意に識別するために使用されるページ タイプ情報と番号も含まれています。これら 2 つのポインタに基づいて、Page が二重リンク リスト構造にリンクされていることが容易に想像できます。
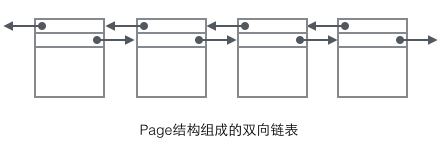
ページのメインコンテンツを見ると、主に行データとインデックスのストレージに焦点が当てられています。これらはすべてページのユーザー レコード部分にあり、ページのスペースの大部分を占めています。ユーザーレコードは、インデックスツリー上のノード(非リーフノード、リーフノード)を表すレコードを一つずつ集めて構成されます。ページ内では、単一リンクされたリストの先頭と末尾は、文字列形式の固定コンテンツを持つ 2 つのレコードによって表され、「Infimum」は先頭を表し、「Supremum」は終わりを表します。開始と終了を表すために使用されるこれら 2 つのレコードは、システム レコード セグメントに格納されます。システム レコードとユーザー レコードは、2 つの並列セグメントです。 InnoDB には 4 つの異なるレコードがあります。1 つは主キー インデックス ツリーの非リーフ ノード、2 つは主キー インデックス ツリーのリーフ ノード、3 つは補助キー インデックス ツリーの非リーフ ノード、4 つは補助キー インデックス ツリーのリーフ ノードです。これら 4 つのノードのレコード形式にはいくつかの違いがありますが、いずれも次のレコードを指す Next ポインターを格納します。これら 4 種類のノードについては後で詳しく説明します。現時点では、Record をデータを格納し、Next ポインターを含む単一リンク リスト ノードとして扱うだけで済みます。
ユーザーレコードは、ページ内に単一リンクされたリストの形式で存在します。最初、データは挿入された順に配置されますが、新しいデータが挿入され、古いデータが削除されると、データの物理的な順序が変わります。カオスになりますが、それでも論理的な順序は維持されます。
ユーザーレコードの組織形態といくつかのページを組み合わせると、少し完成した形態が見られます。
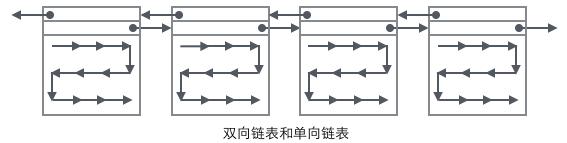
次に、レコードを見つける方法を見てみましょう:
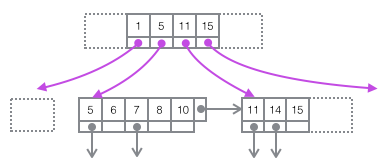
1. ルート ノードを介してインデックス付き B+ ツリーのトラバースを開始し、最終的に各レベルの非リーフ ノードを介してページに到達します。このページにはリーフ ノードが格納されます。
2 ページ内の「Infimum」ノードから開始して単一リンクリストを走査し (このタイプの走査は多くの場合最適化されます)、キーが見つかると、そのキーが正常に返されます。レコードが「最高」に達した場合は、現在のページに適切なキーがないことを意味します。この時点で、ページの次のページ ポインターを使用して次のページにジャンプし、先頭から 1 つずつ検索を続ける必要があります。 「インフィムム」。
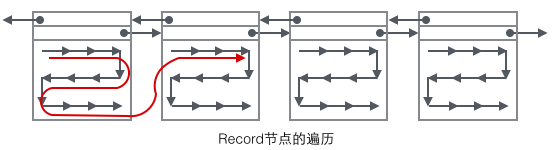
さまざまなタイプのレコードにどのようなデータが保存されているかを詳しく見てみましょう。B+ ツリー ノードに応じて、ユーザー レコードは 4 つの形式に分けられ、以下の図で色で区別されます。
1 メインインデックスツリーの非リーフノード(緑)
1 B+ツリーに必要な子ノードに格納されている主キーの最小値(Min Cluster Key on Child)であり、その関数はページ内の特定の値を検索する 記録された場所。
2 レコードを見つけるために使用される、最小値が配置されているページの番号 (子ページ番号)。
2 主インデックスツリーのリーフノード(黄色)
1 主キー(クラスターキーフィールド)、B+ツリーに必要で、データ行の一部でもあります
2 主キー(非キーフィールド)を除くすべての列)、これは主キーを除くデータ行の他のすべての列のセットです。
ここでの 2 つの部分 1 と 2 を合計すると、完全なデータ行になります。
3 補助インデックスツリー非リーフノード 非(青色)
1 子ノードに格納されている補助キーの値のうち最小の値(Min Secondary-Key on Child)、これはB+ツリーに必要で、その機能は、ページ内の特定のレコードの場所を見つけることです。
2 主キーの値(クラスターキーフィールド)、なぜ非リーフノードは主キーを格納するのでしょうか?補助インデックスは一意でなくてもかまいませんが、B+ ツリーではキー値が一意である必要があるため、ここでは補助キーの値と主キーの値が B+ ツリー内の実際のキー値として結合されます。一意性の確保。しかし、これにより、補助インデックス B+ ツリー内の非リーフ ノードがリーフ ノードよりも 4 バイト多くなる結果になります。 (つまり、下の図の青いノードは赤いノードより 4 バイト多いです)
3 レコードを見つけるために使用される、最小値が配置されるページの番号 (子ページ番号)。
4 補助インデックスツリーのリーフノード(赤)
1 B+ツリーに必要な補助インデックスキー値(セカンダリキーフィールド)。
2 主キー値 (クラスター キー フィールド)。レコード全体を見つけるためにメイン インデックス ツリーで別の B+ ツリー検索を実行するために使用されます。
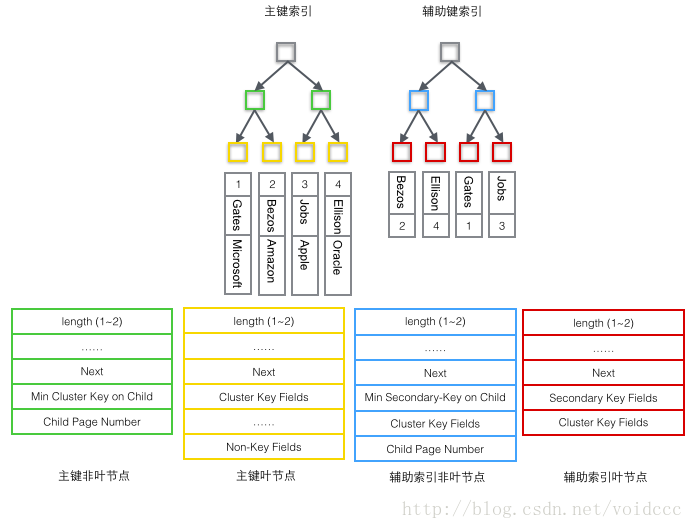
以下は、この記事の最も重要な部分です。B+ ツリーの構造と、先ほど紹介した 4 種類のレコードの内容を組み合わせることで、最終的にパノラマ図を描くことができます。補助インデックスの B+ ツリーは主キー インデックスと同様の構造を持つため、ここでは主キー インデックス ツリーの構造図のみを描画します。これには、「主キー非リーフ ノード」と「」の 2 種類のノードのみが含まれます。 「主キーリーフノード」、上図の2種類のノードです。緑色と黄色の部分です。
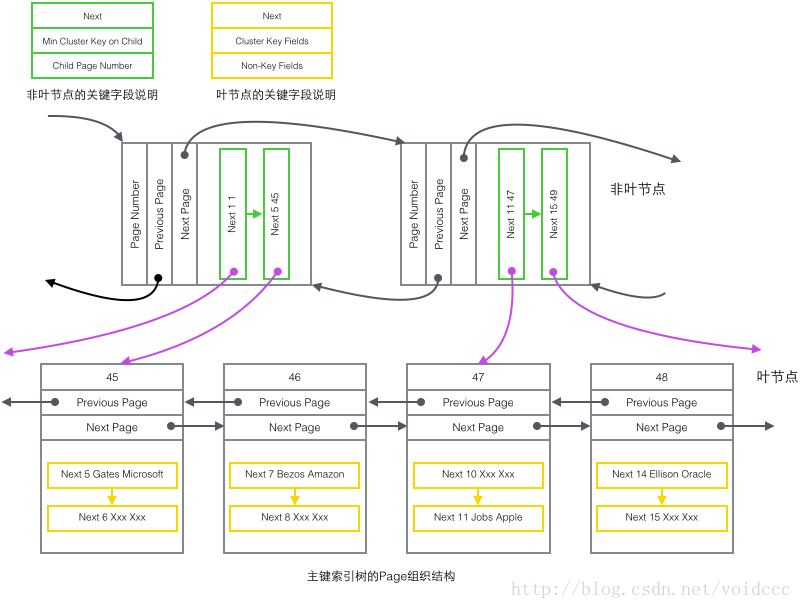
上の図を以下のより簡潔なツリー図に復元します。これは B+ ツリーの一部です。 Page と B+ ツリー ノードの間には 1 対 1 の対応関係がないことに注意してください。Page は、ディスク領域のバッチ管理を容易にするためにのみ使用されます。ツリー形状では、構造は 2 つの独立したノードに分割されます。
この記事はInnoDBインデックスに関するデータ構造と実装をまとめただけであり、Mysqlの実体験については触れません。これは主にいくつかの理由に基づいています:
1 原則は InnoDB インデックスの仕組みを完全に理解することによってのみ、効率的に使用できるようになります。
2 原理知識は図を使うのに特に適しています。私はこの表現方法がとても好きです。
3 InnoDB の最適化については、「High Performance Mysql」にさらに包括的な紹介があり、Mysql の最適化に興味のある学生は、自分で関連する知識を得ることができます。
もう 1 つ: InnoDB の実装に興味のある学生は、Jeremy Cole のブログ (3 つの参考記事のソース) を参照してください。この男性は、Mysql、Yahoo、Twitter、Google でデータベース関連の仕事に携わってきました。
上記は MySQL の InnoDB インデックス原理の詳細な説明です。さらに関連する内容については、PHP 中国語 Web サイト (www.php.cn) に注目してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7333
7333
 9
1627
14
1351
46
1262
25
1209
29
9
1627
14
1351
46
1262
25
1209
29

 PHPのビッグデータ構造処理スキル
May 08, 2024 am 10:24 AM
PHPのビッグデータ構造処理スキル
May 08, 2024 am 10:24 AM
ビッグ データ構造の処理スキル: チャンキング: データ セットを分割してチャンクに処理し、メモリ消費を削減します。ジェネレーター: データ セット全体をロードせずにデータ項目を 1 つずつ生成します。無制限のデータ セットに適しています。ストリーミング: ファイルやクエリ結果を 1 行ずつ読み取ります。大きなファイルやリモート データに適しています。外部ストレージ: 非常に大規模なデータ セットの場合は、データをデータベースまたは NoSQL に保存します。
 PHP で MySQL クエリのパフォーマンスを最適化するにはどうすればよいですか?
Jun 03, 2024 pm 08:11 PM
PHP で MySQL クエリのパフォーマンスを最適化するにはどうすればよいですか?
Jun 03, 2024 pm 08:11 PM
MySQL クエリのパフォーマンスは、検索時間を線形の複雑さから対数の複雑さまで短縮するインデックスを構築することで最適化できます。 PreparedStatement を使用して SQL インジェクションを防止し、クエリのパフォーマンスを向上させます。クエリ結果を制限し、サーバーによって処理されるデータ量を削減します。適切な結合タイプの使用、インデックスの作成、サブクエリの使用の検討など、結合クエリを最適化します。クエリを分析してボトルネックを特定し、キャッシュを使用してデータベースの負荷を軽減し、オーバーヘッドを最小限に抑えます。
 PHP で MySQL のバックアップと復元を使用するにはどうすればよいですか?
Jun 03, 2024 pm 12:19 PM
PHP で MySQL のバックアップと復元を使用するにはどうすればよいですか?
Jun 03, 2024 pm 12:19 PM
PHP で MySQL データベースをバックアップおよび復元するには、次の手順を実行します。 データベースをバックアップします。 mysqldump コマンドを使用して、データベースを SQL ファイルにダンプします。データベースの復元: mysql コマンドを使用して、SQL ファイルからデータベースを復元します。
 PHP を使用して MySQL テーブルにデータを挿入するにはどうすればよいですか?
Jun 02, 2024 pm 02:26 PM
PHP を使用して MySQL テーブルにデータを挿入するにはどうすればよいですか?
Jun 02, 2024 pm 02:26 PM
MySQLテーブルにデータを挿入するにはどうすればよいですか?データベースに接続する: mysqli を使用してデータベースへの接続を確立します。 SQL クエリを準備します。挿入する列と値を指定する INSERT ステートメントを作成します。クエリの実行: query() メソッドを使用して挿入クエリを実行します。成功すると、確認メッセージが出力されます。
 MySQL 8.4 で mysql_native_password がロードされていないエラーを修正する方法
Dec 09, 2024 am 11:42 AM
MySQL 8.4 で mysql_native_password がロードされていないエラーを修正する方法
Dec 09, 2024 am 11:42 AM
MySQL 8.4 (2024 年時点の最新の LTS リリース) で導入された主な変更の 1 つは、「MySQL Native Password」プラグインがデフォルトで有効ではなくなったことです。さらに、MySQL 9.0 ではこのプラグインが完全に削除されています。 この変更は PHP および他のアプリに影響します
 PHP で MySQL ストアド プロシージャを使用するにはどうすればよいですか?
Jun 02, 2024 pm 02:13 PM
PHP で MySQL ストアド プロシージャを使用するにはどうすればよいですか?
Jun 02, 2024 pm 02:13 PM
PHP で MySQL ストアド プロシージャを使用するには: PDO または MySQLi 拡張機能を使用して、MySQL データベースに接続します。ストアド プロシージャを呼び出すステートメントを準備します。ストアド プロシージャを実行します。結果セットを処理します (ストアド プロシージャが結果を返す場合)。データベース接続を閉じます。
 PHP を使用して MySQL テーブルを作成するにはどうすればよいですか?
Jun 04, 2024 pm 01:57 PM
PHP を使用して MySQL テーブルを作成するにはどうすればよいですか?
Jun 04, 2024 pm 01:57 PM
PHP を使用して MySQL テーブルを作成するには、次の手順が必要です。 データベースに接続します。データベースが存在しない場合は作成します。データベースを選択します。テーブルを作成します。クエリを実行します。接続を閉じます。
 Oracleデータベースとmysqlの違い
May 10, 2024 am 01:54 AM
Oracleデータベースとmysqlの違い
May 10, 2024 am 01:54 AM
Oracle データベースと MySQL はどちらもリレーショナル モデルに基づいたデータベースですが、Oracle は互換性、スケーラビリティ、データ型、セキュリティの点で優れており、MySQL は速度と柔軟性に重点を置いており、小規模から中規模のデータ セットに適しています。 ① Oracle は幅広いデータ型を提供し、② 高度なセキュリティ機能を提供し、③ エンタープライズレベルのアプリケーションに適しています。① MySQL は NoSQL データ型をサポートし、② セキュリティ対策が少なく、③ 小規模から中規模のアプリケーションに適しています。
