

XML - XML 解析用の DOM

1.XML编程
XML编程,就是对XML文件进行crud操作。
那么为什么要用java或者C/C++对XML进行crud操作呢?
1.XML作为数据传递需要解析
2.XML作为配置文件需要读取
3.XML作为小型数据库,需要进行crud操作
w3C组织为了大家解析XML方便,定义了一套规范(API)
1.1.XML解析技术介绍
1.XML解析分为:dom解析和sax解析
dom:(Document Object Model,即文档对象模型),是W3C组织推荐的处理XML的一种方式
sax:(Simple API for XML),不是官方标准,但它是XML社区事实上的标准,几乎所有的XML解析器都支持它
SAX解析采用事件驱动模型边读边解析:从上到下一行一行解析,解析到某一元素,调用相应的解析方法。
DOM根据XML层级结构在内存中分配一个树形结构,把XML的标签,属性和文本等元素都封装成树的节点对象。
不同的公司和组织提供了针对DOM和SAX两种方式的解析器:
Sun的JAXP
Dom4j组织的dom4j(最常用,例如hibernate)
JDom组织的jdom
其中的JASP是J2SE的一部分,它分别针对DOM和SAX提供了DOM和SAX解析器。
在这里也主要介绍三种解析:dom、sax和dom4j
1.2.JAXP介绍
Sun公司提供了Java API for XML Parsing(JAXP)接口来使用SAX和DOM,通过JAXP,我们可以使用任何与JAXP兼容的XML解析器。
JAXP开发包是J2SE的一部分,它由javax.xml、org.w3c.dom、org.xml.sax包及其子包组成
在javax.xml.parsers包中,定义了几个工厂类,程序员调用这些工厂类,可以得到对xml文档进行解析的DOM或SAX的解析器对象。
2.JAXP之DOM解析
2.1.XML DOM节点树
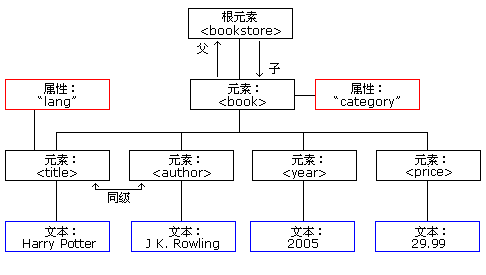
首先说明JAXP解析XML的DOM对象的原理,XML DOM把XML文档视为一颗节点树(node-tree),树中的所有节点彼此之间都有关系。可通过这棵树访问所有的节点。可以修改或者删除它们的内容,也可以创建新的元素。
比如,现在的XML文档如下(该例子来自w3cschool在线教程):
<bookstore>
<book category="children">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="cooking">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="web" cover="paperback">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
<book category="web">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49.99</price>
</book></bookstore>这棵树从根节点开始,在树的最低层级向文本节点长出枝条:
【要知道的几个知识点】:
1.dom会把xml文件看做一棵树,并加载到内存
2.dom特别适合做crud操作
3.dom不太适合去操作比较大的xml文件(占用内存)
4.dom会把xml文件中每一个元素、属性、文本都映射成对应的Node对象。
2.2.获得JAXP中的DOM解析器步骤
1.调用DocumentBuilderFactory.newInstance()方法得到创建DOM解析器的工厂
2.调用工厂对象的newDocumentBuilder方法得到DOM解析器对象
3.调用DOM解析器对象的parse()方法解析XML文档,得到代表整个文档的Document对象,进行可以利用DOM特性对整个XML文档进行操作了。
2.3.JAXP之DOM解析实例:
XML文档如下:
<?xml version="1.0" encoding="utf-8"?><班级>
<学生 地址="香港">
<名字>周小星</名字>
<年龄>23</年龄>
<介绍>学习刻苦</介绍>
</学生>
<学生 地址="澳门">
<名字>林晓</名字>
<年龄>25</年龄>
<介绍>是一个好学生</介绍>
</学生> </班级>2.3.1.读取XML文档
首先使用2.2中介绍了三个步骤得到代表整个文档的document对象,并调用我们所写的read(Document document)方法,如下:
// 1.创建一个DocumentBuilderFactoryDocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// 2.通过工厂实例得到DocumentBuilder对象DocumentBuilder builder = factory.newDocumentBuilder();
// 3.指定要解析的xml文件,返回document对象Document document = builder.parse(new File("src/myClass.xml"));
read(document);其中的read方法是这么写的:
/**
* 显示所有学生的所有信息
* @param document
*/public static void read(Document document){ // 通过学生这个标签名字得到NodeList
NodeList nodeList = document.getElementsByTagName("学生");
for(int i=0;i<nodeList.getLength();i++){ // 因为Element是Node的子接口,所有这里可以转换成Element
// 从而可以使用更多的方法
Element student = (Element)nodeList.item(i); // 获取属性
String address = student.getAttribute("地址");
System.out.println(address); // 得到学生的所有子节点,并循环输出
NodeList childList = student.getChildNodes(); for(int j=0;j<childList.getLength();j++){
Node node = childList.item(j); if(node.getNodeType() == Node.ELEMENT_NODE)
System.out.println(node.getNodeName()+":"+node.getTextContent());
}
System.out.println("-------------");
} // 这样一层一层向下查询也可以
//Element name = (Element)student.getElementsByTagName("名字").item(0);
//System.out.println(name.getTextContent()); }最后的XML - XML 解析用の DOM如下所示:

2.3.2.更新XML文档
利用DOM更新XML文档一定要使用Transformer类将更改写入文件,否则只是更改了在内存中的XML文档对象。
javax.xml.transform包中的Transformer类用于把代表XML文件的Document对象转换为某种格式后进行输出,例如把xml文件应用样式表后转成一个html文档。利用这个对象,当然也可以把Document对象又重新写回到一个XML文件中
Transformer类通过transform方法完成转换操作,该方法接收一个源和一个目的地。我们可以通过:
javax.xml.transform.dom.DOMSource类来关联要转换的document对象
用javax.xml.transform.stream.StreamResult对象来表示数据的目的地
Transformer对象通过TransformerFactory获得
【1】添加元素
我们可以向上述XML中添加一个学生子节点,如下:
/**
* 添加学生
*
* @param document
* @throws Exception
*/public static void add(Document document) throws Exception { // 创建一个新的学生节点
Element newStudent = document.createElement("学生"); // 给新的学生添加地址属性
newStudent.setAttribute("地址", "旧金山"); // 创建学生的子节点
Element newStudent_name = document.createElement("名字");
newStudent_name.setTextContent("小明");
Element newStudent_age = document.createElement("年龄");
newStudent_age.setTextContent("25");
Element newStudent_intro = document.createElement("介绍");
newStudent_intro.setTextContent("这是一个好孩子"); // 将子节点添加到学生节点上
newStudent.appendChild(newStudent_name);
newStudent.appendChild(newStudent_age);
newStudent.appendChild(newStudent_intro); // 把新的学生节点添加到根节点下
document.getDocumentElement().appendChild(newStudent); // 更新XML文档
// 得到TransformerFactory
TransformerFactory tff = TransformerFactory.newInstance(); // 通过TransformerFactory得到一个转换器
Transformer tf = tff.newTransformer(); // 更新当前的XML文件
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【2】删除元素
同样的,我们也可以删除一个学生节点,如下:
/**
* 删除第一个学生节点
*
* @param document
*/public static void delete(Document document) throws Exception { // 首先找到这个学生,这里可以不用转为Element
Node student = document.getElementsByTagName("学生").item(0); // 通过它的父节点来删除
student.getParentNode().removeChild(student); // 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【3】更改元素的值
比如,我们也可以将第一个学生的名字改为松江,如下:
/**
* 把第一个学生的元素名字改为宋江
*
* @param document
*/public static void update_name(Document document) throws Exception{
Element student = (Element) document.getElementsByTagName("学生").item(0);
Element name = (Element) student.getElementsByTagName("名字").item(0);
name.setTextContent("宋江"); // 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【4】更改或删除元素的属性
/**
* 删除第一个学生节点的属性
*
* @param document
*/public static void delete_attribute(Document document) throws Exception { // 首先找到这个学生
Element student = (Element) document.getElementsByTagName("学生").item(0); // 删除student的地址属性
student.removeAttribute("地址"); // 更新属性
// student.setAttribute("地址", "新地址");
// 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}上述列举了几个更新元素(节点)的例子,更一般的需求是这样的:将名字是周小星的同学的年龄改为30,这时候我们需要去遍历XML文档,找到对应的节点,再进行修改。
另外,所有关于更新的方法中都用到了TransformerFactory来进行实际的更新,所以,我们可以把这三句话写成一个函数,从而避免代码冗余,如下:
public static void update(Document document, String path) throws Exception {
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File(path)));
}1.XML编程
XML编程,就是对XML文件进行crud操作。
那么为什么要用java或者C/C++对XML进行crud操作呢?
1.XML作为数据传递需要解析
2.XML作为配置文件需要读取
3.XML作为小型数据库,需要进行crud操作
w3C组织为了大家解析XML方便,定义了一套规范(API)
1.1.XML解析技术介绍
1.XML解析分为:dom解析和sax解析
dom:(Document Object Model,即文档对象模型),是W3C组织推荐的处理XML的一种方式
sax:(Simple API for XML),不是官方标准,但它是XML社区事实上的标准,几乎所有的XML解析器都支持它
SAX解析采用事件驱动模型边读边解析:从上到下一行一行解析,解析到某一元素,调用相应的解析方法。
DOM根据XML层级结构在内存中分配一个树形结构,把XML的标签,属性和文本等元素都封装成树的节点对象。
不同的公司和组织提供了针对DOM和SAX两种方式的解析器:
Sun的JAXP
Dom4j组织的dom4j(最常用,例如hibernate)
JDom组织的jdom
其中的JASP是J2SE的一部分,它分别针对DOM和SAX提供了DOM和SAX解析器。
在这里也主要介绍三种解析:dom、sax和dom4j
1.2.JAXP介绍
Sun公司提供了Java API for XML Parsing(JAXP)接口来使用SAX和DOM,通过JAXP,我们可以使用任何与JAXP兼容的XML解析器。
JAXP开发包是J2SE的一部分,它由javax.xml、org.w3c.dom、org.xml.sax包及其子包组成
在javax.xml.parsers包中,定义了几个工厂类,程序员调用这些工厂类,可以得到对xml文档进行解析的DOM或SAX的解析器对象。
2.JAXP之DOM解析
2.1.XML DOM节点树
首先说明JAXP解析XML的DOM对象的原理,XML DOM把XML文档视为一颗节点树(node-tree),树中的所有节点彼此之间都有关系。可通过这棵树访问所有的节点。可以修改或者删除它们的内容,也可以创建新的元素。
比如,现在的XML文档如下(该例子来自w3cschool在线教程):
<bookstore>
<book category="children">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="cooking">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="web" cover="paperback">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
<book category="web">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49.99</price>
</book></bookstore>这棵树从根节点开始,在树的最低层级向文本节点长出枝条:
【要知道的几个知识点】:
1.dom会把xml文件看做一棵树,并加载到内存
2.dom特别适合做crud操作
3.dom不太适合去操作比较大的xml文件(占用内存)
4.dom会把xml文件中每一个元素、属性、文本都映射成对应的Node对象。
2.2.获得JAXP中的DOM解析器步骤
1.调用DocumentBuilderFactory.newInstance()方法得到创建DOM解析器的工厂
2.调用工厂对象的newDocumentBuilder方法得到DOM解析器对象
3.调用DOM解析器对象的parse()方法解析XML文档,得到代表整个文档的Document对象,进行可以利用DOM特性对整个XML文档进行操作了。
2.3.JAXP之DOM解析实例:
XML文档如下:
<?xml version="1.0" encoding="utf-8"?><班级>
<学生 地址="香港">
<名字>周小星</名字>
<年龄>23</年龄>
<介绍>学习刻苦</介绍>
</学生>
<学生 地址="澳门">
<名字>林晓</名字>
<年龄>25</年龄>
<介绍>是一个好学生</介绍>
</学生> </班级>2.3.1.读取XML文档
首先使用2.2中介绍了三个步骤得到代表整个文档的document对象,并调用我们所写的read(Document document)方法,如下:
// 1.创建一个DocumentBuilderFactoryDocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// 2.通过工厂实例得到DocumentBuilder对象DocumentBuilder builder = factory.newDocumentBuilder();
// 3.指定要解析的xml文件,返回document对象Document document = builder.parse(new File("src/myClass.xml"));
read(document);其中的read方法是这么写的:
/**
* 显示所有学生的所有信息
* @param document
*/public static void read(Document document){ // 通过学生这个标签名字得到NodeList
NodeList nodeList = document.getElementsByTagName("学生");
for(int i=0;i<nodeList.getLength();i++){ // 因为Element是Node的子接口,所有这里可以转换成Element
// 从而可以使用更多的方法
Element student = (Element)nodeList.item(i); // 获取属性
String address = student.getAttribute("地址");
System.out.println(address); // 得到学生的所有子节点,并循环输出
NodeList childList = student.getChildNodes(); for(int j=0;j<childList.getLength();j++){
Node node = childList.item(j); if(node.getNodeType() == Node.ELEMENT_NODE)
System.out.println(node.getNodeName()+":"+node.getTextContent());
}
System.out.println("-------------");
} // 这样一层一层向下查询也可以
//Element name = (Element)student.getElementsByTagName("名字").item(0);
//System.out.println(name.getTextContent()); }最后的XML - XML 解析用の DOM如下所示:
2.3.2.更新XML文档
利用DOM更新XML文档一定要使用Transformer类将更改写入文件,否则只是更改了在内存中的XML文档对象。
javax.xml.transform包中的Transformer类用于把代表XML文件的Document对象转换为某种格式后进行输出,例如把xml文件应用样式表后转成一个html文档。利用这个对象,当然也可以把Document对象又重新写回到一个XML文件中
Transformer类通过transform方法完成转换操作,该方法接收一个源和一个目的地。我们可以通过:
javax.xml.transform.dom.DOMSource类来关联要转换的document对象
用javax.xml.transform.stream.StreamResult对象来表示数据的目的地
Transformer对象通过TransformerFactory获得
【1】添加元素
我们可以向上述XML中添加一个学生子节点,如下:
/**
* 添加学生
*
* @param document
* @throws Exception
*/public static void add(Document document) throws Exception { // 创建一个新的学生节点
Element newStudent = document.createElement("学生"); // 给新的学生添加地址属性
newStudent.setAttribute("地址", "旧金山"); // 创建学生的子节点
Element newStudent_name = document.createElement("名字");
newStudent_name.setTextContent("小明");
Element newStudent_age = document.createElement("年龄");
newStudent_age.setTextContent("25");
Element newStudent_intro = document.createElement("介绍");
newStudent_intro.setTextContent("这是一个好孩子"); // 将子节点添加到学生节点上
newStudent.appendChild(newStudent_name);
newStudent.appendChild(newStudent_age);
newStudent.appendChild(newStudent_intro); // 把新的学生节点添加到根节点下
document.getDocumentElement().appendChild(newStudent); // 更新XML文档
// 得到TransformerFactory
TransformerFactory tff = TransformerFactory.newInstance(); // 通过TransformerFactory得到一个转换器
Transformer tf = tff.newTransformer(); // 更新当前的XML文件
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【2】删除元素
同样的,我们也可以删除一个学生节点,如下:
/**
* 删除第一个学生节点
*
* @param document
*/public static void delete(Document document) throws Exception { // 首先找到这个学生,这里可以不用转为Element
Node student = document.getElementsByTagName("学生").item(0); // 通过它的父节点来删除
student.getParentNode().removeChild(student); // 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【3】更改元素的值
比如,我们也可以将第一个学生的名字改为松江,如下:
/**
* 把第一个学生的元素名字改为宋江
*
* @param document
*/public static void update_name(Document document) throws Exception{
Element student = (Element) document.getElementsByTagName("学生").item(0);
Element name = (Element) student.getElementsByTagName("名字").item(0);
name.setTextContent("宋江"); // 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}【4】更改或删除元素的属性
/**
* 删除第一个学生节点的属性
*
* @param document
*/public static void delete_attribute(Document document) throws Exception { // 首先找到这个学生
Element student = (Element) document.getElementsByTagName("学生").item(0); // 删除student的地址属性
student.removeAttribute("地址"); // 更新属性
// student.setAttribute("地址", "新地址");
// 更新这个文档
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File( "src/myClass.xml")));
}上述列举了几个更新元素(节点)的例子,更一般的需求是这样的:将名字是周小星的同学的年龄改为30,这时候我们需要去遍历XML文档,找到对应的节点,再进行修改。
另外,所有关于更新的方法中都用到了TransformerFactory来进行实际的更新,所以,我们可以把这三句话写成一个函数,从而避免代码冗余,如下:
public static void update(Document document, String path) throws Exception {
TransformerFactory tff = TransformerFactory.newInstance();
Transformer tf = tff.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File(path)));
} 以上就是XML—XML解析之DOM的内容,更多相关内容请关注PHP中文网(www.php.cn)!

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7715
7715
 15
1641
14
1395
52
1289
25
1232
29
15
1641
14
1395
52
1289
25
1232
29

 PowerPoint を使用して XML ファイルを開くことはできますか?
Feb 19, 2024 pm 09:06 PM
PowerPoint を使用して XML ファイルを開くことはできますか?
Feb 19, 2024 pm 09:06 PM
XML ファイルは PPT で開くことができますか? XML、Extensible Markup Language (Extensible Markup Language) は、データ交換とデータ ストレージで広く使用されている汎用マークアップ言語です。 HTML と比較して、XML はより柔軟であり、独自のタグとデータ構造を定義できるため、データの保存と交換がより便利で統一されます。 PPT (PowerPoint) は、プレゼンテーションを作成するために Microsoft によって開発されたソフトウェアです。包括的な方法を提供します。
 Python で XML データを CSV 形式に変換する
Aug 11, 2023 pm 07:41 PM
Python で XML データを CSV 形式に変換する
Aug 11, 2023 pm 07:41 PM
Python の XML データを CSV 形式に変換する XML (ExtensibleMarkupLanguage) は、データの保存と送信に一般的に使用される拡張可能なマークアップ言語です。 CSV (CommaSeparatedValues) は、データのインポートとエクスポートに一般的に使用されるカンマ区切りのテキスト ファイル形式です。データを処理するとき、分析や処理を容易にするために、XML データを CSV 形式に変換する必要がある場合があります。 Pythonは強力です
 Python は XML と JSON 間の変換を実装します
Aug 07, 2023 pm 07:10 PM
Python は XML と JSON 間の変換を実装します
Aug 07, 2023 pm 07:10 PM
Python は XML と JSON 間の変換を実装します はじめに: 日常の開発プロセスでは、異なる形式間でデータを変換する必要があることがよくあります。 XML と JSON は一般的なデータ交換形式であり、Python ではさまざまなライブラリを使用して XML と JSON の間で変換できます。この記事では、一般的に使用されるいくつかの方法をコード例とともに紹介します。 1. Python で XML を JSON に変換するには、xml.etree.ElementTree モジュールを使用できます。
 Python を使用した XML でのエラーと例外の処理
Aug 08, 2023 pm 12:25 PM
Python を使用した XML でのエラーと例外の処理
Aug 08, 2023 pm 12:25 PM
Python を使用した XML でのエラーと例外の処理 XML は、構造化データの保存と表現に使用される一般的に使用されるデータ形式です。 Python を使用して XML を処理すると、エラーや例外が発生することがあります。この記事では、Python を使用して XML のエラーと例外を処理する方法を紹介し、参考用のサンプル コードをいくつか示します。 Try-Except ステートメントを使用して XML 解析エラーを捕捉する Python を使用して XML を解析すると、時々、次のようなエラーが発生することがあります。
 Python は XML 内の特殊文字とエスケープ シーケンスを解析します
Aug 08, 2023 pm 12:46 PM
Python は XML 内の特殊文字とエスケープ シーケンスを解析します
Aug 08, 2023 pm 12:46 PM
Python は XML 内の特殊文字とエスケープ シーケンスを解析します XML (eXtensibleMarkupLanguage) は、異なるシステム間でデータを転送および保存するために一般的に使用されるデータ交換形式です。 XML ファイルを処理する場合、特殊文字やエスケープ シーケンスが含まれる状況に遭遇することが多く、これにより解析エラーやデータの誤解が生じる可能性があります。したがって、Python を使用して XML ファイルを解析する場合は、これらの特殊文字とエスケープ シーケンスの処理方法を理解する必要があります。 1. 特殊文字と
 C# 開発で XML および JSON データ形式を処理する方法
Oct 09, 2023 pm 06:15 PM
C# 開発で XML および JSON データ形式を処理する方法
Oct 09, 2023 pm 06:15 PM
C# 開発で XML および JSON データ形式を処理する方法には、特定のコード サンプルが必要です。現代のソフトウェア開発では、XML と JSON の 2 つのデータ形式が広く使用されています。 XML (Extensible Markup Language) はデータの保存と送信に使用されるマークアップ言語であり、JSON (JavaScript Object Notation) は軽量のデータ交換形式です。 C# 開発では、XML と JSON データの処理と操作が必要になることがよくありますが、この記事では、C# を使用してこれら 2 つのデータ形式を処理し、添付する方法に焦点を当てます。
 Python を使用して XML でデータ検証を実装する
Aug 10, 2023 pm 01:37 PM
Python を使用して XML でデータ検証を実装する
Aug 10, 2023 pm 01:37 PM
Python を使用した XML でのデータ検証の実装 はじめに: 実生活ではさまざまなデータを扱うことがよくありますが、その中でも XML (Extensible Markup Language) は一般的に使用されるデータ形式です。 XML は可読性と拡張性に優れており、データ交換や設定ファイルなどさまざまな分野で広く使用されています。 XML データを処理する場合、多くの場合、データの整合性と正確性を確認するためにデータを検証する必要があります。この記事では、Python を使用して XML でデータ検証を実装し、対応する
 Python が XML ファイルを解析する方法
Aug 09, 2023 am 11:48 AM
Python が XML ファイルを解析する方法
Aug 09, 2023 am 11:48 AM
Python による XML ファイルの解析方法 XML (eXtensibleMarkupLanguage) は、構造化データを表すために使用されるマークアップ言語です。 XML データを処理する場合、多くの場合、XML ファイルを解析して必要な情報を抽出する必要があります。 Python は、ElementTree、lxml など、XML ファイルを解析するための多くのライブラリとモジュールを提供します。この記事では、Python を使用して XML ファイルを解析する方法をコード例とともに紹介します。 Pythonでは、
