

Java メモリ モデルの詳細な紹介

この Java メモリ モデルは、Java 仮想マシンがコンピュータ メモリ (RAM) でどのように動作するかを指定します。この Java 仮想マシンはコンピュータ全体のモデルであるため、このモデルには当然、Java メモリ モデルとも呼ばれるメモリ モデルが含まれます。
同時実行プログラムを正しく設計したい場合は、Java メモリ モデルを理解することが重要です。この Java メモリ モデルは、別のスレッドが他のスレッドによって書き込まれた共有変数の値をいつどのように確認できるか、また共有変数に同期的にアクセスする方法を指します。
元の Java メモリ モデルでは不十分だったので、Java 1.5 では Java メモリ モデルが改良されました。このバージョンの Java メモリ モデルは、Java 8 でも引き続き使用されます。
内部 Java メモリ モデル
Java メモリ モデルは、JVM 内部でスレッド スタックとヒープに分割して使用されます。この図は、論理的な観点からメモリ モデルを示しています。
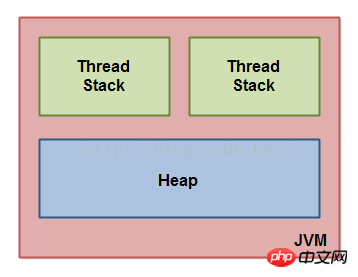
Java 仮想マシンで実行されているすべてのスレッドには、独自のスレッド スタックがあります。スレッド スタックには、現在の実行時点までにこのスレッドが呼び出したメソッドに関する情報が含まれています。これを「コールスタック」とも呼びます。スレッドがコードを実行すると、この呼び出しスタックが変化します。
このスレッド スタックには、実行される各メソッド (呼び出しスタック上のすべてのメソッド) のすべてのローカル変数も含まれます。スレッドは、自身のスレッド スタックにのみアクセスできます。 1 つのスレッドによって作成されたローカル変数は、他のすべてのスレッドには表示されません。 2 つのスレッドがまったく同じコードを実行している場合でも、両方のスレッドは独自のローカル変数を作成します。したがって、各スレッドには独自のバージョンのローカル変数があります。
基本型 (boolean、byte、short、char、int、long、float、double) のすべてのローカル変数はスレッド スタックに完全に格納されるため、他のスレッドからは見えません。スレッドはプリミティブ型変数のコピーを別のスレッドに渡すことはできますが、プリミティブ型のローカル変数を共有することはできません。
このヒープには、オブジェクトを作成したスレッドに関係なく、アプリケーションで作成されたすべてのオブジェクトが含まれます。これには、基本型 (Byte、Integer、Long など) のオブジェクト バージョンが含まれます。オブジェクトが作成されてローカル変数に割り当てられるか、別のオブジェクトのメンバー変数が作成されるかに関係なく、オブジェクトは引き続きヒープに格納されます。
これは、スレッド スタックに格納されているコール スタックとローカル変数、およびヒープに格納されているオブジェクトを示す図です:
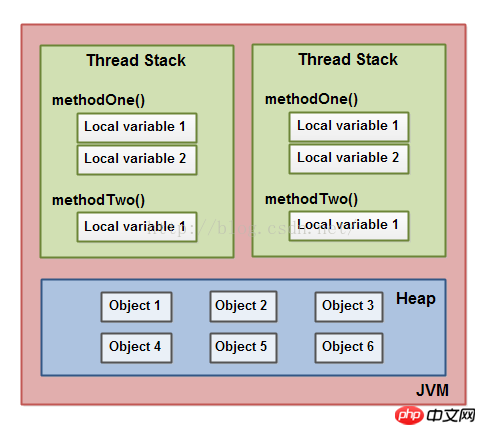
ローカル変数はプリミティブ型である場合があり、その場合は完全に保存されます。スレッドスタック。
ローカル変数はオブジェクト参照である場合があります。このシナリオでは、参照 (ローカル変数) はスレッド スタックに格納されますが、オブジェクト自体はヒープに格納されます。
オブジェクトにはメソッドが含まれる場合があり、これらのメソッドにはローカル変数が含まれます。これらのローカル変数は、このメソッドが属するオブジェクトがヒープに格納されている場合でも、スレッド スタックにも格納されます。
オブジェクトのメンバー変数は、オブジェクト自体とともにヒープに保存されます。このメンバー変数が基本型である場合だけでなく、オブジェクトへの参照である場合も同様です。
静的クラス変数もヒープに格納されます。
ヒープ内のオブジェクトには、このオブジェクトへの参照を持つすべてのスレッドからアクセスできます。スレッドがオブジェクトにアクセスするとき、オブジェクトのメンバー変数にもアクセスできます。 2 つのスレッドが同じオブジェクトのメソッドを同時に呼び出すと、それらは同時にオブジェクトのメンバー変数にアクセスしますが、各スレッドはローカル変数の独自のコピーを持つことになります。
これは上記の説明に基づいた図です:
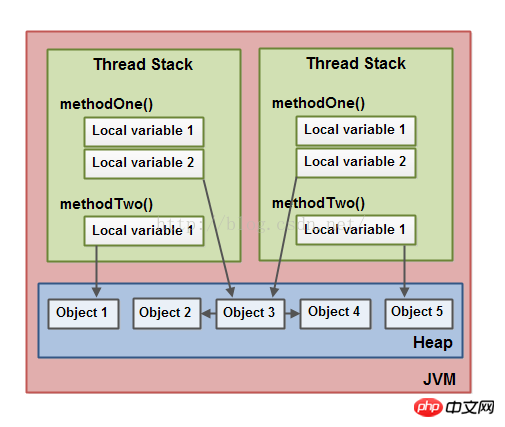
2 つのスレッドにはローカル変数のセットがあります。ローカル変数の 1 つ (ロケール変数 2) は、ヒープ内の共通オブジェクト (オブジェクト 3) を指します。 2 つのスレッドはそれぞれ、同じオブジェクトへの異なる参照を持っています。これらが参照するローカル変数はスレッド スタックに格納されますが、これら 2 つの異なる参照が指す同じオブジェクトはヒープ内にあります。
この共有オブジェクト (オブジェクト 3) がオブジェクト 2 とオブジェクト 4 をメンバー変数としてどのように参照しているかに注目してください (図の矢印で示されています)。 Object3 内のこれらの変数の参照を通じて、両方のスレッドはオブジェクト 2 とオブジェクト 4 にもアクセスできます。
この図には、ヒープ内の 2 つの異なるオブジェクトを指すローカル変数も示されています。このシナリオでは、この参照は、同じオブジェクトではなく、2 つの異なるオブジェクト (オブジェクト 1 とオブジェクト 5) を指します。理論的には、両方のスレッドにこれら 2 つのオブジェクトへの参照がある場合、2 つのオブジェクトはオブジェクト 1 とオブジェクト 5 の両方にアクセスできます。ただし、図では、各スレッドはこれら 2 つのオブジェクトへの参照のみを持っています。
それでは、どのようなコードが上の図のメモリ構造を持つでしょうか?そうですね、簡単に言うと次のコードのようなものです:
public class MyRunnable implements Runnable() {
public void run() {
methodOne();
}
public void methodOne() {
int localVariable1 = 45;
MySharedObject localVariable2 =
MySharedObject.sharedInstance;
//... do more with local variables.
methodTwo();
}
public void methodTwo() {
Integer localVariable1 = new Integer(99);
//... do more with local variable.
}
}public class MySharedObject {
//static variable pointing to instance of MySharedObject
public static final MySharedObject sharedInstance =
new MySharedObject();
//member variables pointing to two objects on the heap
public Integer object2 = new Integer(22);
public Integer object4 = new Integer(44);
public long member1 = 12345;
public long member1 = 67890;
}2 つのスレッドがこの run メソッドを実行している場合、このアイコンには結果が先に表示されます。 run メソッドは、methodOne メソッドを呼び出し、methodOne メソッドは、methodTwo メソッドを呼び出します。
methodOneメソッドは、基本型(int型)のローカル変数と、オブジェクトから参照されるローカル変数を宣言します。
各スレッドがmethodOneメソッドを実行すると、それぞれのスレッドスタックにlocalVariable1とlocalVariable2の独自のコピーが作成されます。この localVariable1 は互いに完全に分離され、それぞれのスレッド スタック内でのみ存続します。あるスレッドは、別のスレッドによって localVariable1 に加えられた変更を認識できません。
methodOne メソッドを実行する各スレッドは、localVariable2 の独自のコピーも作成します。ただし、localVariable2 のこれら 2 つの異なるコピーは、ヒープ内の同じオブジェクトを指します。このコードは、静的変数を介してオブジェクトへの参照を指すように localVariable2 を設定します。静的変数のコピーは 1 つだけあり、このコピーはヒープ内にあります。したがって、localVariable2 内の両方のコピーは同じインスタンスを指すことになります。この MySharedObject もヒープに格納されます。上の図のオブジェクト 3 に相当します。
この MySharedObject クラスには 2 つのメンバー変数も含まれることに注意してください。メンバー変数自体はオブジェクトとともにヒープに格納されます。これら 2 つのメンバー変数は、他の 2 つの Integer オブジェクトを指します。これらの Integer オブジェクトは、上の図のオブジェクト 2 とオブジェクト 4 に相当します。
また、methodTwo メソッドが localVariable1 のローカル変数を作成する方法にも注目してください。このローカル変数は、Integer オブジェクトへの参照です。このメソッドは、新しい Integer インスタンスを指すように localVariable1 参照を設定します。この localVariable1 参照は、実行中の MethodTwo メソッドの各スレッドのコピーに保存されます。インスタンス化された 2 つの Integer オブジェクトはヒープに格納されますが、このメソッドが実行されるたびに新しい Integer オブジェクトが作成され、このメソッドを実行する 2 つのスレッドは別々の Integer インスタンスを作成します。 MethodTwo メソッド内で作成される Integer オブジェクトは、上図のオブジェクト 1 とオブジェクト 5 に相当します。
MySharedObject クラスの long 型の 2 つのメンバー変数は基本型であることにも注意してください。これらの変数はメンバー変数であるため、オブジェクトとともにヒープに格納されます。ローカル変数のみがスレッド スタックに保存されます。
ハードウェア メモリ アーキテクチャ
現在のハードウェア メモリ アーキテクチャは、内部 Java メモリ モデルとは若干異なります。ハードウェア メモリ アーキテクチャを理解することも重要であり、Java メモリ モデルがどのように機能するかを理解するのに役立ちます。このセクションでは、一般的なハードウェア メモリ フレームワークについて説明し、次のセクションでは、Java メモリ モデルがそれとどのように連携するかを説明します。
これは、現代のコンピューターのハードウェア構造の簡略図です:
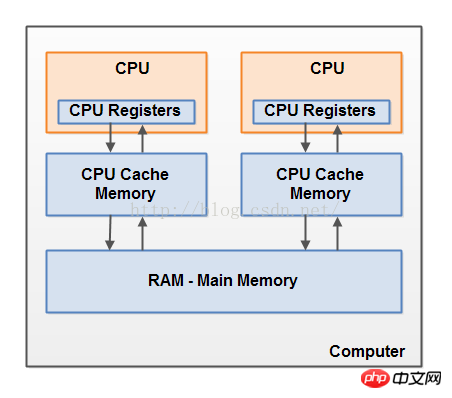
現代のコンピューターには、多くの場合、2 つ以上の CPU が搭載されています。これらの CPU の中には複数のコアを備えているものもあります。重要な点は、2 つ以上の CPU を搭載したコンピュータでは複数のスレッドが同時に実行される可能性があるということです。各 CPU はいつでも 1 つのスレッドを実行できます。Java アプリケーションでは、各 CPU で 1 つのスレッドを同時に実行できます。
各 CPU には一連のレジスタが含まれており、これらは本質的に CPU メモリです。この CPU は、メイン メモリよりもレジスタ上で高速に実行されます。これは、CPU がメイン メモリにアクセスするよりも高速にレジスタにアクセスするためです。
各 CPU には、CPU キャッシュ用のメモリ層がある場合もあります。実際、最新の CPU のほとんどには、ある程度のサイズのキャッシュ メモリ層があります。この CPU は、メイン メモリよりもはるかに高速にキャッシュ メモリ層にアクセスしますが、内部レジスタへのアクセスほど高速ではありません。その結果、この CPU キャッシュメモリのアクセス速度は内部レジスタとメインメモリの間になります。一部の CPU には複数のレベルのキャッシュ (レベル 1 とレベル 2) がある場合がありますが、Java メモリ モデルとメモリの相互作用を理解するためにこれを知っておくことは重要ではありません。 CPU にはキャッシュ メモリ層がある可能性があることを知っておくことが重要です。
コンピュータにはメインメモリ領域(RAM)も含まれています。すべての CPU はこのメイン メモリにアクセスできます。このメイン メモリは通常、CPU のキャッシュ メモリよりも大きくなります。
通常、CPU はメインメモリにアクセスする必要がある場合、メインメモリ部分を CPU キャッシュに読み取ります。キャッシュの一部をレジスタに読み取り、そこで操作を実行することもあります。 CPU が結果をメイン メモリに書き戻す必要がある場合、値を内部レジスタからキャッシュ メモリにフラッシュし、ある時点でその値をメイン メモリにフラッシュします。
キャッシュ メモリに保存されているこれらの値は、CPU が何か他のものをメイン メモリに保存する必要があるときに、メイン メモリにフラッシュされます。この CPU キャッシュは、メモリの一部に書き込まれる場合もあれば、メモリの一部がフラッシュされる場合もあります。毎回キャッシュ全体を読み書きする必要はありません。通常、このキャッシュは「キャッシュ ライン」と呼ばれる小さなメモリ ブロックで更新されます。 1 つまたは複数のキャッシュ ラインをキャッシュ メモリに読み込むことができ、1 つまたは複数のキャッシュ ラインを再びメイン メモリにフラッシュすることができます。
Java メモリ モデルとハードウェア メモリ構造の間のギャップを埋める
すでに述べたように、Java メモリ モデルとハードウェア メモリ構造は異なります。このハードウェア メモリ構造では、スレッド スタックとヒープが区別されません。ハードウェアでは、スレッド スタックとヒープの両方がメイン メモリに配置されます。次の図に示すように、スレッド スタックとヒープの一部が CPU キャッシュと内部 CPU レジスタに表示されることがあります:
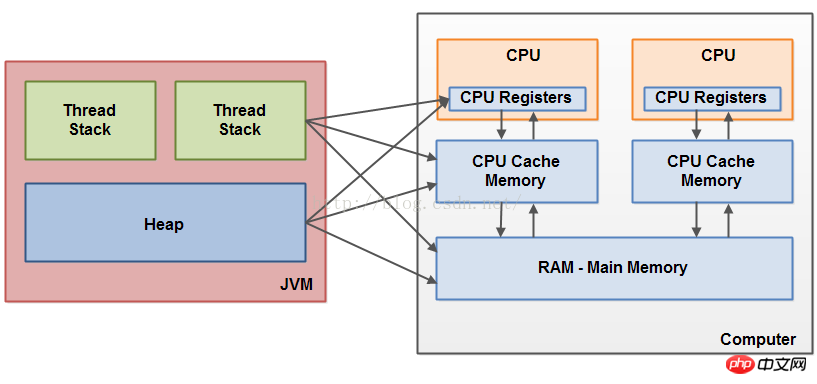
オブジェクトと変数がコンピュータのさまざまなメモリ領域に格納される場合、特定の問題が発生する可能性があります。起こる。 2 つの主な問題は次のとおりです:
共有変数の更新に対するスレッドの可視性
共有変数の読み取り、確認、書き込み時の競合状態
これらの問題については、以下の部分で説明します。
共有オブジェクトの可視性
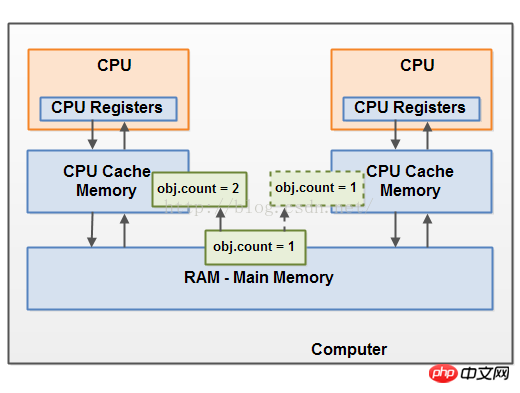
競合状態
2 つ以上のスレッドがオブジェクトを共有し、複数のスレッドが共有オブジェクト内の変数を更新する場合、競合状態が発生する可能性があります。 スレッド A が共有オブジェクトの count 変数を CPU キャッシュに読み取る場合を想像してください。一方、スレッド B も同じことを行いますが、別の CPU キャッシュに入ります。ここで、スレッドは count を 1 つインクリメントし、スレッド B は同じことを行います。ここで、変数は 2 回インクリメントされます。 これらのインクリメントが連続して実行される場合、count 変数は 2 回インクリメントされ、元の値に 2 が加算されてメイン メモリに書き込まれます。 その後、これら 2 つの増分は適切に同期されず、同時実行が発生します。スレッド A とスレッド B のどちらが更新をメイン メモリに書き込むかに関係なく、この更新の値は 1 だけ増加し、2 増加することはありません。 この図は、上で説明した競合状態の問題を示しています: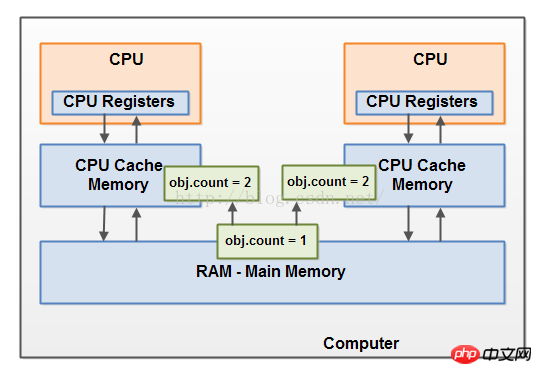

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7849
7849
 15
1649
14
1403
52
1300
25
1241
29
15
1649
14
1403
52
1300
25
1241
29

 Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8は、Stream APIを導入し、データ収集を処理する強力で表現力のある方法を提供します。ただし、ストリームを使用する際の一般的な質問は次のとおりです。 従来のループにより、早期の中断やリターンが可能になりますが、StreamのForeachメソッドはこの方法を直接サポートしていません。この記事では、理由を説明し、ストリーム処理システムに早期終了を実装するための代替方法を調査します。 さらに読み取り:JavaストリームAPIの改善 ストリームを理解してください Foreachメソッドは、ストリーム内の各要素で1つの操作を実行する端末操作です。その設計意図はです
 PHP:Web開発の重要な言語
Apr 13, 2025 am 12:08 AM
PHP:Web開発の重要な言語
Apr 13, 2025 am 12:08 AM
PHPは、サーバー側で広く使用されているスクリプト言語で、特にWeb開発に適しています。 1.PHPは、HTMLを埋め込み、HTTP要求と応答を処理し、さまざまなデータベースをサポートできます。 2.PHPは、ダイナミックWebコンテンツ、プロセスフォームデータ、アクセスデータベースなどを生成するために使用され、強力なコミュニティサポートとオープンソースリソースを備えています。 3。PHPは解釈された言語であり、実行プロセスには語彙分析、文法分析、編集、実行が含まれます。 4.PHPは、ユーザー登録システムなどの高度なアプリケーションについてMySQLと組み合わせることができます。 5。PHPをデバッグするときは、error_reporting()やvar_dump()などの関数を使用できます。 6. PHPコードを最適化して、キャッシュメカニズムを使用し、データベースクエリを最適化し、組み込み関数を使用します。 7
 PHP対Python:違いを理解します
Apr 11, 2025 am 12:15 AM
PHP対Python:違いを理解します
Apr 11, 2025 am 12:15 AM
PHP and Python each have their own advantages, and the choice should be based on project requirements. 1.PHPは、シンプルな構文と高い実行効率を備えたWeb開発に適しています。 2。Pythonは、簡潔な構文とリッチライブラリを備えたデータサイエンスと機械学習に適しています。
 PHP対その他の言語:比較
Apr 13, 2025 am 12:19 AM
PHP対その他の言語:比較
Apr 13, 2025 am 12:19 AM
PHPは、特に迅速な開発や動的なコンテンツの処理に適していますが、データサイエンスとエンタープライズレベルのアプリケーションには良くありません。 Pythonと比較して、PHPはWeb開発においてより多くの利点がありますが、データサイエンスの分野ではPythonほど良くありません。 Javaと比較して、PHPはエンタープライズレベルのアプリケーションでより悪化しますが、Web開発により柔軟性があります。 JavaScriptと比較して、PHPはバックエンド開発により簡潔ですが、フロントエンド開発のJavaScriptほど良くありません。
 カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルは3次元の幾何学的図形で、両端にシリンダーと半球で構成されています。カプセルの体積は、シリンダーの体積と両端に半球の体積を追加することで計算できます。このチュートリアルでは、さまざまな方法を使用して、Javaの特定のカプセルの体積を計算する方法について説明します。 カプセルボリュームフォーミュラ カプセルボリュームの式は次のとおりです。 カプセル体積=円筒形の体積2つの半球体積 で、 R:半球の半径。 H:シリンダーの高さ(半球を除く)。 例1 入力 RADIUS = 5ユニット 高さ= 10単位 出力 ボリューム= 1570.8立方ユニット 説明する 式を使用してボリュームを計算します。 ボリューム=π×R2×H(4
 PHP対Python:コア機能と機能
Apr 13, 2025 am 12:16 AM
PHP対Python:コア機能と機能
Apr 13, 2025 am 12:16 AM
PHPとPythonにはそれぞれ独自の利点があり、さまざまなシナリオに適しています。 1.PHPはWeb開発に適しており、組み込みのWebサーバーとRich Functionライブラリを提供します。 2。Pythonは、簡潔な構文と強力な標準ライブラリを備えたデータサイエンスと機械学習に適しています。選択するときは、プロジェクトの要件に基づいて決定する必要があります。
 未来を創る: まったくの初心者のための Java プログラミング
Oct 13, 2024 pm 01:32 PM
未来を創る: まったくの初心者のための Java プログラミング
Oct 13, 2024 pm 01:32 PM
Java は、初心者と経験豊富な開発者の両方が学習できる人気のあるプログラミング言語です。このチュートリアルは基本的な概念から始まり、高度なトピックに進みます。 Java Development Kit をインストールしたら、簡単な「Hello, World!」プログラムを作成してプログラミングを練習できます。コードを理解したら、コマンド プロンプトを使用してプログラムをコンパイルして実行すると、コンソールに「Hello, World!」と出力されます。 Java の学習はプログラミングの旅の始まりであり、習熟が深まるにつれて、より複雑なアプリケーションを作成できるようになります。
 PHP:多くのウェブサイトの基礎
Apr 13, 2025 am 12:07 AM
PHP:多くのウェブサイトの基礎
Apr 13, 2025 am 12:07 AM
PHPが多くのWebサイトよりも優先テクノロジースタックである理由には、その使いやすさ、強力なコミュニティサポート、広範な使用が含まれます。 1)初心者に適した学習と使用が簡単です。 2)巨大な開発者コミュニティと豊富なリソースを持っています。 3)WordPress、Drupal、その他のプラットフォームで広く使用されています。 4)Webサーバーとしっかりと統合して、開発の展開を簡素化します。
