

最適化の概念は、開発プロジェクトのプロセスで常に言及されます。この記事は、Mysql データ最適化の実践の探求の旅であり、その理由、方法、パーティション テーブルの管理方法、およびパーティショニングの簡単な実践を簡単に紹介します。
ビッグデータの操作中、データテーブルは分割および征服され、大量のデータを含むテーブルは小さな操作単位に分割され、各操作単位には個別の名前が付けられます。同時に、プログラム開発者にとって、パーティショニングはパーティショニングなしと同じです。一般的に、mysql パーティショニングはプログラム アプリケーションに対して透過的であり、データベースによるデータの再配置にすぎません。
パーティションの機能:
(1) パフォーマンスを向上させます。
パーティショニングの最終的な目標は、パフォーマンスを向上させることです。パーティショニングが完了すると、mysql は各パーティションに特定のデータ ファイルとインデックス ファイルを生成し、取得中に特定の部分データを取得します。これにより、データベースの実行と保守が向上します。これは、パーティション化されたテーブルが異なる物理ドライブに割り当てられ、複数のパーティションに同時にアクセスする際のパーティションの物理 I/O 競合が軽減されるためです。
(2) 管理が簡単です。
パーティション分割後、管理データは対応するパーティションを直接管理できます。データが数百万に達する場合、データ テーブルを操作するよりもパーティションを直接操作する方がはるかに直接的です。
(3) 耐障害性
パーティションが完成した後、1 つのパーティションが破壊されても、他のデータは影響を受けません。
mysqlの分割方法には、RANGE分割、LIST分割、HASH分割、KEY分割があります。
RANGEパーティショニング: テーブルを直接作成する際に、特定のフィールドの値に基づいてパーティション管理が行われます。例:
create table emp (empno varchar(20) not null , empname varchar(20), deptno int, birthdate date, salary int ) partition by range(salary) ( partition p1 values less than (1000), partition p2 values less than (2000), partition p3 values less than maxvalue );
LIST パーティション: RANG パーティションと似ていますが、違いは、リスト パーティションがハッシュ値であるのに対し、RANG パーティションは特定のフィールド範囲に従ってパーティション化されることです。例:
create table emp (empno varchar(20) not null , empname varchar(20), deptno int, birthdate date not null, salary int ) partition by list(deptno) ( partition p1 values in (10,15), partition p2 values in (20,25), partition p3 values in (30,35) );
HASH パーティショニング: データが事前に指定された参考文献のパーティションに均等に分散されていることを確認し、パーティショニング時に列の値とパーティションの数が指定されていることを確認します。例:
create table emp (empno varchar(20) not null , empname varchar(20), deptno int, birthdate date not null, salary int ) partition by hash(year(birthdate)) partitions 4;
KEY パーティション: HASH パーティションと同様ですが、1 つ以上のカラムの計算のみをサポートする KEY パーティションとは異なり、MySQL サーバーは独自のハッシュ関数を提供し、1 つ以上のカラムには整数値が含まれている必要があります。 。例:
create table emp (empno varchar(20) not null , empname varchar(20), deptno int, birthdate date not null, salary int ) partition by key(birthdate) partitions 4;
パーティションの削除:
altertable emp drop Partition p 1;
ハッシュまたはキーパーティションを削除できません。
複数のパーティションを一度に削除、alter tableemp droppartition p1,p2;
パーティションを追加:
alter table emp add パーティション (パーティション p3 values が (4000) 未満);
alter table empl add パーティション (パーティション p3 values in (40));
パーティション分割の再編成:
Reorganizepartition キーワードは、パートまたはデータではなくすべてのテーブルが変更されました失うだろう。パーティションの全体的なスコープは、分解の前後で一貫している必要があります。 ( 100
)、パーティションp3 値が (
1000)
)未満です ----
データ損失なし
パーティション:のマージパーティション: 2 つのパーティションを 1 つに結合します。 alter
tableteパーティションp1、p3をに
(パーティションp1の値
が(1000)より小さい) ;
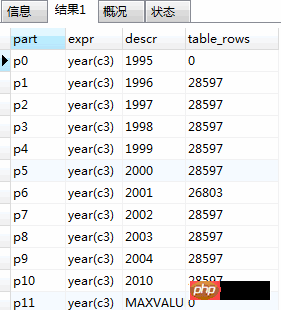
----データ損失なし ハッシュパーティションテーブルを再定義: Altertableempパーティションby ハッシュ(給与)パーティション 7; ----データ損失なし レンジパーティションテーブルを再定義します: Altertable emp パーティションby range(給与) ( パーティションp1の値が(2000)未満、 パーティションp2の値が(4000より小さい) ) ) ; ----データ損失なし テーブルのすべてのパーティションを削除します: Alter table emp deletepartイオン化;- -データ損失なし パーティションを再構築: これは、最初にパーティションに保存されているすべてのレコードを削除してから再挿入するのと同じ効果があります。パーティションのデフラグに使用できます。 ALTERTABLEemp再構築パーティションp1,p2; パーティションの数が多い場合削除OK、またはVariableのあるもの-length 行 (つまり、VARCHAR、BLOB、または TEXT タイプの列) には多くの変更が加えられており、「ALTER TABLE ... OPTIMIZE PARTITION」を使用して、未使用の領域を再利用し、パーティション データ ファイルを整理できます。 ALTER emp optimize パーティション p1,p2; パーティションのキー配布を読み取り、保存します。 ALTER TABLEemp analyze ; 破損したパーティションを修復します。 ALTER TABLEemprepairpartition p1,p2; パーティションを確認してください: ほとんどのNANDを使用できますパーティションテーブルは以下と同じ方法でチェックされます。テーブルパーティションを確認してください。 TABLE emp パーティション p1,p2; 这个命令可以告诉你表emp的分区p1,p2中的数据或索引是否已经被破坏。如果发生了这种情况,使用“ALTER TABLE ... REPAIR PARTITION”来修补该分区。 1. 创建分区表和不分区表: 2. 创建大数据操作环境。为了测试结果的准确度提高,需要表中存在大数据,通过以下事务可在数据表中创建800万条数据: 执行事务:call load_part_tab(); ,因为执行此事务执行的时间很长,我只在表中插入了283304条数据。 创建完成一张表后,可以将该表的数据复制到未分区表,这样执行速度会很快: 3. 查看分区表分区结构: 执行结果: 3. 测试速度: 执行分区表查询语句: 执行时间: 执行未分区表查询语句: 执行时间: 从时间对比可以看出,同样的查询语句,分区表执行速度在20ms左右,未分区表在175ms左右,执行速度相差8倍左右,因此得出结论:分区表的执行速度要比未分区表执行速度快。
1. MySQL分区处理NULL值的方式 如果分区键所在列没有notnull约束。 如果是range分区表,那么null行将被保存在范围最小的分区。 如果是list分区表,那么null行将被保存到list为0的分区。 在按HASH和KEY分区的情况下,任何产生NULL值的表达式mysql都视同它的返回值为0。 为了避免这种情况的产生,建议分区键设置成NOT NULL。 2. パーティション キーは INT 型であるか、式を通じて INT 型を返す必要があります。NULL を指定することもできます。唯一の例外は、パーティション タイプが KEY パーティションの場合であり、他のタイプの列をパーティション キーとして使用できます (BLOB 列または TEXT 列を除く)。 3. パーティション テーブルのパーティション キーにインデックスを作成すると、このインデックスもパーティション化されます。 パーティション キーのグローバル インデックスはありません。 4. サブパーティション化できるのは RANG パーティションと LIST パーティションのみです。HASH パーティションと KEY パーティションはサブパーティション化できません。 5. 一時テーブルはパーティション化できません。 上記は、Mysql 最適化実験 (1) - パーティションの内容です。その他の関連コンテンツについては、PHP 中国語 Web サイト (www.php.cn) に注目してください。 【分区实践】
-- 创建分区表
CREATE TABLE part_tab
(c1 int NULL, c2 VARCHAR(30), c3 date not null)
PARTITION BY RANGE(year(c3))
(PARTITION p0 VALUES LESS THAN (1995),
PARTITION p1 VALUES LESS THAN (1996) ,
PARTITION p2 VALUES LESS THAN (1997) ,
PARTITION p3 VALUES LESS THAN (1998) ,
PARTITION p4 VALUES LESS THAN (1999) ,
PARTITION p5 VALUES LESS THAN (2000) ,
PARTITION p6 VALUES LESS THAN (2001) ,
PARTITION p7 VALUES LESS THAN (2002) ,
PARTITION p8 VALUES LESS THAN (2003) ,
PARTITION p9 VALUES LESS THAN (2004) ,
PARTITION p10 VALUES LESS THAN (2010),
PARTITION p11 VALUES LESS THAN (MAXVALUE) );
-- 创建没有分区表
CREATE TABLE nopart_tab
(c1 int NULL, c2 VARCHAR(30), c3 date not null)
-- 创建生成数据事物
CREATE PROCEDURE load_part_tab()
begin
declare v int default 0;
while v < 8000000
do
insert into part_tab
values (v,'testingpartitions',adddate('1995-01-01',(rand(v)*36520)mod 3652));
set v = v + 1;
end while;
end;insert into test.nopart_tab select * from test.part_tab
-- 查询分区情况
select
partition_name part,
partition_expression expr,
partition_description descr,
table_rows
from information_schema.partitions where
table_schema = schema()
and table_name='part_tab';
select count(*) from part_tab where c3 > date '1995-01-01'and c3 < date '1995-12-31';

select count(*) from nopart_tab where c3 > date '1995-01-01'and c3 < date '1995-12-31';

【分区局限性】
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



