

前の記事では、B-TREEのいくつかの構造と保存方法を簡単に紹介しましたが、インデックスとデータの関係はまだ結びついていないように感じます
そこで、この記事では実際のデータ行を使用します。 、インデックスを作成した後、B+TREE でソートされる順序は何ですか。
1. オリジナルデータの作成をシミュレートします
下の図では、左側が便宜のためのシミュレートされたデータです。エンジンはmysiamです〜
右側は通常のシミュレーションデータテーブルをEXCELでランダムに並べ、主キーを1~27に従って並べたものです(ランダムでない場合は、順番に書きます)データをシミュレートし、さらにインデックスのソートのプロセスはインデックスでは明確に見ることができません)
つまり、の右側のデータがテストしたい元のデータです。インデックスが作成される前にこのように、後続のデータはすべて並べ替えられます。これは、インデックスの生成後の並べ替えの効果をよりよく確認できるように、標準に従って行われます。
テーブルには 4 つのフィールド (id、a、b、c) があり、合計 27 行のデータがあります

2.インデックスの作成a
以下に示すように、インデックス a を作成した後、インデックス構造は主キー ID に応じた元の並べ替えから新しいルールに変更されます。インデックスは実際にはデータ構造であると言えます。次に、新しい構造を作成するインデックス a を作成し、フィールド a の規則に従って並べ替えます。主キー ID で表される最初のデータ行は 1、2 番目のデータ行は ID=3 で表され、3 番目のデータ行はID=5 のデータ行で表されます。 。 。
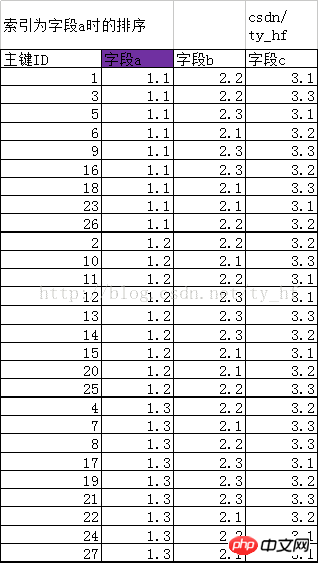
新しいソート主キーID (IDはデータの行を表します): 1 3 5 6 9 16 18 23 26 2 10 11 12 13 14 15 20 25 4 7 8 17 1 9 21 22 24 27
フィールドaが同じ場合、配列前後で主キーIDでソートされることは難しくありませんが、例えばa=1.1の値も同じになります。それらの並べ替えでは、ID 値は 1、3、5、6 になります。 。対応する行は主キー ID と同様の順序でソートされます。 (つまり、同じ値で小さいIDが前になるソート)
3. 以下に示すようにインデックス(a, b)を作成します
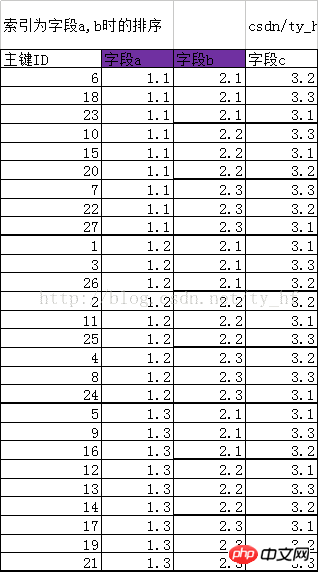
結合インデックスを作成する場合 (a, b) 以降、インデックス構造では、元の主キー ID に基づくソートが新しいルールになります。ソート ルールは、最初にフィールド a に基づいてソートされ、次にフィールド b に基づいてソートされます。に。つまり、インデックス a に基づいて、フィールド b もソートされます。
新しいソート主キーID (IDはデータ行を表します): 6 18 23 10 15 20 7 22 27 1 3 26 2 11 25 4 8 24 5 9 16 12 13 14 17 19 21
フィールド a と b の値が同じ場合、それらの配置も同じであることを見つけるのは難しくありません。たとえば、同じ行 (18,6,23) は a=1.1,b=2.1 ですが、その順序は 6,18,23 になります。
フィールド (a,b) インデックス、最初にインデックスによって並べ替え、次に a に基づいて b によって並べ替えます
6 18 23 10 15 20 7 22 27 1 3 26 2 11 25 4 8 24 5 9 16 12 13 14 17 19 21
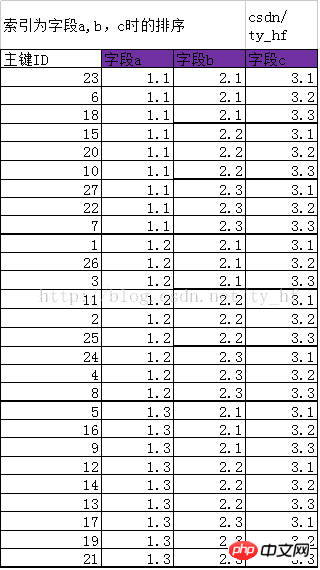
IV. インデックス (a,b,c) を作成します
まず a,b を押します。インデックスで並べ替え、(a, b) に基づいて c で並べ替えます
新しい並べ替え主キー ID (ID はデータの行を表します): 23 6 18 15 20 10 27 22 7 1 26 3 11 2 25 24 4 8 5 16 9 12 14 13 17 19 21
5.
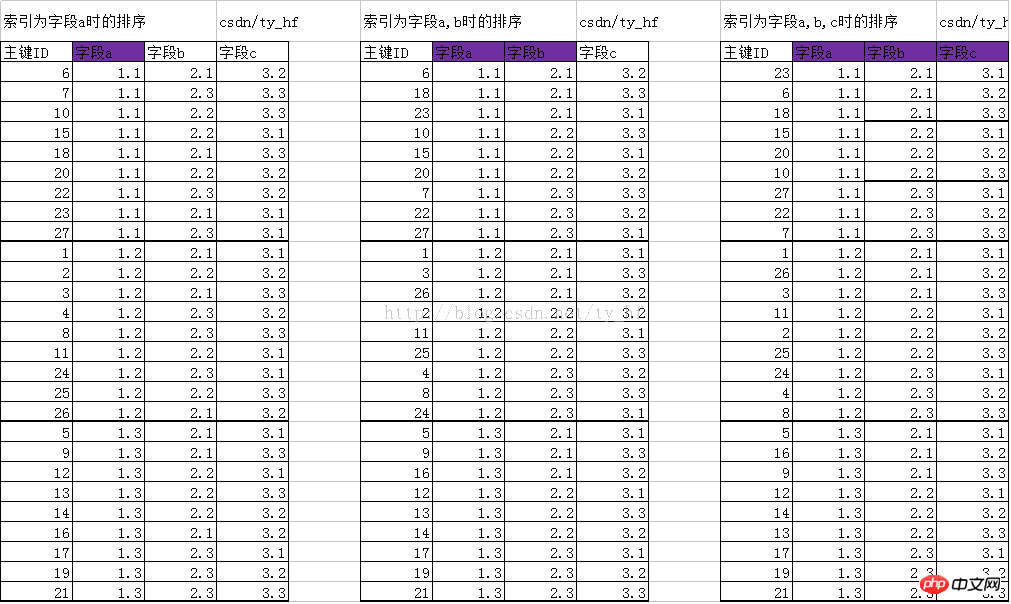

は、前回の記事
と同じです。B-TREEツリーの最後の行のリーフノードは、この順序で左から右に配置されます。 。この順序で検索すると、インデックス(部屋登録テーブル)があれば、データを読み込む処理(部屋を探す処理に相当)がわかるので、まずデータを読み込む必要があります。インデックスの構造 (サイズが小さく読み取りが速いため)、その構造のリーフ ノードで実際の物理ディスクの格納場所を見つけて (ハウス番号を見つけるのと同じ)、ハウス番号をディスクに直接取得します。データの取得。これはデータを読み取るプロセスです。インデックスがない場合は、部屋から部屋へと検索するだけで目的地がわかりません。
インデックスがない場合、主キーIDは実際にはそのインデックスであり、主キーIDの規則に従って小さいものから大きいものまで配置されます。
インデックスがある場合は、インデックスa、結合インデックス(a) 、 b)、ジョイント インデックス (a、b、c) 対応する 3 つの B+TREE 構造、リーフ ノードの端が指す物理ディスクは異なります。
結論:
1. インデックスが作成されていない場合は、ID の主キーに従って昇順に配置されます
2. インデックス a が作成されると、新しい構造インデックス (B+TREE) が生成されます。便利で高速な検索の構造ルール
3. インデックス a、インデックス ab、インデックス abc を作成するとき、これら 3 つの対応するデータの順序は異なります
4. インデックス abc はインデックスを考慮します。 ab とインデックス a があるので、前者は後者 2 つに対して確立する必要はありません
5. インデックスが確立されると、デフォルトではインデックスのない列は ID の増加順にソートされます
上記はMysql-index ソート行の詳細な説明、その他の関連コンテンツ PHP 中国語 Web サイト (www.php.cn) にご注意ください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



