

course版を転載するときにソースを示してください。ソースを示してください:ニュースアプリバックエンドシステムアーキテクチャの成長パス - 高可用性アーキテクチャの設計
しかし、ビジネス開発とバージョンの反復を止めることはできません。私は、元のコンテンツ ビジネス開発から 2 人のクラスメートを異動して、古い API の開発をサポートし続けることしかできませんでした。同時に、新しいインターフェイス アーキテクチャの設計を検討し始めました。 アプリ開発の経験不足と限られたスキルのため、私はインターフェースの再構築にブランクを見つけ始め、2週間連続で夜更かしして数セットのフレームワークを作成し、日中クラスメートと議論しました。それを一つ一つひっくり返した。 仕方なく、さまざまな情報を調べ、主要なインターネット アプリケーションの経験から学び、同時に有名な先生を訪問しました。 [Thanks to: @青哥、@雪大夫、@京京、@强哥 @太哥APP 側と WAP 側の友人たちに指導を受け、多くの学習を通じて、新しいインターフェイス アーキテクチャ構築のアイデア全体の全体的な計画をゆっくりと作成し、日の目を見たような気がします。 1 週間昼も夜も働き続けた結果、全体的なフレーム構造が完成しました。私は休むことなく働き続けているので、友達を率いて作業を始めましょう。
全体的な設計については大体のアイデアはありましたが、インターフェースの再構築にも大きな問題があり、これを進めるにはAPP、製品、統計の学生の全面的なサポートが必要です。
新しいインターフェイスは、呼び出しメソッドとデータ出力構造の点で古いインターフェイスとは完全に異なり、APP コードに多くの変更を加える必要があります [@Huihui @明明のご支援とご協力に感謝します]
もちろん、統計も同じ問題に直面しています。つまり、すべての元の統計ルールを変更する必要があります。同時に、[@婵女@統計部門 @製品のクラスメート]にも感謝します。彼らの強力な協力に感謝します。両端、製品、統計の支援がなければ、インターフェースの再構築作業を進めることは不可能であると同時に、再構築作業が予定通りに進むよう強力な支援をしていただいたすべての指導者に感謝したいと思います。
新しいインターフェースは主に次の側面から設計されています:
1.
1>、インターフェイス リクエストに署名検証を追加し、インターフェイス暗号化リクエスト メカニズムを確立し、リクエスト アドレスごとに一意の ID を生成し、サーバーとクライアントで双方向暗号化を使用して、悪意のあるインターフェイス ブラッシングを効果的に回避します。 2>、すべてのビジネスパラメータの登録システム、統合セキュリティ管理2、拡張性
高い凝集性と低い結合性、強制的なバージョン分離、APP バージョンのフラットな開発により、コードの再利用性が向上し、小規模バージョンは継承システムに従います。3、リソース管理
サービス登録システム、統合された入口と出口、持続可能な開発を確保するには、すべてのインターフェースをシステムに登録する必要があります。その後の監視とダウングレードのスケジュールを保証します。 4. 統合されたキャッシュのスケジュールと割り当てシステムAPP には PUSH 機能があり、PUSH が発行されるたびに、多数のユーザーが即座に呼び出され、APP にアクセスします。 新しいインターフェースが PUSH を送信するたびに、サーバーがハングアップするという悲劇的な事態が発生します。
障害パフォーマンス:
1. php-fpm はブロックされており、サーバーの全体的なステータスは正常です 2. nginx はダウンしておらず、サービスは正常です。 3. php-fpm を再起動します。サービスはしばらくの間は正常に動作しますが、数秒後に再び停止します。 4. インターフェースの応答が遅いかタイムアウトになり、アプリがコンテンツなしで更新されますトラブルシューティングの推測
最初、私は次の質問を疑いました 1. MCに問題があります 2. MYSQL が遅い 3. 大量のリクエスト 4. 一部のリクエストはプロキシの古いインターフェイスであるため、リクエストが 2 倍になります 5. ネットワークの問題 6. 一部の依存インターフェイスは遅く、サービスを停止させます しかし、ログ記録が不足しているため、根拠は見つかりませんでした。問題追跡:
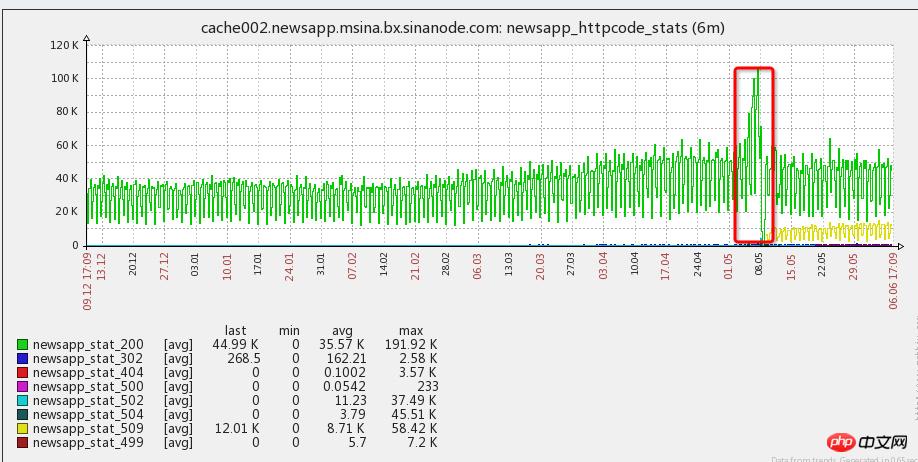
プッシュ送信するとサーバーの負荷が一瞬で上がり、短時間でPHP-FPMがブロックされてハングアップしてしまいます
PHPが順次実行されます。 1 つのバックエンド インターフェイスが遅い限り、同時実行性が高い条件下ではインライン待機が発生し、PHP が完全に停止するまでスループットが急激に低下します。
1. プッシュ時、同時にクライアントを開いた場合、その数は通常の 3 ~ 5 倍になります (朝と夕方のピークが発生します)。重ね合わせ))
2. クライアントが PUSH を開くと、ユーザーを呼び出すためのコールド スタートが行われます。多くのインターフェイス リソースがあり、新しい API がアプリ側で完全に通信されていませんでした。が起動された結果、キャッシュできないリアルタイムの興味や広告などを含む膨大な数のインターフェイス リクエストが瞬時に発生し、大量のストリーキング バックエンド インターフェイス、さらには MYSQL や他のリソースを使用すると、大量の待機が発生します。
3. インターフェイス リクエストのバックエンド リソースのタイムアウトが長すぎるため、遅いインターフェイス リクエストが時間内に解放されず、多数のインターフェイス リクエストがキューで待機することになります。
4.作業の焦点はコードの再構築にありましたが、サーバーのリソースが無視されており、新しいマシンが存在しなかったことが、この失敗の原因でもあります。 [注: ハードウェアへの投資は実際には最も低コストの投資です]
その後、それは消滅しました。 。 。
問題解決:
1. キャッシュできるコンテンツ (テキストなど) については、バックエンドの負荷を軽減するために NGINX レイヤーで CACHE を実行します。
2. 不要なインターフェイス処理を無効にします。 PHP は終了せずに直接戻ります。PHP-FPM への負担を軽減します
3. 要求されたバックエンド インターフェイス リソースを再編成し、ビジネスの重要性に応じて優先順位を付け、タイムアウトを厳密に制御します。
4. 新しい機器を追加し、ユーザー規模に基づいてサーバー リソースを再計算して構成します
5. リソース呼び出しログを記録し、依存リソースを監視します。リソースに問題が発生したら、すぐに解決できるプロバイダーを見つけます
6. MC キャッシュ構造を調整してキャッシュ使用率を向上させます
7. クライアントと十分に通信し、APP によるインターフェイス要求の順序と頻度を慎重に整理して、インターフェイスの効率的な使用率を向上させます。
この一連の改善策による効果は依然として明らかです。古い API と比較した新しい API のパフォーマンス上の利点は次のとおりです。 旧: 100 ミリ秒未満のリクエストが 55% を占めます
古い API 応答時間 
新機能: 93% 以上の応答時間は 100 ミリ秒未満です
新しい API 応答時間 
根本的な原因は主に、1.レスポンス不足、2.反復通信不足、3.堅牢性不足、4.PUSH機能
です。 1>、不適切な対応
年初からその時点までにユーザー数は2倍以上に増加しましたが、インターフェースの再構築の進捗は依然として遅く、最適化と検討のための十分な時間が残されておらず、そのまま戦いに突入しました。サーバー機器のリソースを適時に追加しなかったことが、大きな落とし穴につながりました。
2>、コミュニケーション不足
APP側のクラスメートや運営保守部門とのコミュニケーションが十分に取れず、足元ばかり気にしていました。端末学生と運用保守学生とのコミュニケーションを十分に取り、一体化してください。既存のリソース状況 (ハードウェア、ソフトウェア、依存リソースなど) に従って、さまざまなリソース要求のタイミングと頻度が詳細に合意され、メイン以外のアプリケーション インターフェイスの要求は適切に遅延され、メインのビジネスが確実に利用可能になり、サービスリソースを最大限に活用します。
注: クラスメートの Duanshang と良好なコミュニケーションを維持することが特に重要です。開発中、クラスメートは APP のビジネス ロジックのニーズに基づいてインターフェイスを要求します。要求しすぎると、自分の APP が多数のインターフェイスを起動することになります。自分のサーバーに対する Ddos 攻撃は非常に恐ろしいものです。 。
3>、堅牢性が不十分
信頼できるサードパーティのインターフェイスへの過度の依存、依存するインターフェイスの不当なタイムアウト設定、不十分なキャッシュ使用率、災害時バックアップの欠如、依存するリソースの問題は、死につながるだけです。
注: 不信の原則、依存するリソースを信頼しないでください。依存するインターフェイスがいつでもハングアップするように準備し、災害復旧対策を必ず講じ、厳格なタイムアウトを設定し、必要に応じてあきらめてください。 適切なサービスのダウングレード戦略を立てます。 [参考: 1. ビジネスのダウングレード、キャッシュを追加して更新頻度を減らす、2. メインのビジネスを確保、不要なビジネスを排除、3. ユーザーのダウングレード、一部のユーザーを放棄し、高品質のユーザーを保護]。 ログを記録する。ログはシステムの目であり、ログがシステムのパフォーマンスの一部を消費する場合でも、システムに問題が発生した場合は、ログを通じて問題を迅速に特定し、解決する必要があります。
4>、突然の大渋滞
PUSH とサードパーティは瞬時に大量のトラフィックをもたらしますが、これはシステムにとって耐え難いものであり、効果的なサーキット ブレーカー、電流制限、ダウングレードの自己保護手段が欠如しています。
要約: この質問を通じて私も多くのことを学び、システム アーキテクチャ全体についてより深く理解できました。同時に、何かをする前に綿密な準備をしなければならないこともあるということも分かりました。リファクタリングは単にコードを書き直すだけではなく、上流および下流のシステム リソース全体を十分に理解して認識する必要があり、これを怠ると必ず落とし穴に陥ります。
楽しみ、楽しみ、渋滞が近づいています、オリンピックが近づいています!
ボスのタオ兄弟は言いました:オリンピックがうまくいかなければ、生徒たちにたくさんの食事をごちそうします!オリンピックで何か問題が起こったら、タオ兄弟にごちそうをごちそうしてください!だから宴会には問題ないはず!
私たちはオリンピック前に準備を進め、オリンピックのトラフィックのピークを完全に乗り切ることができるように多くの最適化作業を実行してきました。
1. すべての依存リソースが慎重に分類され、主要なビジネス インターフェイスが注意深く監視されました
2. APP側にログレポートモジュールを導入し、異常なログをリアルタイムでレポートして監視します
3. MC クラスターをアップグレードおよび拡張し、システム キャッシュを均一に最適化および管理します
4. マルチレベルのビジネスサーキットブレーカーとダウングレード戦略を開始します
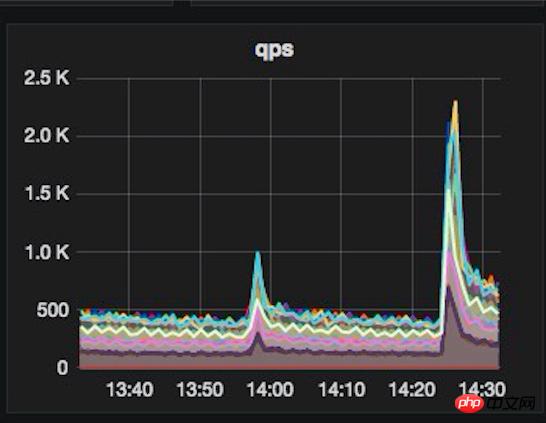
しかし、オリンピックはもうすぐそこまで来ており、システムは依然として大きな試練に直面しています。オリンピックの初めに、システムのすべての指標が問題なく正常に動作することを確認するために、私たちは社内にエンジニアを常駐させるよう手配しました。オリンピック初の金メダルとなった 1 日 24 時間の PUSH は、期待に応え、通常の 5 倍を超えるトラフィックで即座に成功を収めました。さまざまなリソースが逼迫し、サーバーがフル稼働し始めました。このとき、担当エンジニアは常に大きな監視画面に注目し、監視データやサーバーの負荷状況に応じてシステムパラメータを随時調整し、同時に各種データをウォームアップしていました。見事に初のオリンピック金メダルを獲得しました!最初の金メダルの後、私はオリンピック中に他の金メダル競技による交通量が最初の金メダルに比べてそれほど多くないことを観察し、オリンピックの交通量のピークはすべて安全に過ぎたと素朴に考えました。 【最初の金異常モニタリング画像は以下の通り】
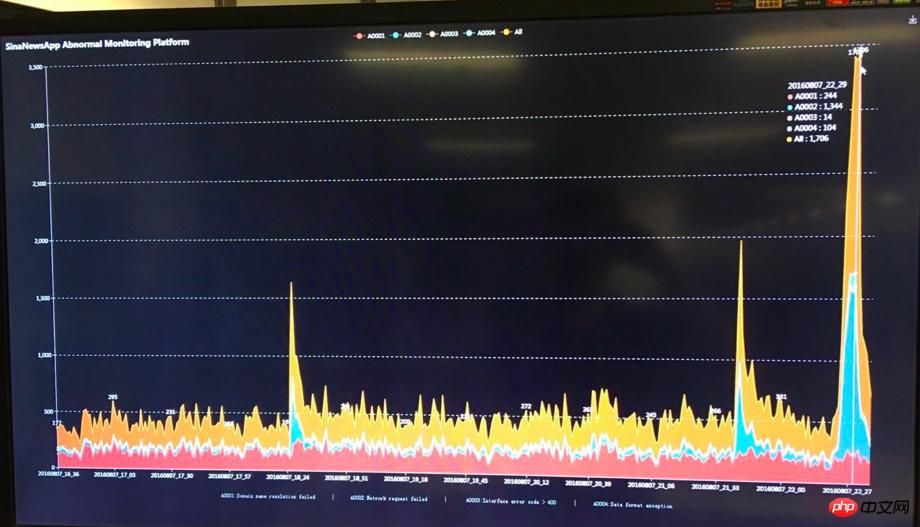
しかし、[神は善のために働く。 。 】オリンピックと重なって、突如起きた赤ちゃん事件!赤ちゃん事件の初日に PUSH によってもたらされたトラフィックは、多くの Bagua ユーザーの強力なサポートにより、最初のゴールドのピーク トラフィックをはるかに上回り、ついにサーバーは人生最大のテストに見舞われました。 、APP アクセスが PUSH で即座に応答し始め、遅いケースでは、リアルタイム監視時間の表示エラー率も増加し始めます。
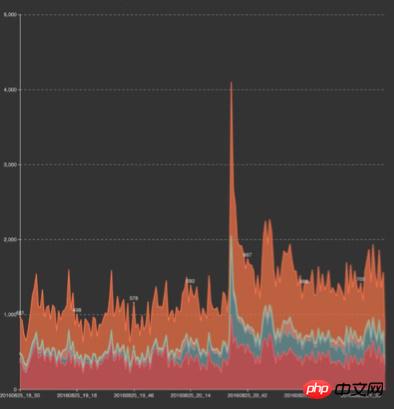 赤ちゃんイベントPUSHとオリンピックの重畳交通
赤ちゃんイベントPUSHとオリンピックの重畳交通
私たちはただちにシステムを過負荷から保護するための緊急計画を発動し、システム全体の可用性が影響を受けないように保護し、重要度の順にサービスをダウングレードしました(一般に、更新頻度の削減、キャッシュ時間の延長、非アクティブ化が含まれます)。システムがトラフィックのピークをスムーズに通過できること。ダウングレードを手動で有効にすると、システムは大量のリソースを急速に解放し始め、システム負荷は着実に減少し始め、ユーザー側の応答時間は通常のレベルに戻ります。 PUSH が経過したら (ピークは通常約 3 分間続きます)、手動でダウングレードをキャンセルします。
オリンピック期間中に突然発生した赤ちゃん事件でしたが、なんとか無事に乗り越え、サービス全体に問題はなく、この2つの事件でAPP全体のビジネスデータも大きく改善しました。
BOSSも生徒たちを招待してごちそうを食べて楽しい時間を過ごしました!
概要: 1. 監視システムをより詳細にする必要があり、リソース監視を追加する必要があります。事後分析により、見られた問題の一部はトラフィックが原因ではなく、トラフィックへの依存が原因である可能性があることが判明したためです。リソースの問題が発生し、システムの輻輳が発生し、影響が増幅されます。 2. 警報システムの充実3. 自動ダウングレード メカニズムのサービス管理システムは、確立を待機しています。突然のトラフィックや依存リソースの突然の異常が発生した場合、無人で自動的にダウングレードされます。
ビジネスが急速に発展しているため、システムのさまざまな指標に対してもより高い要件が課されています。1 つはサーバー側の応答時間です。
APP の 2 つのコア機能モジュールであるフィード ストリームとテキストの応答速度は、全体的なユーザー エクスペリエンスに大きな影響を与えます。まず、初期の目標として、平均応答時間を設定します。フィード ストリームの応答時間は 100 ミリ秒ですが、その時点でのフィードの全体的な応答時間は約 500 ~ 700 ミリ秒であり、まだまだ長いです。
フィード ストリーミング ビジネスは複雑で、リアルタイムの広告、パーソナライゼーション、コメント、画像間の転送、フォーカス画像、固定位置の配信など、多くのデータ リソースに依存しています。一部のリソースは、リアルタイムの計算データをキャッシュできません。 、キャッシングに頼ることはできず、別の方法を見つけて他の手段で解決するしかありません。
まず、運用保守チームと協力してサーバー ソフトウェア システム環境全体をアップグレードし、Nginx を Tengine にアップグレードし、次に PHP をアップグレードしました。アップグレードの効果は明らかで、全体の応答時間が約 20% 短縮されました。パフォーマンスは向上しましたが、目標にはまだ程遠いです。最適化が続くにつれて、フィードのビジネス リンク全体に対してログ分析を実行して、最もパフォーマンスを消費している領域を特定し、それらを 1 つずつ解決します。
元のサーバー構造は次のとおりです:
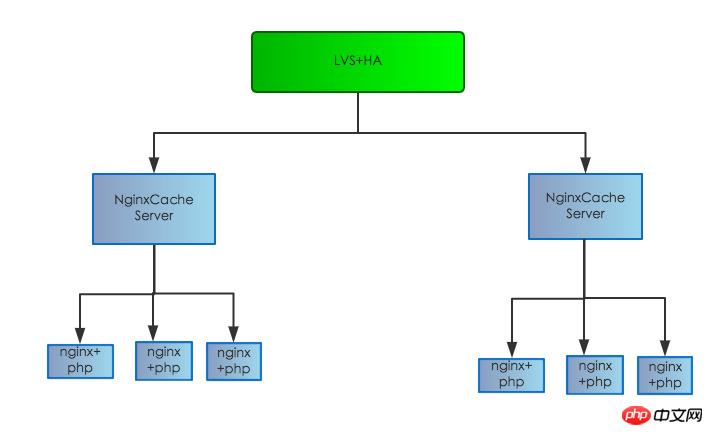
これは、負荷分散層、プロキシ層、Web 層に分かれています。クライアント アクセスは、最初に Nginx プロキシ層プロキシを介して Nginx+PHP-FPM Web マシンに転送されます。プロキシも存在します。レイヤーと Web マシンが同じデバイス上にない場合、または同じコンピュータ ルーム内にある場合でも、大幅なパフォーマンスの低下が発生する可能性があることが、予想通りの応答時間であることがわかりました。プロキシ層の Nginx ログ レコードは Web 層のログ レコードの応答時間よりも数十ミリ秒、さらには数百ミリ秒も長く、元のキャッシュ層に 1 つのエラーが存在します。 ボトルネックのリスクが見つかったので、サーバー構造を調整しました。元のキャッシュ層をオフラインにし、それを Web フロントエンド マシンに移動して、単一点のボトルネックを軽減し、サービス全体の可用性に影響を与える単一点の障害のリスクを排除します。
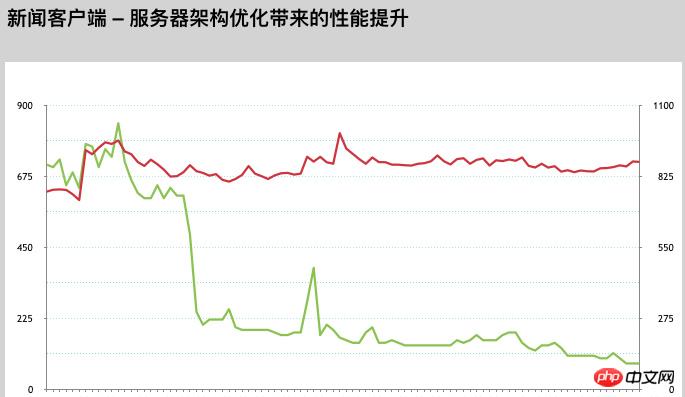
サーバー構成の調整が完了した後は、フィードの応答時間も大幅に短縮され、パフォーマンスが大幅に向上し、約 200 ~ 350 ミリ秒に達しました。設定した目標には近づいているものの、まだ設定した目標を達成できていない。
ある日、当社のエンジニアは、コードのデバッグ中に、PHP-CURL によって設定されたミリ秒のタイムアウトが無効であることを偶然発見しました。私たちは、PHP に付属のデフォルトの CURL ライブラリがミリ秒をサポートしていないことを多数のテストを通じて確認しました。公式 PHP ドキュメントによると、古いバージョンの PHP libcurl ライブラリにこの問題があることがわかりました [後で、社内のほとんどのビジネス PHP バージョン環境にこの問題があることがわかりました] これは、システムが有効にならなかったことが、システムのパフォーマンスの遅れの原因となっていました。この問題を解決することで、全体的なパフォーマンスが確実に向上することがわかりました。その後、すぐにオンラインのグレースケール検証テストを開始しました。数日間のオンライン テストでは他に問題は見つからず、パフォーマンスが大幅に向上したため、すべてのサーバーがオンラインになるまで範囲を徐々に拡大しました。データによると、libcurl バージョン ライブラリがアップグレードされた後、サーバー フィードの応答時間が直接増加しました。他の最適化を行わずに 100-100 に達したのは明らかです。約 150 ミリ秒です。
サーバー構造層とソフトウェア システム環境層はできる限りのことを実行しましたが、平均フィード応答時間の設定要件である 100 ミリ秒にはまだ達していません。その時点では、オンライン フィードからしか開始できません。連続して実行されるリソースに依存するフロー リクエストは、リソースの輻輳により後続のリクエストがキューに入れられ、全体の応答時間が増加します。私たちは、PHP CURL をマルチスレッドの同時リクエストに変更し、シリアルをパラレルに変更し、複数の依存リソース インターフェイスを待たずに同時にリクエストすることを試み始め、CURL クラス ライブラリを書き換えて To を提供しました。問題を回避するために、私たちは長期間にわたる大規模なグレースケール テストの検証を実施し、テストは成功し、オンラインの実稼働環境にリリースされました。同時に、サーバー フィード ストリームの応答時間は大幅に短縮されました。同時に、インターフェイスの平均応答時間は 15ms 以内に制御されます。
フィードフローの応答時間
 テキストの平均応答時間
テキストの平均応答時間
その後、各コンピューター ルームにサーバーを分散配置し、VIP ネットワーク アクセス ノードを再分散し、ネットワーク通話リソースを最適化し、オペレーター間、南北間のアクセスによって引き起こされる可能性のあるユーザー エクスペリエンスへの悪影響を回避しました。
上記の多数の最適化調整により、システム全体の収容能力も大幅に向上しました。
現在のピーク QPS は 134,000 に達し、1 日の最大 HIT リクエスト数は約 8 億に達しており、そのボリューム レベルはすでに非常に印象的です。
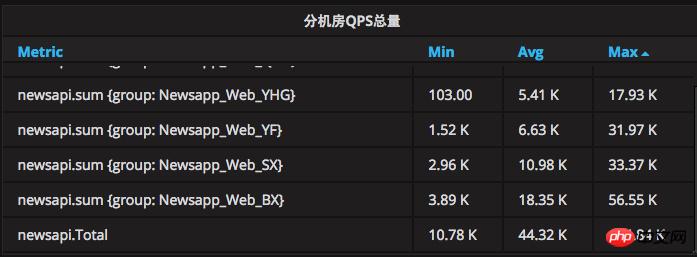
単一マシンの QPS 搬送能力も大幅に向上しました。単一マシンによる元の 500 ~ 800QPS システムはフル装備でしたが、現在では単一マシンによる 2.5K システムは依然として堅固で動きません。
チームメンバーのたゆまぬ努力と、運営・保守の学生の多大な協力のおかげで、ニュースAPPインターフェースシステムのパフォーマンスと耐負荷性は大幅に向上しました。
戦略を立てることによってのみ、千マイルを勝ち取ることができます。
ニュース APP のインターフェイスは現在、何百ものサードパーティのインターフェイスとリソースに依存しています。1 つ以上のインターフェイスやリソースで問題が発生すると、システムの可用性に影響を与える可能性があります。
このような状況を踏まえ、本システムの設計・開発を行った主なシステムモジュールは以下の通りです。 サービスの自己保護、サービスの低下、エラー分析、コール チェーンの監視、監視と警報。リソース寿命検出システム、インターフェイス アクセス スケジューリング スイッチに依存した自社構築のオフライン データ センター。オフライン データ センターは主要なビジネス データをリアルタイムで収集し、寿命検出システムはリソースの健全性と可用性をリアルタイムで検出し、インターフェイス アクセス スケジューリング スイッチシステムがリソースの問題を検出すると、インターフェイスのアクセス制御スイッチを通じて自動的にダウングレードしてアクセス頻度を減らし、データ キャッシュ時間を自動的に延長します。また、寿命検出システムは継続的に検出します。リソースが完全に利用できなくなると、制御スイッチは自動的にサービスを低下させるためにインターフェイス要求のアクセスを完全に閉じ、ローカル データ センターがユーザーにデータを提供できるようにします。リソースが利用可能であることをライフ プローブが検出したら、通話を再開します。
このシステムは、リソース (CMS、コメント システム、広告など) への大きな依存を何度も回避することに成功しました。障害 依存するリソースに障害が発生した場合、ビジネスの対応は次のとおりです。基本的にユーザーには見えません。同時に、問題をできるだけ早く予測、発見、解決できるように、完全な例外監視、エラー分析、およびコール チェーン監視システムを確立しました (第 7 章サーバーの高可用性で詳細を参照)。 同時に、クライアントのビジネスは急速に発展し続けており、深刻なコードの問題を発生させることなく、各機能モジュールが迅速に更新および反復されるため、コードのグレースケールとリリース プロセスも増加しました。新しい機能が起動されると、まずグレースケール検証が行われ、検証に合格した後、新しい機能に問題がある場合は、新旧のスイッチング モジュールが予約されます。 、通常のサービスを確保するために、いつでも古いバージョンに切り替えることができます。
サービスガバナンスプラットフォームテクノロジーの実装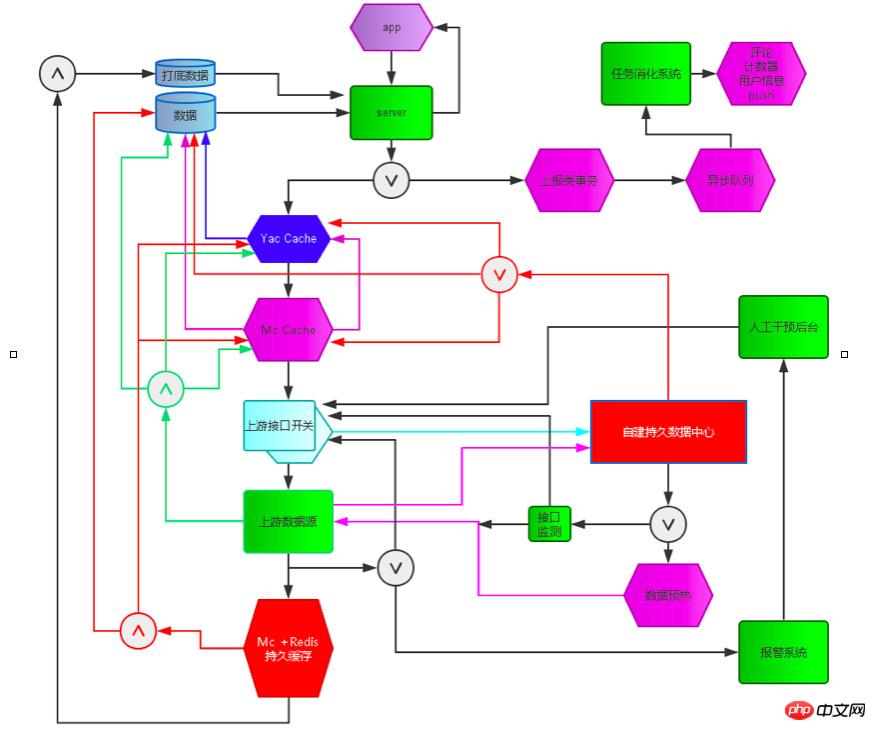
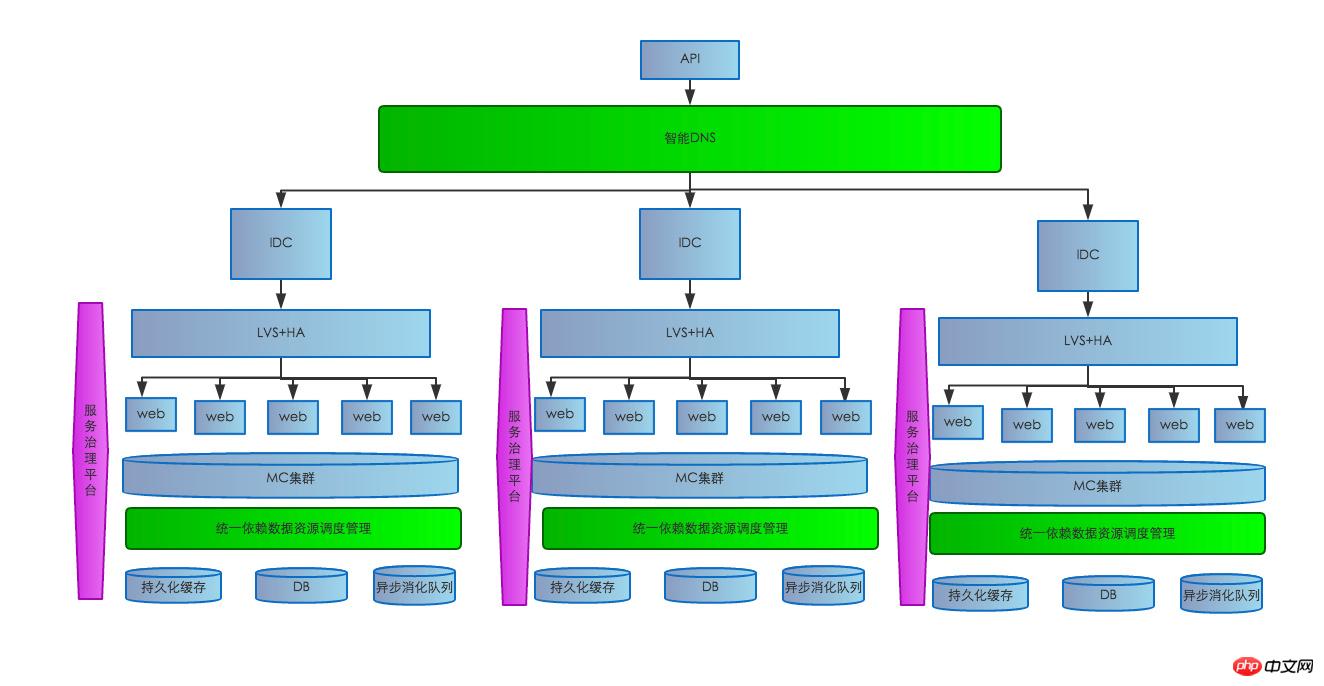
サービス管理プラットフォームが構築された後のシステム サービス アーキテクチャはおおよそ次のとおりです:
7. 大乗: サーバーの高可用性
システムの可用性(Availability)の定義式は、 Availability = MTBF / ( MTBF + MTTR ) × 100%
MTBF (Mean Time Between Failure) は平均故障間隔であり、システム全体の信頼性を表す指標です。大規模な Web システムの場合、MTBF は、システム全体のサービスが中断や障害なく継続的に実行される平均時間を指します。
平均システム回復時間である MTTR (平均修復時間) は、システム全体の耐障害性を表す指標です。
大規模な Web システムの場合、MTTR は、システム内のコンポーネントに障害が発生したときに、システムが障害状態から通常の状態に回復するまでにかかる平均時間を指します。
この式から、MTBF を増やすか MTTR を減らすとシステムの可用性が向上することがわかります。
そこで問題となるのは、これら 2 つの指標を通じてシステムの可用性をどのように向上させるかということです。
上記の定義から、高可用性の重要な要素である MTBF はシステムの信頼性 [平均故障間隔] であることがわかります。
次に、MTBF に影響を与える可能性のある要因を列挙します。1. サーバー ハードウェア、2. ネットワーク、3. データベース、4. キャッシュ、5. 依存リソース、6. コード エラー、7. 突然の大規模なトラフィック、高い同時実行性。これらの問題が解決され、障害が回避され、MTBF が改善されます。
これらの質問に基づいて、ニュース クライアントは現在どのように対応していますか?
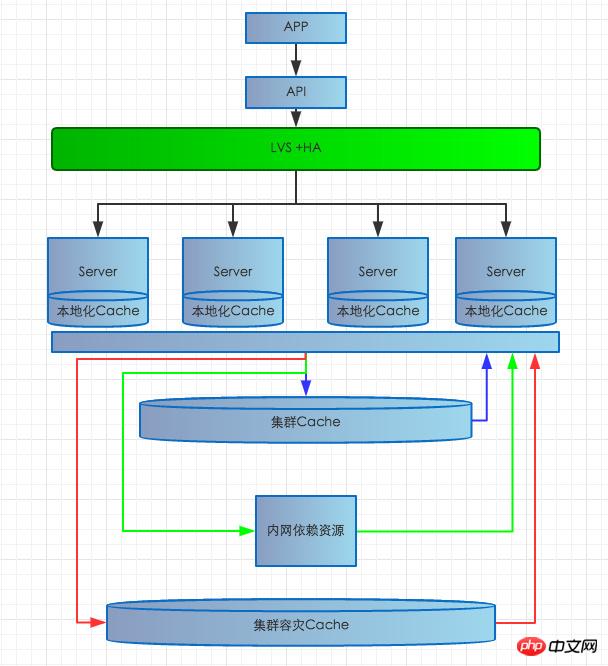
最初のサーバーハードウェア障害: 以下の構造に示すように、サーバーハードウェア障害によりこのサーバー上のサービスが利用できなくなる場合、現在のシステムは複数の MEM サーバーが接続された LVS+HA であり、寿命が長くなります。 LVS+HA の場合 検出システムが異常を検出すると、ユーザーが問題のあるサーバーにアクセスして障害が発生するのを防ぐために、そのシステムは時間内に負荷分散から削除されます。
2 番目の内部ネットワークの問題: 大規模な内部ネットワーク障害が発生すると、依存リソースの読み取り失敗、データベースへのアクセス失敗、キャッシュ クラスターの読み書き失敗などの一連の問題が発生します。 、比較的大きな影響とより深刻な結果をもたらします。それでは今回も記事を書いていきます 一般的に、ネットワークの問題は主にコンピュータ室間のアクセスが遮断または遮断された場合に発生します。同じコンピュータ室のネットワークが切断されることは非常にまれです。一部の依存インターフェイスは異なるコンピューター ルームに分散されているため、コンピューター ルーム間のネットワークの問題は主に依存インターフェイスの応答の遅さやタイムアウトに影響します。この問題に対しては、依存するコンピューター ルーム間のマルチレベル キャッシュ戦略を採用します。インターフェイスが異常な場合、ローカル キャッシュが侵入された場合は、ローカル コンピュータ ルームのキャッシュ クラスタのリアルタイム キャッシュが最初に取得されます。ローカル コンピュータ ルームの永続的な防御キャッシュにアクセスする場合、永続的なキャッシュにヒットがない場合、バックアップ データ ソースはユーザーに返されますが、同時に予熱されたバックアップ データ ソースのみがキャッシュされます。ユーザーがそれに気付かず、大規模な障害を回避できるように永続的に実行されます。ネットワークの問題によるデータベース遅延の問題を解決するには、主に非同期キュー書き込みを使用してリザーバーを増やし、データベース書き込みが混雑してシステムの安定性に影響を与えるのを防ぎます。
6番目のコードエラー: これまでにもコーディングエラーが原因で大惨事のオンライン障害が発生したケースがあり、多くの問題は低レベルのエラーが原因であるため、私たちはこれにも焦点を当てていますこの分野では多くの作業が行われてきました。
まず、コードの開発とリリースのプロセスを標準化する必要があり、ビジネスの成長に伴い、システムの安定性と信頼性に対する要件も日々増加しており、開発チームのメンバーの数も増加しています。焼畑農業と単独作業の原始的な社会状態。すべての作業は標準化され、プロセス指向である必要があります。
開発環境、テスト環境、シミュレーション環境、オンライン環境、オンラインプロセスを改善しました。エンジニアは開発環境でセルフテストを完了した後、テスト環境について言及し、テストに合格した後、シミュレーション環境に移動してシミュレーションテストを実施します。オンライン システムを使用するには、オンライン リグレッションが完了すると、オンライン リグレッション検証が実行され、コードのオンライン プロセスが終了します。検証が失敗した場合は、オンライン システムをワンクリックで起動前の環境にロールバックできます。
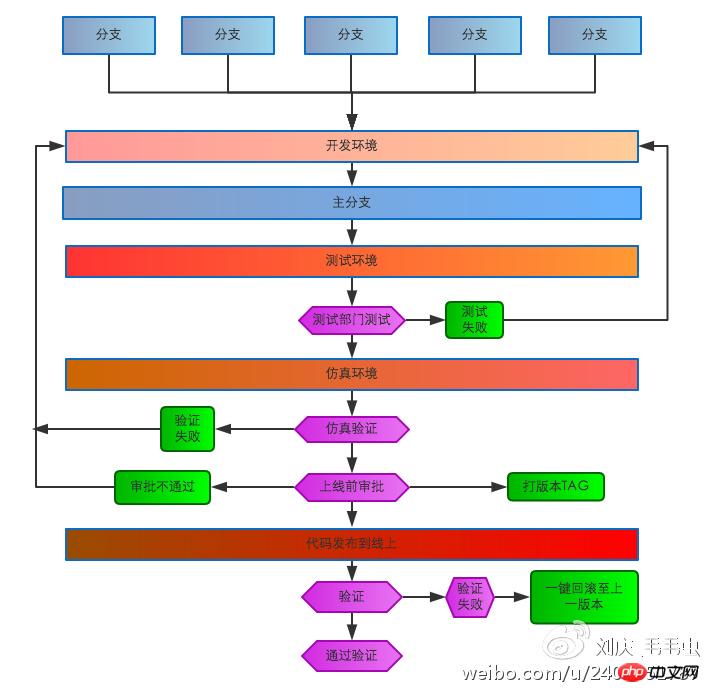 コードの開発とリリースのプロセス
コードの開発とリリースのプロセス
それでは第 7 条について: 突然の大規模なトラフィックと高い同時実行性にどう対処するか?
通常、突発的な大規模なトラフィックは、システム ソフトウェアおよびハードウェアの予想される負荷範囲をはるかに超える、短期間に大量のアクセス リクエストをもたらすホットスポットおよび緊急事態として定義されます。これを処理しないと、サービス全体に影響を与える可能性があります。この状況が短期間続くと、新しいオンライン マシンを一時的に追加するのが遅すぎて、マシンがオンラインになり、トラフィックのピークが過ぎた後では無意味になってしまいます。いつでも大量のバックアップ マシンがオンラインで準備されている場合、これらのマシンは 99% の時間アイドル状態になり、多くの財務的および物的リソースが無駄になります。
このような状況では、完全な運行計画システムとサービスサーキットブレーカーおよび電流制限措置が必要です。特定の特定のエリアから突然大量のトラフィックが発生した場合、または 1 つ以上の IDC コンピュータ ルームにトラフィックが集中した場合、負荷の高いコンピュータ ルームからアイドル トラフィックが発生しているコンピュータ ルームにトラフィックの一部を分割して、圧力を共有することができます。ただし、トラフィックのセグメント化だけでは問題を解決できない場合、またはすべてのコンピュータ ルームのトラフィック負荷が比較的高い場合は、サーキット ブレーカーと電流制限によってシステム サービス全体を保護するしかありません。まず、優先順位に従って並べ替えます。ビジネス モジュールをダウングレードし、優先度の低いビジネスに従ってダウングレードを実行します。ビジネス ダウングレードでも問題が解決できない場合は、重要な機能モジュールを維持し、外部サービスの提供を継続するために、優先度の低いサービスを 1 つずつ無効化します。極端な場合、ビジネスのダウングレードがトラフィックのピークに耐えられない場合は、少数のユーザーを一時的に放棄し、価値の高いユーザーの可用性を維持します。
高可用性を示すもう 1 つの重要な指標として、MTTR システムの平均回復時間があります。これは、障害後にサービスが回復するまでにかかる時間です。
この問題を解決するための主なポイントは、1. 障害を見つける、2. 障害の原因を特定する、3. 障害を解決することです
これら 3 つの点は同様に重要です。まず、問題が発生したとしても問題はありません。そのために問題が大量に発生したのです。これはユーザーの損失の中で最も深刻なことです。では、故障を時間内に検出するにはどうすればよいでしょうか?
監視システムは、システム全体、さらには製品ライフサイクル全体においても最も重要なリンクであり、障害を事前に検出するためのタイムリーな警告を提供し、その後、問題を追跡して特定するための詳細なデータを提供します。
まず第一に、監視は私たちの目で行う必要がありますが、時間内に警報を発し、問題に対処するために関係者に通知するだけでは十分ではありません。この点に関して、私たちは運営保守部門の支援を得て、支援的な監視および警報システムを確立しました。
一般的に、完全な監視システムには主に次の 5 つの側面があります: 1. システム リソース、2. サーバー、3. サービス ステータス、4. アプリケーション例外、5. アプリケーション パフォーマンス、6. 例外追跡システム
1. システムリソースの監視
さまざまなネットワーク パラメータとサーバー関連リソース (CPU、メモリ、ディスク、ネットワーク、アクセス要求など) を監視して、サーバー システムの安全な動作を確保し、システム管理者がさまざまな問題を迅速に発見/解決できるようにする例外通知メカニズムを提供します。既存の問題。
2. サーバー監視
サーバー監視は主に、各サーバー、ネットワークノード、ゲートウェイ、その他のネットワーク機器のリクエスト応答が正常かどうかを監視します。定期サービスでは、各ネットワークノード装置に定期的に ping を送信し、各ネットワーク装置が正常かどうかを確認し、異常がある場合にはメッセージリマインダを発行します。
3. サービスの監視
サービス監視とは、さまざまな Web サービスやその他のプラットフォーム システムのサービスが正常に実行されているかどうかを指します。スケジュールされたサービスを使用して、関連するサービスを定期的に要求し、プラットフォームのサービスが正常に実行されていることを確認できます。
4. アプリケーション例外の監視
主に異常タイムアウトログやデータフォーマットエラー等が含まれます
5. アプリケーションのパフォーマンス監視
本業の応答時間指標が正常かどうかを監視し、本業のパフォーマンス曲線の傾向を表示し、潜在的な問題をタイムリーに発見して予測します。
6. 例外追跡システム
例外追跡システムは、システム全体が依存する上流および下流のリソースを主に監視し、応答時間の変化やタイムアウト率の変化など、依存するリソースの健全性状態を監視することで、早期の判断と対処を可能にします。システム全体で起こり得るリスク。また、発生した障害を迅速に特定し、その障害が依存関係リソースの問題によって引き起こされているかどうかを確認し、障害を迅速に解決することもできます。
現在オンラインで使用している主な監視システムは次のとおりです:
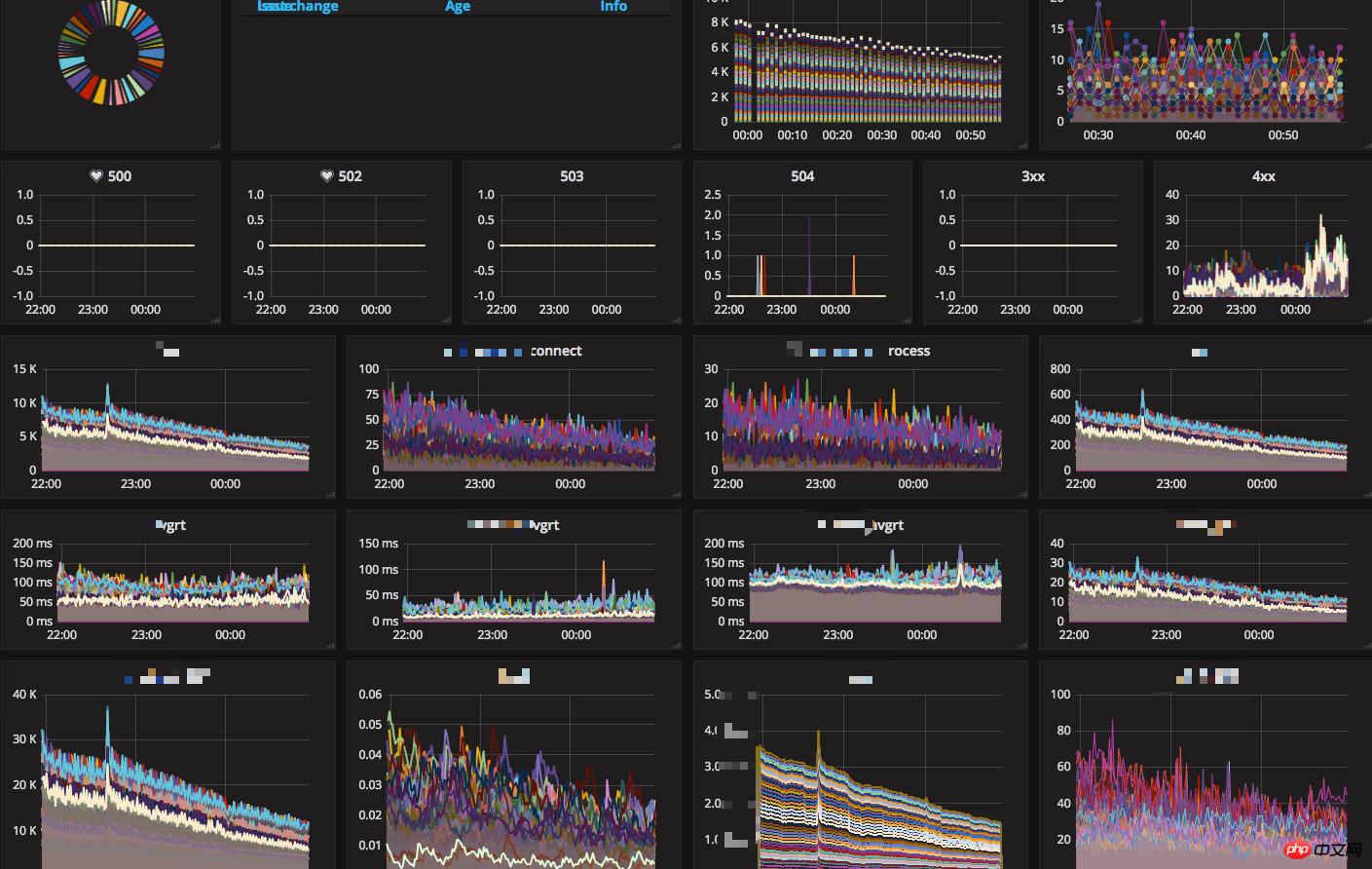 News APPのバックエンドシステムアーキテクチャの成長への道 - 高可用性アーキテクチャ設計の詳細なグラフィックとテキストの説明
News APPのバックエンドシステムアーキテクチャの成長への道 - 高可用性アーキテクチャ設計の詳細なグラフィックとテキストの説明
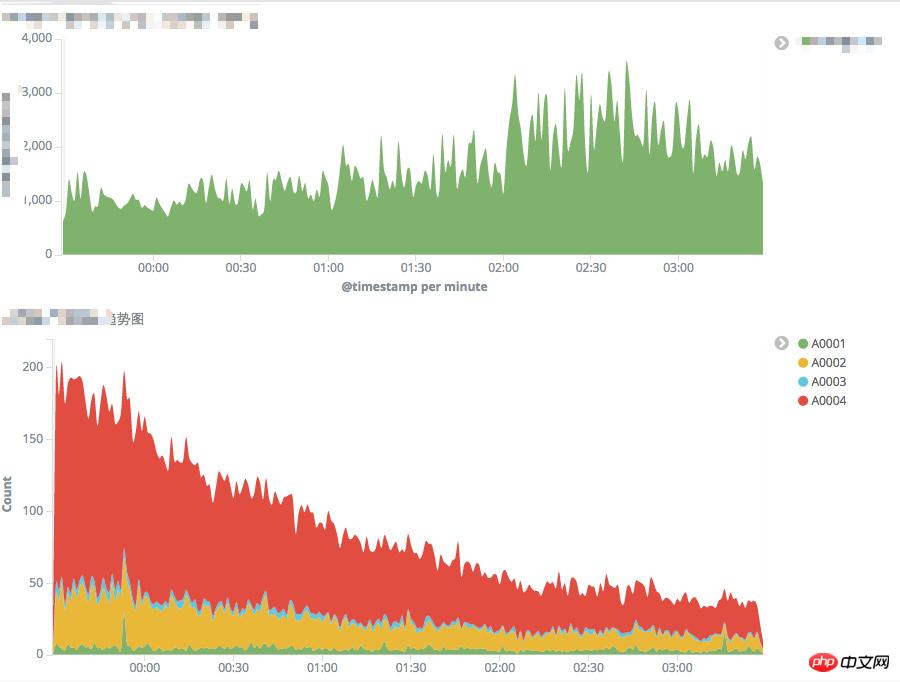
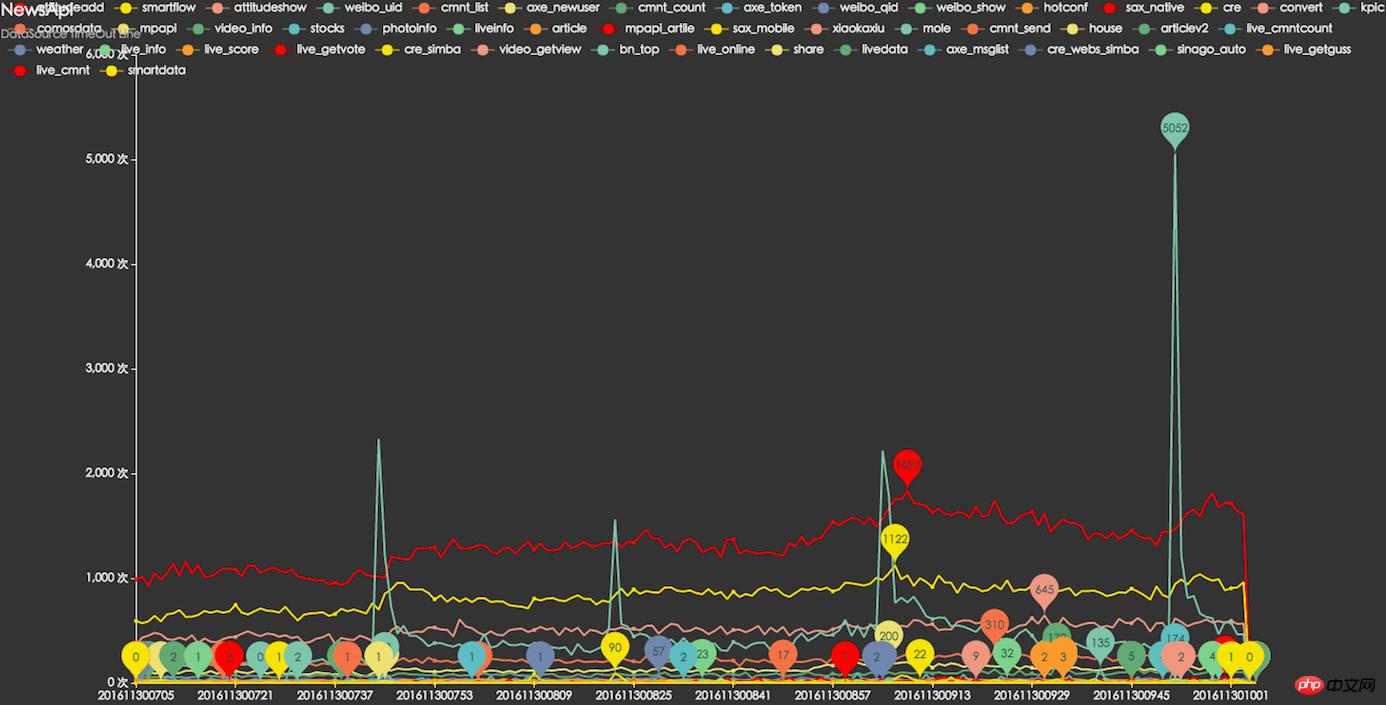 依存リソースのタイムアウト監視
依存リソースのタイムアウト監視
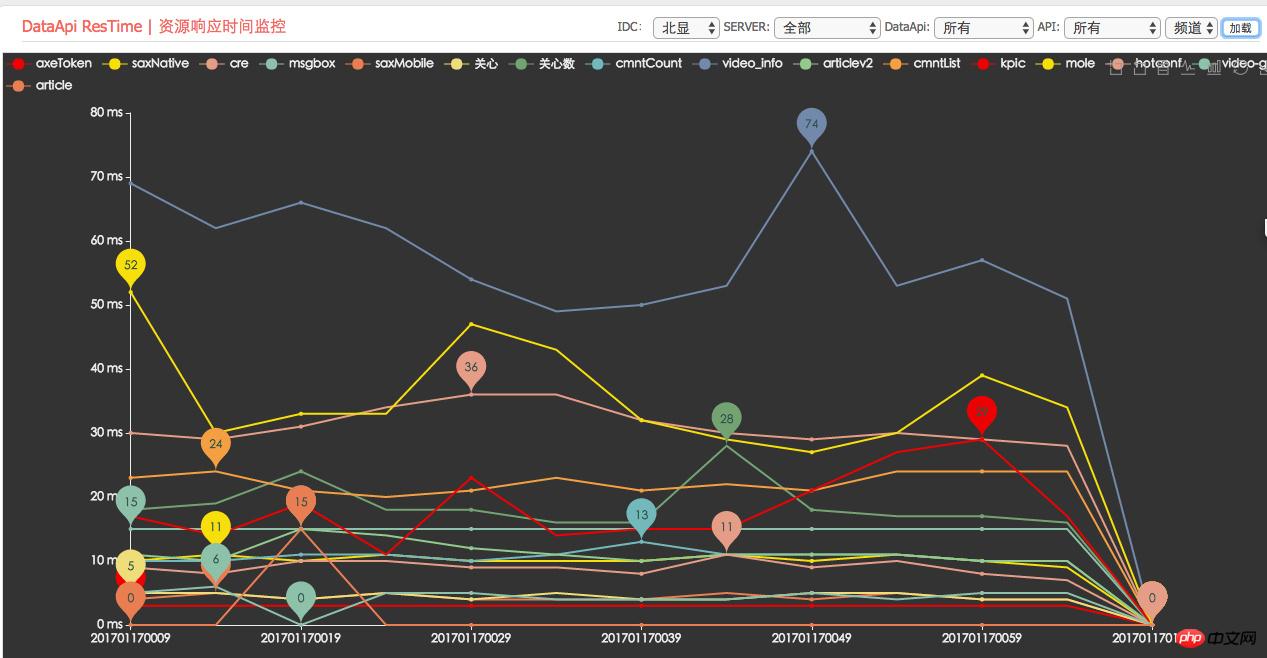 依存リソースの平均応答時間の監視
依存リソースの平均応答時間の監視
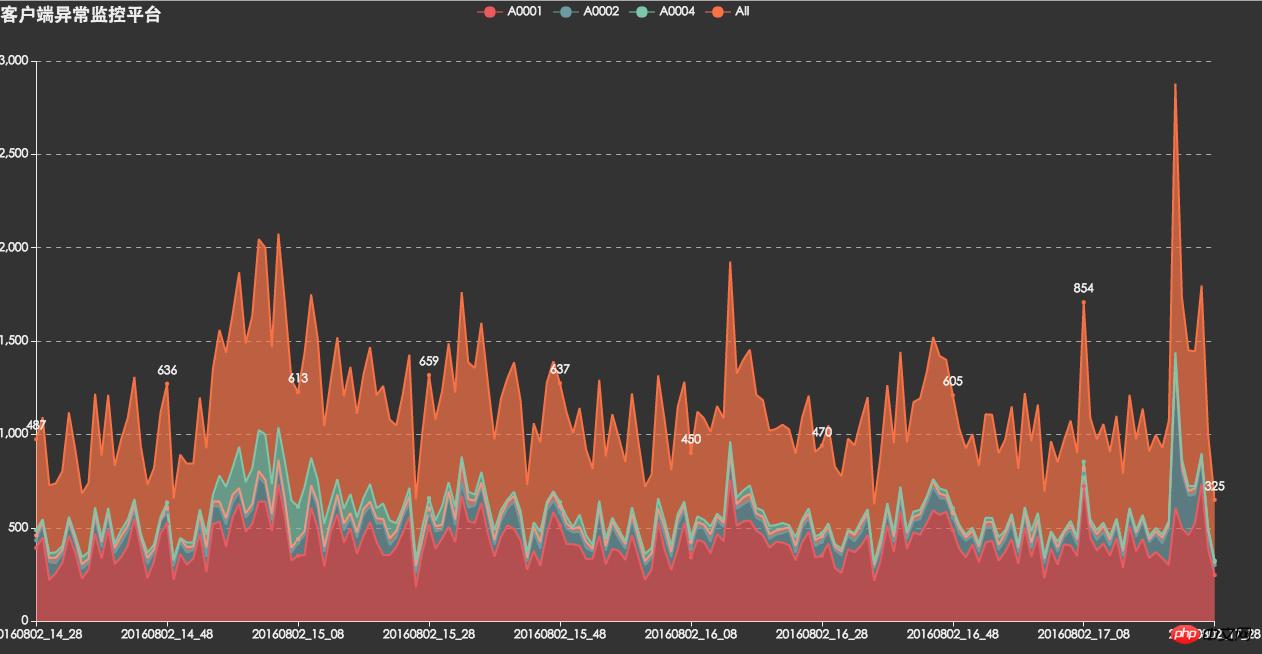 APIエラー監視
APIエラー監視
注: [引用、考察] 監視システムの品質を判断する主なポイントは 2 つあります。1. 綿密であること、2. 一目で明確であることです。この二つは一見矛盾しているように見えますが、詳細なモニタリングプロジェクトはたくさんあるはずなので、一見すると明確ではないはずですが、そうではありません。一目で明確であるということは、主に問題を時間内に検出できるということです。なぜなら、何百もの監視チャートを常に見つめるほど多くの時間とエネルギーを確保することは不可能だからです。次に、さまざまなインジケーターが正常かどうかを要約し、問題を一目で特定できるように異常なインジケーターをリストする完全なダッシュボードが必要です。細心の注意を払うのは主に、問題が発生した後のトラブルシューティングの準備です。さまざまな監視データ ポイントが正常かどうかを確認して、問題を迅速に特定できます。
【2017 年の重要目標、クライアントの高可用性】
最近、インターネット メディアで HTTPS に関する記事が多く取り上げられています。その理由の 1 つは、事業者の悪質な行為の根幹がますます低下しており、数日前からいくつかのインターネット企業が広告を挿入するようになったことです。交通ハイジャックなど違法行為への抵抗に関する共同声明を共同で発表し、一部の事業者を非難した。 その一方で、Apple の ATS ポリシーによっても強力に推進されており、すべてのアプリで HTTPS 通信を使用することが強制されています。 HTTPS を使用することには、ユーザー データの漏洩からの保護、仲介者によるデータの改ざんの防止、企業情報の認証など、多くの利点があります。
HTTPS テクノロジーが使用されていますが、一部の邪悪な事業者は HTTPS をブロックし、DNS 汚染テクノロジーを使用してドメイン名を独自のサーバーにポイントし、DNS ハイジャックを実行します。
この問題が解決されなければ、HTTPSでも問題を根本的に解決することはできず、依然として多くのユーザーがアクセスの問題を抱え続けることになります。少なくとも製品に対する不信感を招く可能性はありますが、最悪の場合、ユーザーが製品を使用できなくなるなど、ユーザーの損失に直結する可能性があります。
では、サードパーティのデータによると、Goose Factory のようなインターネット企業にとって、異常なドメイン名解決はどれほど深刻なのでしょうか? Gouchang の分散型ドメイン名解決監視システムは、全国の主要な LocalDNS を毎日継続的に検出しています。全国の Gouchang ドメイン名の 1 日あたりの解決例外の数は 800,000 件を超えています。これにより、ビジネスに多大な損失が発生しました。
通信事業者は広告収入を稼ぎ、ネットワーク間の決済を節約するためなら何でもするだろう。 彼らが使用する一般的なハイジャック方法は、ISP を通じて偽の DNS ドメイン名を提供することです。
「実は私たちも同じ深刻な問題に直面しています」
ニュースAPPのログ監視と分析を通じて、ユーザーの1%〜2%がDNS解決の異常とインターフェースアクセスの問題を抱えていることが判明しました。
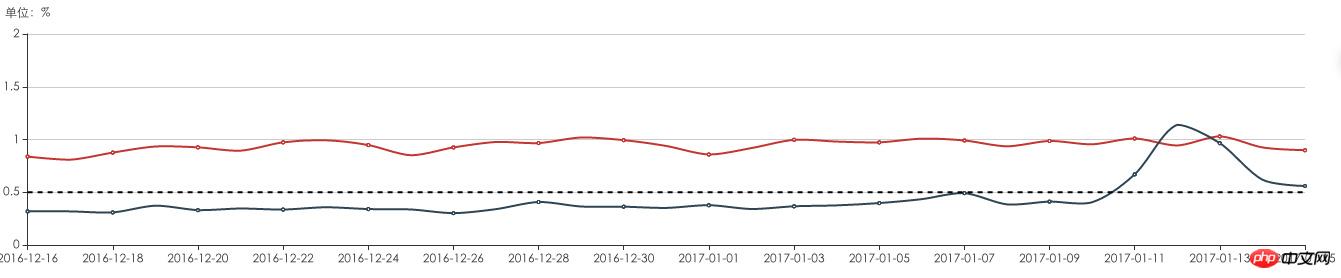
DNS例外が発生し、インターフェースにアクセスできません
特にビジネスが急速に発展していた時期には、目に見えずに大量のユーザー損失を引き起こし、ビジネスエクスペリエンスに大きな損害を与えました。
では、ドメイン名解決の異常、ユーザーアクセスのクロスネットワーク問題、DNSハイジャックの根本原因を解決できる技術的な解決策はあるのでしょうか?
業界には、この種のシナリオを解決するソリューション、つまり HTTP DNS があります。
HttpDNS はどのような問題を解決しますか?
HttpDNS は主に 3 種類の問題を解決します:モバイル インターネットにおける DNS 解決の異常と LocalDNS ドメイン名のハイジャックを解決し、平均応答時間が増加し、ユーザーの接続失敗率が依然として高い
1 .DNS 解決の異常と LocalDNS ハイジャック:モバイル DNS の現状: オペレーターの LocalDNS エクスポートは、権威 DNS のターゲット IP アドレスに基づいて NAT を実行するか、解決要求を他の DNS サーバーに転送するため、権威 DNS がオペレーターの LocalDNS IP を正しく識別できなくなり、ドメイン名が発生します。解決エラーとネットワークを通過するトラフィック。
2. 平均アクセス応答時間の増加:
IP に直接アクセスされるため、ドメイン解決プロセスが省略され、インテリジェントなアルゴリズムでソートされた後、最速のノードが検索されてアクセスされます。3. ユーザー接続の失敗率の削減:
アルゴリズムを通じて過去に過剰な失敗率を示したサーバーのランキングを下げ、最近アクセスされたデータを通じてサーバーのランキングを向上させ、過去のアクセス成功記録を通じてサーバーのランキングを向上させます。 ip(a)へのアクセスエラーがあった場合、次回はip(b)またはip(c)のソート済みレコードが返されます。 (LocalDNS は 1 つの ttl (または複数の ttl) 内のレコードを返す可能性がありますHTTPS は、コンテンツ セキュリティの改ざんを含め、オペレーターによるトラフィックのハイジャックを最大限に防ぐことができます。
HTTP-DNS はクライアント DNS の問題を解決し、ユーザー要求が最速の応答でサーバーに直接送信されるようにします。 HttpDNS 実装の原理 HTTP DNS の原理は非常にシンプルで、簡単に乗っ取られるプロトコルである DNS を HTTP プロトコル リクエストに変換します。DomainIP マッピング。 正しい IP を取得した後、クライアントは独自に HTTP プロトコルを組み立て、ISP によるデータの改ざんを防ぎます。
クライアントは HTTPDNS インターフェイスに直接アクセスして、ドメイン名の最適な IP を取得します。 (災害復旧の考慮事項に基づいて、オペレーターの LocalDNS を使用してドメイン名を解決する方法が代替手段として予約されています。) クライアントはビジネス IP を取得した後、この IP にビジネス プロトコル リクエストを直接送信します。 HTTP リクエストを例に挙げると、ヘッダーのホスト フィールドを指定することで、HTTPDNS によって返された IP に標準の HTTP リクエストを送信できます。
クライアント側で高可用性を実現したい場合は、まずこの問題を解決する必要があります。私たちは、APP ユーザーに高可用性を実現し、ビジネスの迅速な発展のための信頼できる保証を提供するために、HTTPDNS をできるだけ早く開始できるよう、APP 開発学生と運用保守学生と一緒に準備を開始しました。
1 年間の懸命な努力を経て、APP バックエンド システム全体は基本的に野蛮な時代から現在の完璧な状態になりました。また、少し探索して多くの知識を学び、達成したと思います。大きな成長を遂げていますが、同時に、ビジネスの急速な発展に伴い、バックエンドサービスに対する要求もますます高くなり、将来的に解決しなければならない多くの問題にも直面しています。私たちはまた、より高い基準を維持し、数億人のユーザー規模に備えるつもりです。以上は、ニュース APP のバックエンド システム アーキテクチャの成長への道です。高可用性アーキテクチャの設計グラフィック デザインの詳細な内容については、PHP 中国語 Web サイト (www. php.cn)!
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



