

この記事では主に、オンライン mysql オプティマイザーの誤った判断によって引き起こされる遅いクエリ イベントの関連情報と最終的な解決策を紹介します。インスピレーションを与えることを願って、それを共有します。
前書き:
非常に遅いクエリとリクエストのタイムアウト アラームを受け取り、メトリクス、cli —> show proceslist を通じて mysql リクエストからの例外を分析し、多くの遅いクエリを確認しました。 このSQLは以前は存在しませんでしたが、データ量の増加により後からこの問題が発生しました。 フィード テーブルは 1 億件にも及びますが、フィード フロー情報には最近のホットな特徴があるため、頻繁な IO は innodb_buffer_pool_size の非効率によって引き起こされるものではありません。 その後、実行プラン分析についてさらに説明したところ、mysql クエリ オプティマイザーが効率的であると考えられるインデックスを選択したことがわかりました。
mysql クエリ オプティマイザーはほとんどの場合信頼できますが、SQL 言語に複数のインデックスが含まれている場合は、最終的な結果が少し不安定になることがよくあります。 mysql は同じ SQL に対して 1 つのインデックスしか使用できないため、どれを選択すればよいでしょうか? データ量が少ない場合、MySQL オプティマイザは主キー インデックスをポストし、インデックスと一意性を優先します。 データ レベルに到達すると、クエリ操作が実行されるため、mysql クエリ オプティマイザーは主キーを使用する可能性があります。
一文を思い出してください。mysql クエリの最適化は、時間コストの考慮事項ではなく、取得コストの考慮事項に基づいています。 オプティマイザーは、実際に SQL を実行するのではなく、既存のデータのステータスに基づいてコストを計算します。
そのため、mysql オプティマイザーは毎回最適化結果を達成できるわけではありません。 各指標のコストを正確に知りたい場合は、実際に実行してみないとわかりません。したがって、コスト分析はあくまで見積もりであるため、誤った判断が行われる可能性があります。
ここで説明するテーブルはフィード情報フロー テーブルです。フィード情報フロー テーブルには頻繁にアクセスされるだけでなく、大量のデータが含まれることがわかっています。 ただし、このテーブルのデータ構造は非常に単純で、インデックスも単純です。インデックスは主キー インデックスと一意キー インデックスの合計 2 つだけです。
以下のように、キャッシュが十分にあるため、データベースとテーブルを分割する時間がないため、このテーブルのサイズは 1 億レベルに達しました。
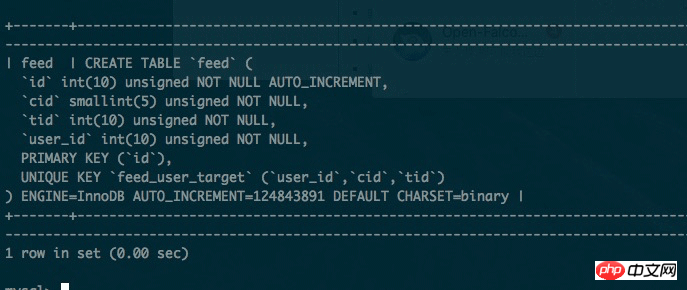
問題は、データの規模が 1 億未満の場合、mysql オプティマイザーはインデックス インデックスの使用を選択しますが、データの規模が 1 億を超えると、mysql クエリ オプティマイザーは主キー インデックスの使用を選択します。これにより生じる問題は、クエリ速度が遅すぎることです。
これは通常の状況です:
mysql> explain SELECT * FROM `feed` WHERE user_id IN (116537309,116709093,116709377)
AND cid IN (1001,1005,1054,1092,1093,1095)
AND id <= 128384713 ORDER BY id DESC LIMIT 0, 11 \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: feed
partitions: NULL
type: range
possible_keys: PRIMARY,feed_user_target
key: feed_user_target
key_len: 6
ref: NULL
rows: 18
filtered: 50.00
Extra: Using where; Using index; Using filesort
1 row in set, 1 warning (0.00 sec)同じ SQL ステートメントの場合、データ量が大幅に変化すると、MySQL クエリ オプティマイザーのインデックス選択も変化します。
mysql> explain SELECT * FROM `feed` WHERE user_id IN (116537309,116709093,116709377)
AND cid IN (1001,1005,1054,1092,1093,1095)
AND id <= 128384713 ORDER BY id DESC LIMIT 0, 11 \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: feed
type: range
possible_keys: PRIMARY,feed_user_target
key: PRIMARY
key_len: 4
ref: NULL
rows: 11873197
Extra: Using where
1 row in set (0.00 sec)そして、解決策は、強制インデックスを使用して、指定したインデックスをクエリオプティマイザーに強制的に使用することです。 これは Python 開発環境です。一般的な Python ORM には、インデックスの強制、インデックスの無視、およびユーザー インデックスのパラメータがあります。
explain SELECT * FROM `feed` force index (feed_user_target) WHERE user_id IN (116537309,116709093,116709377) ...
では、データの増加により、mysql オプティマイザーが非効率なインデックスを選択するこの問題を防ぐにはどうすればよいでしょうか?
この問題についていくつかの工場の DBA に質問しましたが、得られた答えは私たちの方法と同じでした。 この問題は、その後の遅いクエリによってのみ発見され、SQL ステートメントで強制インデックスを指定してインデックスの問題を解決します。 さらに、この種の問題は、システムのオンライン化の初期段階では回避されますが、多くの場合、ビジネス開発者は、トラブルを避けるために、初期段階では DBA のレビュー作業に協力しますが、後の段階では、問題ないと思いますが、MySQL クエリ事故が発生します。
私自身、MySQL オプティマイザーのインデックス選択ルールについてはほとんど知らないので、後で時間をかけて勉強する予定です
上記は、オンライン MySQL オプティマイザーの誤った判断によって引き起こされるスロークエリイベントの内容です。コンテンツについては、PHP 中国語 Web サイト (www.php.cn) をフォローしてください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



