

AndroidのXML解析技術実装の詳細説明(写真)

この記事では、Android プラットフォームで XML を解析する 3 つの方法を紹介します。
XML はさまざまな開発で広く使用されており、Android も例外ではありません。データを運ぶ重要な役割として、XML の読み書き方法は Android 開発における重要なスキルとなっています。
Android で一般的な XML パーサーは、DOM パーサー、SAX パーサー、PULL パーサーです。以下、それぞれを詳しく紹介します。
最初の方法: DOM パーサー:
DOM はツリー構造に基づくノードまたは情報フラグメントのコレクションであり、開発者は DOM API を使用して XML ツリーを走査し、必要なデータ。この構造を分析するには、通常、ノード情報を取得して更新する前に、ドキュメント全体をロードし、ツリー構造を構築する必要があります。 Android は DOM 解析を完全にサポートしています。 DOM 内のオブジェクトを使用して、XML ドキュメントの読み取り、検索、変更、追加、削除を行うことができます。
DOM の仕組み: DOM を使用して XML ファイルを操作する場合、まずファイルを解析し、ファイルを独立した要素、属性、コメントなどに分割し、次に XML をメモリ内のフォームで処理する必要があります。ファイルを表すことにより、ノード ツリーを通じてドキュメントのコンテンツにアクセスし、必要に応じてドキュメントを変更できます。これが DOM の仕組みです。
DOM 実装では、まず XML ドキュメントを解析するための一連のインターフェイスが定義され、パーサーはドキュメント全体を読み取り、次にメモリ常駐のツリー構造を構築します。これにより、コードは DOM インターフェイスを使用してツリー構造全体を操作できます。 。
DOMはメモリ上にツリー構造で格納されるため、検索や更新の効率が高くなります。ただし、特に大きなドキュメントの場合、ドキュメント全体を解析してロードするとリソースが大量に消費されます。もちろん、XML ファイルの内容が比較的小さい場合は、DOM を使用することが可能です。
一般的に使用される DoM インターフェイスとクラス:
Document: このインターフェイスは、DOM ドキュメントを分析および作成するための一連のメソッドを定義します。これは、ドキュメント ツリーのルートであり、DOM を操作するための基礎です。
Element: このインターフェイスは Node インターフェイスを継承し、XML 要素の名前と属性を取得および変更するメソッドを提供します。
Node: このインターフェースは、ノードと子ノードの値を処理および取得するメソッドを提供します。
NodeList: ノードの数と現在のノードを取得するメソッドを提供します。これにより、個々のノードに繰り返しアクセスできるようになります。
DOMParser: このクラスは、XML ファイルを直接解析できる Apache の Xerces の DOM パーサー クラスです。
以下は DOM 解析プロセスです:

2 番目の方法: SAX パーサー:
API XML 用) パーサーは、イベントベースのパーサーです。イベント駆動型のストリーミング解析方法では、一時停止や巻き戻しをせずに、ファイルの先頭からドキュメントの末尾まで順番に解析します。その核となるのはイベント処理モデルで、主にイベント ソースとイベント プロセッサーを中心に動作します。イベントソースがイベントを生成すると、イベントプロセッサの対応する処理メソッドを呼び出すことでイベントを処理できます。イベント ソースがイベント ハンドラーの特定のメソッドを呼び出すときは、イベント ハンドラーが提供されたイベント情報に基づいて独自の動作を決定できるように、対応するイベントのステータス情報もイベント ハンドラーに渡す必要があります。
SAX パーサーの利点は、解析速度が速く、メモリの使用量が少ないことです。 Androidモバイルデバイスでの使用に最適です。
SAX の動作原理: SAX の動作原理は、スキャンがドキュメントの先頭と末尾、要素の先頭と末尾、ドキュメントの末尾に達すると、ドキュメントを順番にスキャンすることです。文書が保存されるとイベント処理関数に通知され、イベント処理関数は対応するアクションを実行し、文書の最後まで同じスキャンを続けます。
SAX インターフェイスでは、イベント ソースは org.xml.sax パッケージ内の XMLReader であり、parser() メソッドを通じて XML ドキュメントを解析し、イベントを生成します。イベント ハンドラーは、org.xml.sax パッケージ内の 4 つのインターフェイス ContentHander、DTDHander、ErrorHandler、および EntityResolver です。 XMLReader は、対応するイベント ハンドラー登録メソッド setXXXX() を通じて、ContentHander、DTDHander、ErrorHandler、および EntityResolver の 4 つのインターフェイスとの接続を完了します。
一般的に使用される SAX インターフェイスとクラス: 属性: 属性の番号、名前、値を取得するために使用されます。 ContentHandler: ドキュメント自体に関連付けられたイベント (開始タグと終了タグなど) を定義します。ほとんどのアプリケーションはこれらのイベントに登録します。 DTDHandler: DTD に関連付けられたイベントを定義します。 DTD を完全にレポートするのに十分なイベントが定義されていません。 DTD の解析が必要な場合は、オプションの DeclHandler を使用します。 DeclHandler は SAX の拡張機能です。すべてのパーサーがこれをサポートしているわけではありません。 EntityResolver: エンティティの読み込みに関連付けられたイベントを定義します。これらのイベントに登録するアプリケーションはわずかです。 ErrorHandler: エラー イベントを定義します。多くのアプリケーションはこれらのイベントを登録して、独自の方法でエラーを報告します。 DefaultHandler: これらのインターフェイスのデフォルトの実装を提供します。ほとんどの場合、アプリケーションはインターフェイスを直接実装するよりも、DefaultHandler を拡張して関連メソッドをオーバーライドする方が簡単です。 詳細については、以下の表を参照してください: Reader と DefaultHandler が連携して XML を解析します。 以下は SAX 解析プロセスです: 
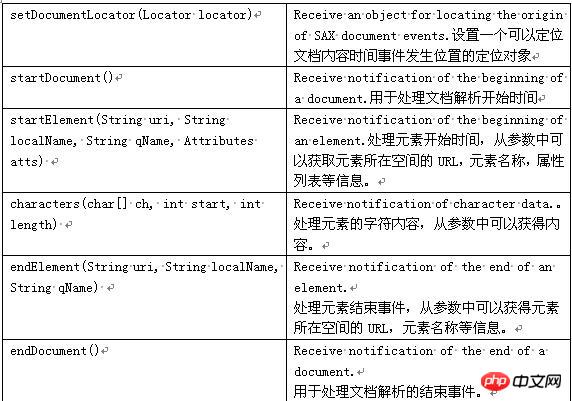

3 番目の方法: PULL パーサー:
Android は Java StAX をサポートしていませんAPIのサポート。ただし、Android には StAX と同様に機能するプル パーサーが付属しています。これにより、SAX パーサーが自動的にイベントをハンドラーにプッシュするのではなく、ユーザーのアプリケーション コードがパーサーからイベントを取得できるようになります。
PULL パーサーは SAX と同様に動作し、どちらもイベントベースです。違いは、プロセッサがイベントをトリガーしてコードを実行する SAX とは異なり、PULL 解析プロセス中に数値が返されるため、生成されたイベントを自分で取得して対応する操作を実行する必要があることです。
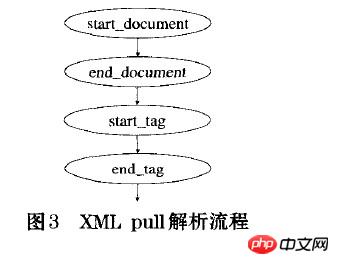
XML を PULL 解析するプロセスは次のとおりです:
XML の宣言を読み取ると START_DOCUMENT が返されます。
XML の読み取りが終了すると END_DOCUMENT が返されます。
XML の読み取り開始タグは START_TAG を返します
XML に読み込まれた終了タグは END_TAG を返します
XML に読み込まれたテキストは TEXT を返します
PULL パーサーは小さくて軽量で、解析速度が速い速いですシンプルで使いやすく、Android モバイル デバイスでの使用に非常に適しています。Android システムでは、さまざまな XML を解析するときに PULL パーサーも使用されます。Android では、開発者にプル解析テクノロジを使用することを公式に推奨しています。プル解析技術はサードパーティが開発したオープンソース技術であり、JavaSE開発にも応用できます。
PULL の仕組み: XML プルでは開始要素と終了要素が提供されます。要素が開始されると、パーサーを呼び出すことができます。 nextText は、XML ドキュメントからすべての文字データを抽出します。ドキュメントの解釈が終了すると、EndDocument イベントが自動的に生成されます。 一般的に使用される XML プル インターフェイスとクラス:XmlPullParser: XML プル パーサーは、XMLPULL VlAP1 で定義解析機能を提供するインターフェイスです。
XmlSerializer: XML 情報セットのシーケンスを定義するインターフェイスです。
XmlPullParserFactory: このクラスは、XMPULL V1 API で XML プル パーサーを作成するために使用されます。
XmlPullParserException: 単一の XML プル パーサー関連エラーをスローします。
PULL の解析プロセスは次のとおりです:
[追加] 4 番目の方法: Android.util.Xml クラス
Android APIでは、 Androidも提供しています。ユーティリティ。 XML クラスは XML ファイルを解析することもできます。使用方法は SAX と似ています。XML 解析を処理するためのハンドラーを作成する必要もありますが、以下に示すように SAX よりも簡単に使用できます。ユーティリティ。 XML は XML 解析、
MyHandler myHandler=new MyHandler0;
android を実装します。ユーティリティ。 Xm1. parse(ur1.openC0nnection().getlnputStream0, アセット
ディレクトリ
.は次のとおりです:
<?xml version="1.0" encoding="utf-8"?> <rivers> <river name="灵渠" length="605"> <introduction>
</
introduction
>
<
imageurl
>
http://www.php.cn/
</
imageurl
>
</
river
>
<
river
name
="胶莱运河"
length
="200"
>
<
introduction
>
胶莱运河南起黄海灵山海口,北抵渤海三山岛,流经现胶南、胶州、平度、高密、昌邑和莱州等,全长200公里,流域面积达5400平方公里,南北贯穿山东半岛,沟通黄渤两海。胶莱运河自平度姚家村东的分水岭南北分流。南流由麻湾口入胶州湾,为南胶莱河,长30公里。北流由海仓口入莱州湾,为北胶莱河,长100余公里。
</
introduction
>
<
imageurl
>
http://www.php.cn/
</
imageurl
>
</
river
>
<
river
name
="苏北灌溉总渠"
length
="168"
>
<
introduction
>
位于淮河下游江苏省北部,西起洪泽湖边的高良涧,流经洪泽,青浦、淮安,阜宁、射阳,滨海等六县(区),东至扁担港口入海的大型人工河道。全长168km。
</
introduction
>
<
imageurl
>
http://www.php.cn/
</
imageurl
>
</
river
>
</
rivers
>
采用DOM解析时具体处理步骤是:
1 首先利用DocumentBuilderFactory创建一个DocumentBuilderFactory实例
2 然后利用DocumentBuilderFactory创建DocumentBuilder
3 然后加载XML文档(Document),
4 然后获取文档的根结点(Element),
5 然后获取根结点中所有子节点的列表(NodeList),
6 然后使用再获取子节点列表中的需要读取的结点。
当然我们观察节点,我需要用一个River对象来保存数据,抽象出River类
public class River implements Serializable {
privatestaticfinallong serialVersionUID = 1L;
private String name;
public String getName() {
return name; }
public void setName(String name) {
this.name = name; }
public int getLength() {
return length; }
public void setLength(int length) {
this.length = length; }
public String getIntroduction() {
return introduction; }
public void setIntroduction(String introduction) {
this.introduction = introduction; }
public String getImageurl() {
return imageurl; }
public void setImageurl(String imageurl) {
this.imageurl = imageurl; }
private int length;
private String introduction;
private String imageurl; }下面我们就开始读取xml文档对象,并添加进List中:
代码如下: 我们这里是使用assets中的river.xml文件,那么就需要读取这个xml文件,返回输入流。 读取方法为:inputStream=this.context.getResources().getAssets().open(fileName); 参数是xml文件路径,当然默认的是assets目录为根目录。
然后可以用DocumentBuilder对象的parse方法解析输入流,并返回document对象,然后再遍历doument对象的节点属性。
//获取全部河流数据
/**
* 参数fileName:为xml文档路径
*/
public List<River> getRiversFromXml(String fileName){
List<River> rivers=new ArrayList<River>();
DocumentBuilderFactory factory=null;
DocumentBuilder builder=null;
Document document=null;
InputStream inputStream=null;
//首先找到xml文件
factory=DocumentBuilderFactory.newInstance();
try {
//找到xml,并加载文档
builder=factory.newDocumentBuilder();
inputStream=this.context.getResources().getAssets().open(fileName);
document=builder.parse(inputStream);
//找到根Element
Element root=document.getDocumentElement();
NodeList nodes=root.getElementsByTagName(RIVER);
//遍历根节点所有子节点,rivers 下所有river
River river=null;
for(int i=0;i<nodes.getLength();i++){
river=new River();
//获取river元素节点
Element riverElement=(Element)(nodes.item(i));
//获取river中name属性值
river.setName(riverElement.getAttribute(NAME));
river.setLength(Integer.parseInt(riverElement.getAttribute(LENGTH)));
//获取river下introduction标签
Element introduction=(Element)riverElement.getElementsByTagName(INTRODUCTION).item(0);
river.setIntroduction(introduction.getFirstChild().getNodeValue());
Element imageUrl=(Element)riverElement.getElementsByTagName(IMAGEURL).item(0);
river.setImageurl(imageUrl.getFirstChild().getNodeValue());
rivers.add(river);
}
}catch (IOException e){
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
}
catch (ParserConfigurationException e) {
e.printStackTrace();
}finally{
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return rivers;
}
在这里添加到List中, 然后我们使用ListView将他们显示出来。如图所示:
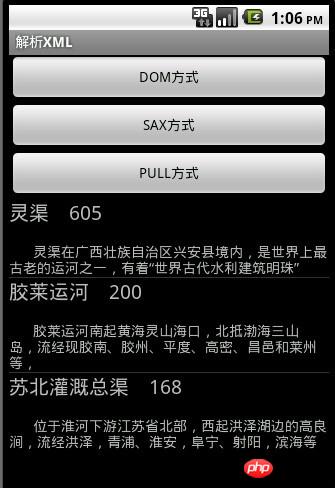
采用SAX解析时具体处理步骤是:
1 创建SAXParserFactory对象
2 根据SAXParserFactory.newSAXParser()方法返回一个SAXParser解析器
3 根据SAXParser解析器获取事件源对象XMLReader
4 实例化一个DefaultHandler对象
5 连接事件源对象XMLReader到事件处理类DefaultHandler中
6 调用XMLReader的parse方法从输入源中获取到的xml数据
7 通过DefaultHandler返回我们需要的数据集合。
代码如下:
public List<River> parse(String xmlPath){
List<River> rivers=null;
SAXParserFactory factory=SAXParserFactory.newInstance();
try {
SAXParser parser=factory.newSAXParser();
//获取事件源
XMLReader xmlReader=parser.getXMLReader();
//设置处理器
RiverHandler handler=new RiverHandler();
xmlReader.setContentHandler(handler);
//解析xml文档
//xmlReader.parse(new InputSource(new URL(xmlPath).openStream()));
xmlReader.parse(new InputSource(this.context.getAssets().open(xmlPath)));
rivers=handler.getRivers();
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return rivers;
}
重点在于DefaultHandler对象中对每一个元素节点,属性,文本内容,文档内容进行处理。
前面说过DefaultHandler是基于事件处理模型的,基本处理方式是:当SAX解析器导航到文档开始标签时回调startDocument方法,导航到文档结束标签时回调endDocument方法。当SAX解析器导航到元素开始标签时回调startElement方法,导航到其文本内容时回调characters方法,导航到标签结束时回调endElement方法。
根据以上的解释,我们可以得出以下处理xml文档逻辑:
1:当导航到文档开始标签时,在回调函数startDocument中,可以不做处理,当然你可以验证下UTF-8等等。
2:当导航到rivers开始标签时,在回调方法startElement中可以实例化一个集合用来存贮list,不过我们这里不用,因为在构造函数中已经实例化了。
3:导航到river开始标签时,就说明需要实例化River对象了,当然river标签中还有name ,length属性,因此实例化River后还必须取出属性值,attributes.getValue(NAME),同时赋予river对象中,同时添加为导航到的river标签添加一个boolean为真的标识,用来说明导航到了river元素。
4:当然有river标签内还有子标签(节点),但是SAX解析器是不知道导航到什么标签的,它只懂得开始,结束而已。那么如何让它认得我们的各个标签呢?当然需要判断了,于是可以使用回调方法startElement中的参数String localName,把我们的标签字符串与这个参数比较下,就可以了。我们还必须让SAX知道,现在导航到的是某个标签,因此添加一个true属性让SAX解析器知道。
5:它还会导航到文本内标签,(就是里面的内容),回调方法characters,我们一般在这个方法中取出就是
里面的内容,并保存。 6:当然它是一定会导航到结束标签 或者的,如果是标签,记得把river对象添加进list中。如果是river中的子标签,就把前面设置标记导航到这个标签的boolean标记设置为false. 按照以上实现思路,可以实现如下代码:
/**导航到开始标签触发**/
publicvoid startElement (String uri, String localName, String qName, Attributes attributes){
String tagName=localName.length()!=0?localName:qName;
tagName=tagName.toLowerCase().trim();
//如果读取的是river标签开始,则实例化River
if(tagName.equals(RIVER)){
isRiver=true;
river=new River();
/**导航到river开始节点后**/
river.setName(attributes.getValue(NAME));
river.setLength(Integer.parseInt(attributes.getValue(LENGTH)));
}
//然后读取其他节点
if(isRiver){
if(tagName.equals(INTRODUCTION)){
xintroduction=true;
}else if(tagName.equals(IMAGEURL)){
ximageurl=true;
}
}
}
/**导航到结束标签触发**/
public void endElement (String uri, String localName, String qName){
String tagName=localName.length()!=0?localName:qName;
tagName=tagName.toLowerCase().trim();
//如果读取的是river标签结束,则把River添加进集合中
if(tagName.equals(RIVER)){
isRiver=true;
rivers.add(river);
}
//然后读取其他节点
if(isRiver){
if(tagName.equals(INTRODUCTION)){
xintroduction=false;
}else if(tagName.equals(IMAGEURL)){
ximageurl=false;
}
}
}
//这里是读取到节点内容时候回调
public void characters (char[] ch, int start, int length){
//设置属性值
if(xintroduction){
//解决null问题
river.setIntroduction(river.getIntroduction()==null?"":river.getIntroduction()+new String(ch,start,length));
}else if(ximageurl){
//解决null问题
river.setImageurl(river.getImageurl()==null?"":river.getImageurl()+new String(ch,start,length));
}
}
运行效果跟上例DOM 运行效果相同。
采用PULL解析基本处理方式:
当PULL解析器导航到文档开始标签时就开始实例化list集合用来存贮数据对象。导航到元素开始标签时回判断元素标签类型,如果是river标签,则需要实例化River对象了,如果是其他类型,则取得该标签内容并赋予River对象。当然它也会导航到文本标签,不过在这里,我们可以不用。
根据以上的解释,我们可以得出以下处理xml文档逻辑:
1:当导航到XmlPullParser.START_DOCUMENT,可以不做处理,当然你可以实例化集合对象等等。
2:当导航到XmlPullParser.START_TAG,则判断是否是river标签,如果是,则实例化river对象,并调用getAttributeValue方法获取标签中属性值。
3:当导航到其他标签,比如Introduction时候,则判断river对象是否为空,如不为空,则取出Introduction中的内容,nextText方法来获取文本节点内容
4:当然啦,它一定会导航到XmlPullParser.END_TAG的,有开始就要有结束嘛。在这里我们就需要判读是否是river结束标签,如果是,则把river对象存进list集合中了,并设置river对象为null.
由以上的处理逻辑,我们可以得出以下代码:
public List<River> parse(String xmlPath){
List<River> rivers=new ArrayList<River>();
River river=null;
InputStream inputStream=null;
//获得XmlPullParser解析器
XmlPullParser xmlParser = Xml.newPullParser();
try {
//得到文件流,并设置编码方式
inputStream=this.context.getResources().getAssets().open(xmlPath);
xmlParser.setInput(inputStream, "utf-8");
//获得解析到的事件类别,这里有开始文档,结束文档,开始标签,结束标签,文本等等事件。
int evtType=xmlParser.getEventType();
//一直循环,直到文档结束
while(evtType!=XmlPullParser.END_DOCUMENT){
switch(evtType){
case XmlPullParser.START_TAG:
String tag = xmlParser.getName();
//如果是river标签开始,则说明需要实例化对象了
if (tag.equalsIgnoreCase(RIVER)) {
river = new River();
//取出river标签中的一些属性值
river.setName(xmlParser.getAttributeValue(null, NAME));
river.setLength(Integer.parseInt(xmlParser.getAttributeValue(null, LENGTH)));
}else if(river!=null){
//如果遇到introduction标签,则读取它内容
if(tag.equalsIgnoreCase(INTRODUCTION)){
river.setIntroduction(xmlParser.nextText());
}else if(tag.equalsIgnoreCase(IMAGEURL)){
river.setImageurl(xmlParser.nextText());
}
}
break;
case XmlPullParser.END_TAG:
//如果遇到river标签结束,则把river对象添加进集合中
if (xmlParser.getName().equalsIgnoreCase(RIVER) && river != null) {
rivers.add(river);
river = null;
}
break;
default:break;
}
//如果xml没有结束,则导航到下一个river节点
evtType=xmlParser.next();
}
} catch (XmlPullParserException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
return rivers;
}运行效果和上面的一样。
几种解析技术的比较与总结:
对于Android的移动设备而言,因为设备的资源比较宝贵,内存是有限的,所以我们需要选择适合的技术来解析XML,这样有利于提高访问的速度。
1 DOM在处理XML文件时,将XML文件解析成树状结构并放入内存中进行处理。当XML文件较小时,我们可以选DOM,因为它简单、直观。
2 SAX则是以事件作为解析XML文件的模式,它将XML文件转化成一系列的事件,由不同的事件处理器来决定如何处理。XML文件较大时,选择SAX技术是比较合理的。虽然代码量有些大,但是它不需要将所有的XML文件加载到内存中。这样对于有限的Android内存更有效,而且Android提供了一种传统的SAX使用方法以及一个便捷的SAX包装器。 使用Android.util.Xml类,从示例中可以看出,会比使用 SAX来得简单。
3 XML pull解析并未像SAX解析那样监听元素的结束,而是在开始处完成了大部分处理。这有利于提早读取XML文件,可以极大的减少解析时间,这种优化对于连接速度较漫的移动设备而言尤为重要。对于XML文档较大但只需要文档的一部分时,XML Pull解析器则是更为有效的方法。
以上がAndroidのXML解析技術実装の詳細説明(写真)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7675
7675
 15
1393
52
1207
24
91
11
15
1393
52
1207
24
91
11

 新しいレポートは、噂のSamsung Galaxy S25、Galaxy S25 Plus、Galaxy S25 Ultraのカメラアップグレードのひどい評価を提供します
Sep 12, 2024 pm 12:23 PM
新しいレポートは、噂のSamsung Galaxy S25、Galaxy S25 Plus、Galaxy S25 Ultraのカメラアップグレードのひどい評価を提供します
Sep 12, 2024 pm 12:23 PM
ここ数日、Ice Universeは、サムスンの次期主力スマートフォンであると広く信じられているGalaxy S25 Ultraの詳細を着実に明らかにしている。とりわけ、リーカーはサムスンがカメラのアップグレードを1つだけ計画していると主張した
 Samsung Galaxy S25 Ultraの最初のレンダリング画像がリークされ、噂のデザイン変更が明らかに
Sep 11, 2024 am 06:37 AM
Samsung Galaxy S25 Ultraの最初のレンダリング画像がリークされ、噂のデザイン変更が明らかに
Sep 11, 2024 am 06:37 AM
OnLeaks は、X (旧 Twitter) のフォロワーから 4,000 ドル以上を集めようとして失敗した数日後、Android Headlines と提携して Galaxy S25 Ultra のファーストルックを提供しました。コンテキストとして、h の下に埋め込まれたレンダリング イメージ
 Samsung Galaxy S24 FEは、4色と2つのメモリオプションで予想よりも低価格で発売されると請求されています
Sep 12, 2024 pm 09:21 PM
Samsung Galaxy S24 FEは、4色と2つのメモリオプションで予想よりも低価格で発売されると請求されています
Sep 12, 2024 pm 09:21 PM
サムスンは、ファンエディション(FE)スマートフォンシリーズをいつアップデートするかについて、まだ何のヒントも提供していない。現時点では、Galaxy S23 FE は 2023 年 10 月初めに発表された同社の最新版のままです。
 新しいレポートは、噂のSamsung Galaxy S25、Galaxy S25 Plus、Galaxy S25 Ultraのカメラアップグレードのひどい評価を提供します
Sep 12, 2024 pm 12:22 PM
新しいレポートは、噂のSamsung Galaxy S25、Galaxy S25 Plus、Galaxy S25 Ultraのカメラアップグレードのひどい評価を提供します
Sep 12, 2024 pm 12:22 PM
ここ数日、Ice Universeは、サムスンの次期主力スマートフォンであると広く信じられているGalaxy S25 Ultraの詳細を着実に明らかにしている。とりわけ、リーカーはサムスンがカメラのアップグレードを1つだけ計画していると主張した
 Xiaomi Redmi Note 14 Pro Plusは、Light Hunter 800カメラを搭載した初のQualcomm Snapdragon 7s Gen 3スマートフォンとして登場します
Sep 27, 2024 am 06:23 AM
Xiaomi Redmi Note 14 Pro Plusは、Light Hunter 800カメラを搭載した初のQualcomm Snapdragon 7s Gen 3スマートフォンとして登場します
Sep 27, 2024 am 06:23 AM
Redmi Note 14 Pro Plusは、昨年のRedmi Note 13 Pro Plus(Amazonで現在375ドル)の直接の後継者として正式に発表されました。予想通り、Redmi Note 14 Pro Plusは、Redmi Note 14およびRedmi Note 14 Proと並んでRedmi Note 14シリーズをリードします。李
 iQOO Z9 Turbo Plus: 強化されたシリーズフラッグシップの予約開始
Sep 10, 2024 am 06:45 AM
iQOO Z9 Turbo Plus: 強化されたシリーズフラッグシップの予約開始
Sep 10, 2024 am 06:45 AM
OnePlus の姉妹ブランドである iQOO の製品サイクルは 2023 年から 4 年で、ほぼ終わりに近づいている可能性があります。それにもかかわらず、ブランドはまだZ9シリーズの開発を終えていないと宣言しました。その最終、そしておそらく最高エンドとなる Turbo+ バリアントが、予測どおりに発表されました。 T
 Motorola Razr 50s は初期リークで新たな予算を折り畳める可能性があることを示す
Sep 07, 2024 am 09:35 AM
Motorola Razr 50s は初期リークで新たな予算を折り畳める可能性があることを示す
Sep 07, 2024 am 09:35 AM
Motorola は今年数え切れないほどのデバイスをリリースしましたが、そのうち折りたたみ式デバイスは 2 つだけです。ちなみに、世界の大部分ではこのペアが Razr 50 および Razr 50 Ultra として受け入れられていますが、Motorola は北米では Razr 2024 および Razr 2 として提供しています。
 IFA 2024 | AGM Pad P2 Active は、Android 14 を搭載したコンバーチブルで頑丈なタブレットとしてデビューします
Sep 08, 2024 am 06:30 AM
IFA 2024 | AGM Pad P2 Active は、Android 14 を搭載したコンバーチブルで頑丈なタブレットとしてデビューします
Sep 08, 2024 am 06:30 AM
AGM Mobile は、IFA 2024 に来て、最新のタブレットとして、初めて黒とオレンジの強化筐体を備えた Pad P2 Active を発表しました。 360°回転するフリップアウトリングが、屋外でのキックスタンドハンドルとして機能するため、屋外での作業に適していると評判です。
