

Java例外モデルの詳細な紹介と分析(図)

1. 例外の概要と基本
エラーを見つけるのに最適な時期は、コンパイル段階中、つまりプログラムを実行しようとする前です。ただし、コンパイラーはコンパイル中にすべてのエラーを検出することはできません。残りのエラーは実行時にのみ検出および解決できます。このタイプのエラーは です。 これには、エラーのソースが何らかの方法で適切な情報を受信者に渡す必要があり、受信者は問題を正しく処理する方法を知ることができます。これが Java の エラー報告 メカニズム、つまり例外メカニズムです。このメカニズムにより、プログラムは、通常の実行中に が行うことを示すコード と、何か問題が発生した場合の動作を示すコード を分離することができます 。
例外処理に関して、Javaは終了モデルを採用しています。 このモデルでは、エラーが非常に重大であるため、プログラムが例外が発生した時点に戻って実行を続行できないと想定されます。例外がスローされると、エラーが元に戻せないため、実行を続行できないことを示します。 終了モデルと比較して、もう 1 つの 例外処理 モデルは 回復モデル です。これにより、例外が処理された後もプログラムの実行を継続できます。このモデルは魅力的ではありますが、主にそれが引き起こす結合のため、あまり実用的ではありません。回復ハンドラーは例外がスローされた場所を知る必要があり、例外には例外がスローされた場所に依存する非汎用コードが含まれるため、処理速度が大幅に増加します。コードの作成とメンテナンスの難しさ。
例外状況では、例外のスローには次の 3 つのことが伴います:
1.
基本概念
例外クラス階層の例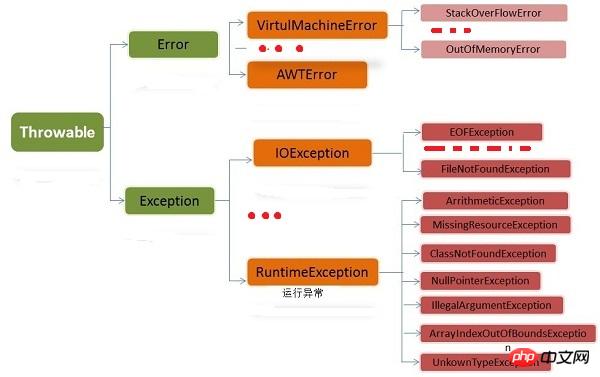
- Throwable: すべての例外タイプのルートクラス
Javaでは、Throwableがすべての例外タイプのルートクラスです。
Throwable には、Exception と Error という 2 つの直接サブクラスがあります。どちらも Java 例外処理の重要なサブクラスであり、それぞれに多数のサブクラスが含まれています。
- エラー: プログラム自体では処理できないエラーです
エラーは、プログラムでは処理できないエラーであり、アプリケーションの実行に重大な問題があることを示します。
これらのエラーのほとんどは、コード作成者が実行する操作とは関係ありませんが、コードの実行時の JVM、リソースなどに関連しています。たとえば、Java 仮想マシン ランタイム エラー (仮想マシンエラー)、OutOfMemoryError は、JVM に操作の実行を継続するために必要なメモリ リソースがなくなったときに発生します。これらの例外が発生すると、Java 仮想マシン (JVM) は通常、スレッドを終了することを選択します。 これらのエラーはチェックできず、アプリケーションの制御および処理能力の範囲外にあります。 Java では、エラーは Error のサブクラスを通じて記述されます。
例外: プログラム自体が処理できるエラー例外は通常 Java プログラマーにとって懸念事項であり、Javaクラス ライブラリ、ユーザー メソッド、および実行時のエラーでスローされる可能性があります。これは、 ランタイム例外 (RuntimeException から派生した例外) と その他の例外 の 2 つのブランチで構成されます。 これら 2 種類の例外を分けるルールは次のとおりです。プログラム エラーによって引き起こされる例外 (一般に、誤った 型変換、配列クロスボーダーなどの論理エラーは避けるべきです) は RuntimeException に属します。プログラム自体には問題はありませんが、I/O などのエラーによる例外 (存在しないファイルを開こうとした場合など) も例外となります。
また、Javaの例外(Exception、Errorを含む)は、通常、チェック例外(チェック例外)とアンチェック例外(チェックされていない例外)の2種類に分けられます。
-
未チェック例外: Error または RuntimeException から派生するすべての例外
未チェック例外とは、ランタイム例外 (RuntimeException とそのサブクラス) とエラー (Error) を含む、コンパイラーが を処理する必要のない例外です。つまり、プログラム内でそのような例外が発生する可能性がある場合、たとえ try-catch ステートメントでキャッチされなくても、throws 節を使用してスローされるように宣言されていても、コンパイラはパスします。
-
チェック例外: 非チェック例外を除くすべての例外
チェック例外は、コンパイラが処理する必要がある例外です。 ここで言及する処理方法には、 例外のキャッチと処理 と の宣言 例外のスロー の 2 つの処理方法があります。つまり、プログラム内でそのような例外が発生する可能性がある場合は、try-catch ステートメントを使用して例外をキャッチするか、throws 節を使用して例外をスローすることを宣言します。そうしないと、コンパイルは通過しません。
ガイドライン: プログラム内で RuntimeException が発生した場合、それはプログラマの問題であるに違いありません
例外とエラーの違い: 例外はプログラム自体で処理できますが、エラーは処理できませんbe handle
3. Java 例外処理メカニズム
-
例外処理
Java アプリケーションにおける例外処理メカニズムは、例外をスローすると例外をキャッチするです。
例外がスローされる: メソッドでエラーが発生し、例外がスローされると、メソッドは例外オブジェクトを作成し、それをランタイム システムに渡します。例外オブジェクトには、例外の種類や実行時のプログラムのステータスなどの例外情報が含まれます。例外が発生します。ランタイム システムは、例外を処理するコードを見つけて実行する責任があります。例外をキャッチする: メソッドが例外をスローした後、ランタイム システムは適切な例外ハンドラー (例外 handler) を見つけます。 潜在的な例外ハンドラーは、例外が発生したときに呼び出しスタックに順番に残るメソッドのコレクションです。 例外ハンドラーが処理できる例外の種類が、メソッドによってスローされる例外の種類と一致する場合、それは適切な例外ハンドラーです。 ランタイム システムは、例外が発生したメソッドから開始し、適切な例外ハンドラーを含むメソッドを見つけて実行するまで、コール スタック内のメソッドをチェックバックします。ランタイム システムが適切な例外ハンドラーを見つけずにコール スタックを走査すると、ランタイム システムは終了します。それは同時にJavaプログラムの終了を意味します。
実行時例外、エラー、またはチェック例外の場合、Java テクノロジーで必要とされる例外処理メソッドは異なります:
実行時例外はチェックされていないため、Java 規則: 実行時例外は自動的にスローされますJava ランタイム システムによって、アプリケーションがランタイム例外を無視できるようになります。
メソッドの実行中に発生する可能性のあるエラー-
について、実行中のメソッドがキャッチしたくない場合、Java はメソッドが例外を無視できるようにします。投げる宣言をしないでください。ほとんどのエラーは回復不可能であり、合理的なアプリケーションがキャッチすべきではない例外であるため、すべてのチェックされた例外について、Java は例外をキャッチするか説明する必要があると規定しています。つまり、メソッドがチェック可能な例外をキャッチしないことを選択した場合、例外をスローすることを宣言する必要があります
。自分で書いたコード、Java 開発環境パッケージ、または Java ランタイム システムからのコードなど、すべての Java コードが例外をスローする可能性があります。誰でも Java の throw ステートメントを通じて例外をスローできます。
一般に、Java ではチェック可能な例外をキャッチするか、スローするように宣言する必要があると規定されています。チェックできない RuntimeException および Error を無視できるようにします。
2. 例外の説明
チェック例外の場合、Javaは、メソッドがスローする可能性のある例外のタイプをクライアントプログラマに通知できるようにする対応する構文を提供します。それに応じて。これは、メソッド宣言の一部であり、次のコードに示すように、仮パラメーター リストの直後にある 例外の説明です:
void f() throws TooBig, TooSmall, pZero { ... }void g() { ... ... }コードは例外の説明と一致している必要があります。 メソッド内のコードがチェック例外を生成してもそれを処理しない場合、コンパイラーはこの問題を検出し、例外を処理するか、例外の説明でこのメソッドが例外を生成することを示すように通知します。 ただし、実際に例外をスローしなくても、メソッドが例外をスローすることを宣言できます。
3. 例外をキャッチする
監視領域: 例外を生成する可能性のあるコードの一部であり、これらの例外を処理するコードが続きます。これは、try…catch…句によって実装されます 。
(1) try句 メソッド内で例外がスローされた場合、このメソッドは例外をスローする過程で終了します。メソッドをここで終了したくない場合は、例外をキャッチするためにメソッド内に特別なブロックを設定できます。このブロックのうち、さまざまなメソッド呼び出しを試す部分を try ブロックと呼びます:
try {
// Code that might generate exceptions }(2) catch 句 – 例外ハンドラ
スローされた例外は処理されなければならず、キャッチされる例外ごとに、対応する例外ハンドラーを準備する必要があります。
例外ハンドラーは、catch キーワードで表される try ブロックのすぐ後に続く必要があります:
try {
// Code that might generate exceptions } catch(Type1 id1)|{
// Handle exceptions of Type1 } catch(Type2 id2) {
// Handle exceptions of Type2 } catch(Type3 id3) {
// Handle exceptions of Type3 }例外がスローされると、例外処理メカニズムは、パラメーターが例外タイプに一致する最初のハンドラーを検索する責任を負います。次に、対応する catch を入力し、自動的に実行します。この時点で、例外は処理されたものとみなされます。 catch 節が終了すると、ハンドラーの検索は終了します (switch…case… とは異なります)。
次の点に特別な注意を払う必要があります:
例外一致の原則: 例外がスローされると、例外処理システムは、コードが書かれた順序で最も近い一致を見つけます(オブジェクト派生クラスはその基本クラス (ハンドラー) と一致する可能性があります。例外が見つかると、例外が処理されるとみなして検索を停止します。
マスクできない派生クラス例外: 基本クラスの例外をキャッチする catch 句は、その派生クラスの例外をキャッチする catch 句の後に配置する必要があります。そうでない場合、コンパイルは通過しません。
catch 節は try 節 と一緒に使用する必要があります。
(3)
finally句
- finallyブロック説明
The finally block always executes when the try block exits. This ensures that the finally block is executed even if an unexpected exception occurs. But finally is useful for more than just exception handling — it allows the programmer to avoid having cleanup code accidentally bypassed by a return,continue, or break. Putting cleanup code in a finally block is always a good practice, even when no exceptions are anticipated.
Note: If the JVM exits while the try or catch code is being executed, then the finally block may not execute. Likewise, if the thread executing the try or catch code is interrupted or killed, the finally block may not execute even though the application as a whole continues.
finally 子句 总会被执行(前提:对应的 try子句 执行)
下面代码就没有执行 finally 子句:
public class Test {
public static void main(String[] args) {
System.out.println("return value of test(): " + test());
}
public static int test() {
int i = 1;
System.out.println("the previous statement of try block");
i = i / 0;
try {
System.out.println("try block");
return i;
}finally {
System.out.println("finally block");
}
}
}/* Output:
the previous statement of try block
Exception in thread "main" java.lang.ArithmeticException: / by zero
at com.bj.charlie.Test.test(Test.java:15)
at com.bj.charlie.Test.main(Test.java:6)
*///:~当代码抛出一个异常时,就会终止方法中剩余代码的执行,同时退出该方法的执行。如果该方法获得了一些本地资源,并且这些资源(eg:已经打开的文件或者网络连接等)在退出方法之前必须被回收,那么就会产生资源回收问题。这时,就会用到finally子句,示例如下:
InputStream in = new FileInputStream(...);try{
...
}catch (IOException e){
...
}finally{
in.close();
}finally 子句与控制转移语句的执行顺序
A finally clause can also be used to clean up for break, continue and return, which is one reason you will sometimes see a try clause with no catch clauses. When any control transfer statement is executed, all relevant finally clauses are executed. There is no way to leave a try block without executing its finally clause.
先看四段代码:
// 代码片段1
public class Test {
public static void main(String[] args) {
try {
System.out.println("try block");
return ;
} finally {
System.out.println("finally block");
}
}
}/* Output:
try block
finally block
*///:~// 代码片段2public class Test {
public static void main(String[] args) {
System.out.println("reture value of test() : " + test());
}
public static int test(){
int i = 1;
try {
System.out.println("try block");
i = 1 / 0;
return 1;
}catch (Exception e){
System.out.println("exception block");
return 2;
}finally {
System.out.println("finally block");
}
}
}/* Output:
try block
exception block
finally block
reture value of test() : 2
*///:~// 代码片段3public class ExceptionSilencer {
public static void main(String[] args) {
try {
throw new RuntimeException();
} finally {
// Using ‘return’ inside the finally block
// will silence any thrown exception.
return;
}
}
} ///:~// 代码片段4class VeryImportantException extends Exception {
public String toString() {return "A very important exception!"; }
}
class HoHumException extends Exception {
public String toString() {
return "A trivial exception";
}
}
public class LostMessage {
void f() throws VeryImportantException {
throw new VeryImportantException();
}
void dispose() throws HoHumException {
throw new HoHumException();
}
public static void main(String[] args) {
try {
LostMessage lm = new LostMessage();
try {
lm.f();
} finally {
lm.dispose();
}
} catch(Exception e) {
System.out.println(e);
}
}
} /* Output:
A trivial exception
*///:~从上面的四个代码片段,我们可以看出,finally子句 是在 try 或者 catch 中的 return 语句之前执行的。更加一般的说法是,finally子句 应该是在控制转移语句之前执行,控制转移语句除了 return 外,还有 break 和 continue。另外,throw 语句也属于控制转移语句。虽然 return、throw、break 和 continue 都是控制转移语句,但是它们之间是有区别的。其中 return 和 throw 把程序控制权转交给它们的调用者(invoker),而 break 和 continue 的控制权是在当前方法内转移。
下面,再看两个代码片段:
// 代码片段5public class Test {
public static void main(String[] args) {
System.out.println("return value of getValue(): " + getValue());
}
public static int getValue() {
try {
return 0;
} finally {
return 1;
}
}
}/* Output:
return value of getValue(): 1
*///:~// 代码片段6public class Test {
public static void main(String[] args) {
System.out.println("return value of getValue(): " + getValue());
}
public static int getValue() {
int i = 1;
try {
return i;
} finally {
i++;
}
}
}/* Output:
return value of getValue(): 1
*///:~ 利用我们上面分析得出的结论:finally子句 是在 try子句 或者 catch子句 中的 return 语句之前执行的。 由此,可以轻松的理解代码片段 5 的执行结果是 1。因为 finally 中的 return 1;语句要在 try 中的 return 0;语句之前执行,那么 finally 中的 return 1;语句执行后,把程序的控制权转交给了它的调用者 main()函数,并且返回值为 1。
那为什么代码片段 6 的返回值不是 2,而是 1 呢? 按照代码片段 5 的分析逻辑,finally 中的 i++;语句应该在 try 中的 return i;之前执行啊? i 的初始值为 1,那么执行 i++;之后为 2,再执行 return i;那不就应该是 2 吗?怎么变成 1 了呢?
关于 Java 虚拟机是如何编译 finally 子句的问题,有兴趣的读者可以参考《 The JavaTM Virtual Machine Specification, Second Edition 》中 7.13 节 Compiling finally。那里详细介绍了 Java 虚拟机是如何编译 finally 子句。实际上,Java 虚拟机会把 finally 子句作为 subroutine 直接插入到 try 子句或者 catch 子句的控制转移语句之前。但是,还有另外一个不可忽视的因素,那就是在执行 subroutine(也就是 finally 子句)之前,try 或者 catch 子句会保留其返回值到本地变量表(Local Variable Table)中。待 subroutine 执行完毕之后,再恢复保留的返回值到操作数栈中,然后通过 return 或者 throw 语句将其返回给该方法的调用者(invoker)。
请注意,前文中我们曾经提到过 return、throw 和 break、continue 的区别,对于这条规则(保留返回值),只适用于 return 和 throw 语句,不适用于 break 和 continue 语句,因为它们根本就没有返回值。
下面再看最后三个代码片段:
// 代码片段7public class Test {
public static void main(String[] args) {
System.out.println("return value of getValue(): " + getValue());
}
@SuppressWarnings("finally")
public static int getValue() {
int i = 1;
try {
i = 4;
} finally {
i++;
return i;
}
}
}/* Output:
return value of getValue(): 5
*///:~// 代码片段8public class Test {
public static void main(String[] args) {
System.out.println("return value of getValue(): " + getValue());
}
public static int getValue() {
int i = 1;
try {
i = 4;
} finally {
i++;
}
return i;
}
}/* Output:
return value of getValue(): 5
*///:~// 代码片段9public class Test {
public static void main(String[] args) {
System.out.println(test());
}
public static String test() {
try {
System.out.println("try block");
return test1();
} finally {
System.out.println("finally block");
}
}
public static String test1() {
System.out.println("return statement");
return "after return";
}
}/* Output:
try block
return statement
finally block
after return
*///:~请注意,最后个案例的唯一一个需要注意的地方就是,return test1(); 这条语句等同于 :
String tmp = test1(); return tmp;
因而会产生上述输出。
特别需要注意的是,在以下4种特殊情况下,finally子句不会被(完全)执行:
1)在 finally 语句块中发生了异常;
2)在前面的代码中用了 System.exit()【JVM虚拟机停止】退出程序;
3)程序所在的线程死亡;
4)关闭 CPU;
四. 异常的限制
当覆盖方法时,只能抛出在基类方法的异常说明里列出的那些异常。这意味着,当基类使用的代码应用到其派生类对象时,一样能够工作。
class BaseballException extends Exception {}
class Foul extends BaseballException {}
class Strike extends BaseballException {}
abstract class Inning {
public Inning() throws BaseballException {}
public void event() throws BaseballException {
// Doesn’t actually have to throw anything
}
public abstract void atBat() throws Strike, Foul;
public void walk() {} // Throws no checked exceptions }
class StormException extends Exception {}
class RainedOut extends StormException {}
class PopFoul extends Foul {}
interface Storm {
public void event() throws RainedOut;
public void rainHard() throws RainedOut;
}
public class StormyInning extends Inning implements Storm {
// OK to add new exceptions for constructors, but you must deal with the base constructor exceptions:
public StormyInning() throws RainedOut, BaseballException {}
public StormyInning(String s) throws Foul, BaseballException {}
// Regular methods must conform to base class:
void walk() throws PopFoul {} //Compile error
// Interface CANNOT add exceptions to existing methods from the base class:
public void event() throws RainedOut {}
// If the method doesn’t already exist in the base class, the exception is OK:
public void rainHard() throws RainedOut {}
// You can choose to not throw any exceptions, even if the base version does:
public void event() {}
// Overridden methods can throw inherited exceptions:
public void atBat() throws PopFoul {}
public static void main(String[] args) {
try {
StormyInning si = new StormyInning();
si.atBat();
} catch(PopFoul e) {
System.out.println("Pop foul");
} catch(RainedOut e) {
System.out.println("Rained out");
} catch(BaseballException e) {
System.out.println("Generic baseball exception");
}
// Strike not thrown in derived version.
try {
// What happens if you upcast? ----印证“编译器的类型检查是静态的,是针对引用的!!!”
Inning i = new StormyInning();
i.atBat();
// You must catch the exceptions from the base-class version of the method:
} catch(Strike e) {
System.out.println("Strike");
} catch(Foul e) {
System.out.println("Foul");
} catch(RainedOut e) {
System.out.println("Rained out");
} catch(BaseballException e) {
System.out.println("Generic baseball exception");
}
}
} ///:~异常限制对构造器不起作用
子类构造器不必理会基类构造器所抛出的异常。然而,因为基类构造器必须以这样或那样的方式被调用(这里默认构造器将自动被调用),派生类构造器的异常说明必须包含基类构造器的异常说明。
派生类构造器不能捕获基类构造器抛出的异常
因为 super() 必须位于子类构造器的第一行,而若要捕获父类构造器的异常的话,则第一行必须是 try 子句,这样会导致编译不会通过。
派生类所重写的方法抛出的异常列表不能大于父类该方法的异常列表,即前者必须是后者的子集
通过强制派生类遵守基类方法的异常说明,对象的可替换性得到了保证。需要指出的是,派生类方法可以不抛出任何异常,即使基类中对应方法具有异常说明。也就是说,一个出现在基类方法的异常说明中的异常,不一定会出现在派生类方法的异常说明里。
异常说明不是方法签名的一部分
尽管在继承过程中,编译器会对异常说明做强制要求,但异常说明本身并不属于方法类型的一部分,方法类型是由方法的名字及其参数列表组成。因此,不能基于异常说明来重载方法。
五. 自定义异常
使用Java内置的异常类可以描述在编程时出现的大部分异常情况。除此之外,用户还可以自定义异常。用户自定义异常类,只需继承Exception类即可。
在程序中使用自定义异常类,大体可分为以下几个步骤:
(1)创建自定义异常类;
(2)在方法中通过throw关键字抛出异常对象;
(3)如果在当前抛出异常的方法中处理异常,可以使用try-catch语句捕获并处理;否则在方法的声明处通过throws关键字指明要抛出给方法调用者的异常,继续进行下一步操作;
(4)在出现异常方法的调用者中捕获并处理异常。
六. 异常栈与异常链
1、栈轨迹
printStackTrace() 方法可以打印Throwable和Throwable的调用栈轨迹。调用栈显示了由异常抛出点向外扩散的所经过的所有方法,即方法调用序列(main方法 通常是方法调用序列中的最后一个)。
2、重新抛出异常
catch(Exception e) {
System.out.println("An exception was thrown");
throw e;
} 既然已经得到了对当前异常对象的引用,那么我们就可以像上面一样将其重新抛出。重新抛出的异常会把异常抛给上一级环境中的异常处理程序,同一个try子句的后续catch子句将被忽略。此外,如果只是把当前异常对象重新抛出,那么printStackTrace() 方法显示的仍是原来异常抛出点的调用栈信息,而并非重新抛出点的信息。要想更新这个信息,可以调用fillInStackTrace() 方法,这将返回一个Throwable对象,它是通过把当前调用栈信息填入原来那个异常对象而建立的。
看下面示例:
public class Rethrowing {
public static void f() throws Exception {
System.out.println("originating the exception in f()");
throw new Exception("thrown from f()");
}
public static void g() throws Exception {
try {
f();
} catch(Exception e) {
System.out.println("Inside g(),e.printStackTrace()");
e.printStackTrace(System.out);
throw e;
}
}
public static void h() throws Exception { try {
f();
} catch(Exception e) {
System.out.println("Inside h(),e.printStackTrace()");
e.printStackTrace(System.out);
throw (Exception)e.fillInStackTrace();
}
}
public static void main(String[] args) {
try {
g();
} catch(Exception e) {
System.out.println("main: printStackTrace()");
e.printStackTrace(System.out);
}
try {
h();
} catch(Exception e) {
System.out.println("main: printStackTrace()");
e.printStackTrace(System.out);
}
}
} /* Output:
originating the exception in f()
Inside g(),e.printStackTrace()
java.lang.Exception: thrown from f()
at Rethrowing.f(Rethrowing.java:7)
at Rethrowing.g(Rethrowing.java:11)
at Rethrowing.main(Rethrowing.java:29)
main: printStackTrace()
java.lang.Exception: thrown from f()
at Rethrowing.f(Rethrowing.java:7)
at Rethrowing.g(Rethrowing.java:11)
at Rethrowing.main(Rethrowing.java:29)
originating the exception in f()
Inside h(),e.printStackTrace()
java.lang.Exception: thrown from f()
at Rethrowing.f(Rethrowing.java:7)
at Rethrowing.h(Rethrowing.java:20)
at Rethrowing.main(Rethrowing.java:35)
main: printStackTrace()
java.lang.Exception: thrown from f()
at Rethrowing.h(Rethrowing.java:24)
at Rethrowing.main(Rethrowing.java:35)
*///:~3、异常链
异常链:在捕获一个异常后抛出另一个异常,并且希望把原始异常的信息保存下来。
这可以使用带有cause参数的构造器(在Throwable的子类中,只有Error,Exception和RuntimeException三个类提供了带有cause的构造器)或者使用initcause()方法把原始异常传递给新的异常,使得即使在当前位置创建并抛出了新的异常,也能通过这个异常链追踪到异常最初发生的位置,例如:
class DynamicFieldsException extends Exception {}
...
DynamicFieldsException dfe = new DynamicFieldsException();
dfe.initCause(new NullPointerException());
throw dfe;
...//捕获该异常并打印其调用站轨迹为:/**
DynamicFieldsException
at DynamicFields.setField(DynamicFields.java:64)
at DynamicFields.main(DynamicFields.java:94)
Caused by: java.lang.NullPointerException
at DynamicFields.setField(DynamicFields.java:66)
... 1 more
*/以 RuntimeException 及其子类NullPointerException为例,其源码分别为:
RuntimeException 源码包含四个构造器,有两个可接受cause:
public class RuntimeException extends Exception {
static final long serialVersionUID = -7034897190745766939L;
/** Constructs a new runtime exception with <code>null</code> as its
* detail message. The cause is not initialized, and may subsequently be
* initialized by a call to {@link #initCause}.
*/
public RuntimeException() { super();
} /** Constructs a new runtime exception with the specified detail message.
* The cause is not initialized, and may subsequently be initialized by a
* call to {@link #initCause}.
*
* @param message the detail message. The detail message is saved for
* later retrieval by the {@link #getMessage()} method.
*/
public RuntimeException(String message) { super(message);
} /**
* Constructs a new runtime exception with the specified detail message and
* cause. <p>Note that the detail message associated with
* <code>cause</code> is <i>not</i> automatically incorporated in
* this runtime exception's detail message.
*
* @param message the detail message (which is saved for later retrieval
* by the {@link #getMessage()} method).
* @param cause the cause (which is saved for later retrieval by the
* {@link #getCause()} method). (A <tt>null</tt> value is
* permitted, and indicates that the cause is nonexistent or
* unknown.)
* @since 1.4
*/
public RuntimeException(String message, Throwable cause) { super(message, cause);
} /** Constructs a new runtime exception with the specified cause and a
* detail message of <tt>(cause==null ? null : cause.toString())</tt>
* (which typically contains the class and detail message of
* <tt>cause</tt>). This constructor is useful for runtime exceptions
* that are little more than wrappers for other throwables.
*
* @param cause the cause (which is saved for later retrieval by the
* {@link #getCause()} method). (A <tt>null</tt> value is
* permitted, and indicates that the cause is nonexistent or
* unknown.)
* @since 1.4
*/
public RuntimeException(Throwable cause) { super(cause);
}
}NullPointerException 源码仅包含两个构造器,均不可接受cause:
public class NullPointerException extends RuntimeException {
/**
* Constructs a <code>NullPointerException</code> with no detail message.
*/
public NullPointerException() { super();
} /**
* Constructs a <code>NullPointerException</code> with the specified
* detail message.
*
* @param s the detail message.
*/
public NullPointerException(String s) { super(s);
}
}注意:
所有的标准异常类都有两个构造器:一个是默认构造器;另一个是接受字符串作为异常说明信息的构造器。
以上がJava例外モデルの詳細な紹介と分析(図)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7563
7563
 15
1385
52
84
11
28
99
15
1385
52
84
11
28
99


 ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
Java の Weka へのガイド。ここでは、weka java の概要、使い方、プラットフォームの種類、利点について例を交えて説明します。

 Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
この記事では、Java Spring の面接で最もよく聞かれる質問とその詳細な回答をまとめました。面接を突破できるように。
 Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8は、Stream APIを導入し、データ収集を処理する強力で表現力のある方法を提供します。ただし、ストリームを使用する際の一般的な質問は次のとおりです。 従来のループにより、早期の中断やリターンが可能になりますが、StreamのForeachメソッドはこの方法を直接サポートしていません。この記事では、理由を説明し、ストリーム処理システムに早期終了を実装するための代替方法を調査します。 さらに読み取り:JavaストリームAPIの改善 ストリームを理解してください Foreachメソッドは、ストリーム内の各要素で1つの操作を実行する端末操作です。その設計意図はです
 Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプに関するガイド。ここでは、Java でタイムスタンプを日付に変換する方法とその概要について、例とともに説明します。
 カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルは3次元の幾何学的図形で、両端にシリンダーと半球で構成されています。カプセルの体積は、シリンダーの体積と両端に半球の体積を追加することで計算できます。このチュートリアルでは、さまざまな方法を使用して、Javaの特定のカプセルの体積を計算する方法について説明します。 カプセルボリュームフォーミュラ カプセルボリュームの式は次のとおりです。 カプセル体積=円筒形の体積2つの半球体積 で、 R:半球の半径。 H:シリンダーの高さ(半球を除く)。 例1 入力 RADIUS = 5ユニット 高さ= 10単位 出力 ボリューム= 1570.8立方ユニット 説明する 式を使用してボリュームを計算します。 ボリューム=π×R2×H(4
 Spring Tool Suiteで最初のSpring Bootアプリケーションを実行するにはどうすればよいですか?
Feb 07, 2025 pm 12:11 PM
Spring Tool Suiteで最初のSpring Bootアプリケーションを実行するにはどうすればよいですか?
Feb 07, 2025 pm 12:11 PM
Spring Bootは、Java開発に革命をもたらす堅牢でスケーラブルな、生産対応のJavaアプリケーションの作成を簡素化します。 スプリングエコシステムに固有の「構成に関する慣習」アプローチは、手動のセットアップを最小化します。
