

MySQLを監視しながらテーブル情報を収集するコードの詳細説明(画像とテキスト)

1. ストーリー
おそらく、過去 1 年間のライブラリ内の特定のテーブルの月ごとのデータ量の増加についてよく質問されると思います。もちろん、テーブルが月ごとに分割されている場合は、show table status を 1 つずつ実行する方が簡単です。大きなテーブルが 1 つしかない場合は、おそらく単独で SQL 統計を実行する必要があります。現在のテーブル情報のみを取得でき、過去の情報を追跡することはできないため、皆が休んでいる夜に。 show table status,如果只有一个大表,那估计要在大家都休息的时候,寂寞的夜里去跑sql统计了,因为你只能获取当前的表信息,历史信息追查不到了。
除此以外,作为DBA本身也要对数据库空间增长情况进行预估,用以规划容量。我们说的表信息主要包括:
表数据大小(DATA_LENGTH)
索引大小(INDEX_LENGTH)
行数(ROWS)
当前自增值(AUTO_INCREMENT,如果有)
目前是没有看到哪个mysql监控工具上提供这样的指标。这些信息不需要采集的太频繁,而且结果也只是个预估值,不一定准确,所以这是站在一个全局、长远的角度去监控(采集)表的。
本文要介绍的自己写的采集工具,是基于组内现有的一套监控体系:
InfluxDB:时间序列数据库,存储监控数据Grafana:数据展示面板Telegraf:收集信息的agent
看了下 telegraf 的最新的 mysql 插件,一开始很欣慰:支持收集 Table schema statistics 和 Info schema auto increment columns。试用了一下,有数据,但是如前面所说,除了自增值外其他都是预估值,telegraf收集频率过高没啥意义,也许一天2次就足够了,它提供的IntervalSlow选项固定写死在代码里,只能是放缓 global status 监控频率。不过倒是可以与其它监控指标分开成两份配置文件,各自定义收集间隔来实现。
最后打算自己用python撸一个,上报到influxdb里 :)
2. Concept
完整代码见 GitHub项目地址:DBschema_gather
实现也特别简单,就是查询 information_schema 库的 COLUMNS、TABLES 两个表:
SELECT
IFNULL(@@hostname, @@server_id) SERVER_NAME,
%s as HOST,
t.TABLE_SCHEMA,
t.TABLE_NAME,
t.TABLE_ROWS,
t.DATA_LENGTH,
t.INDEX_LENGTH,
t.AUTO_INCREMENT,
c.COLUMN_NAME,
c.DATA_TYPE,
LOCATE('unsigned', c.COLUMN_TYPE) COL_UNSIGNED
# CONCAT(c.DATA_TYPE, IF(LOCATE('unsigned', c.COLUMN_TYPE)=0, '', '_unsigned'))
FROM
information_schema.`TABLES` t
LEFT JOIN information_schema.`COLUMNS` c ON t.TABLE_SCHEMA = c.TABLE_SCHEMA
AND t.TABLE_NAME = c.TABLE_NAME
AND c.EXTRA = 'auto_increment'
WHERE
t.TABLE_SCHEMA NOT IN (
'mysql',
'information_schema',
'performance_schema',
'sys'
)
AND t.TABLE_TYPE = 'BASE TABLE'关于 auto_increment,我们除了关注当前增长到哪了,还会在意相比 int / bigint 的最大值,还有多少可用空间。于是计算了 autoIncrUsage 这一列,用于保存当前已使用的比例。
然后使用 InfluxDB 的python客户端,批量存入influxdb。如果没有InfluxDB,结果会打印出json —— 这是Zabbix、Open-Falcon这些监控工具普遍支持的格式。
最后就是使用 Grafana 从 influxdb 数据源画图。
3. Usage
环境
在 python 2.7 环境下编写的,2.6,3.x没测。
运行需要MySQLdb、influxdb两个库:
$ sudo pip install mysql-python influxdb
配置
settings_dbs.py配置文件DBLIST_INFO:列表存放需要采集的哪些MySQL实例表信息,元组内分别是连接地址、端口、用户名、密码
用户需要select表的权限,否则看不到对应的信息.
InfluxDB_INFO:influxdb的连接信息,注意提前创建好数据库名mysql_info
设置为None可输出结果为json.创建influxdb上的数据库和存储策略
存放2年,1个复制集:(按需调整)放crontab跑
可以单独放在用于监控的服务器上,不过建议在生产环境可以运行在mysql实例所在主机上,安全起见。
テーブル データ サイズ (DATA_LENGTH) < li>インデックス サイズ (INDEX_LENGTH)行数 (ROWS)

現在の自動インクリメント値 (AUTO_INCREMENT、存在する場合)- 🎜
InfluxDB: Timeシリーズデータベース、監視データを保存します🎜 - 🎜
Grafana: データ表示パネル🎜 - 🎜
Telegraf: 情報を収集するエージェント🎜 telegraf の最新の mysql プラグインを試してみましたが、最初は非常に満足しました。テーブル スキーマの統計情報の収集と情報スキーマの自動増分列がサポートされています。試してみたところデータはありましたが、前述したように、telegraf が収集する頻度が高すぎると意味がありません。IntervalSlow が提供されます。 </ code> オプションはハードコーディングされており、グローバル ステータスの監視の頻度を低下させることしかできません。ただし、他の監視インジケーターから 2 つの<a href="http://www.php.cn/code/10545.html" target="_blank">設定ファイル</a>に分離することができ、それぞれが収集間隔を達成します。 🎜</li></ul>🎜最後に、Python を使用して自分でビルドし、influxdb に報告する予定です:)🎜🎜2. コンセプト🎜🎜完全なコードについては、GitHub プロジェクトのアドレスを参照してください: DBschema_gather🎜実装も非常に簡単です。<code> をクエリするだけです。information_schemaライブラリのCOLUMNSとTABLESの 2 つのテーブルです。 🎜🎜 rrreee🎜auto_incrementについては、現在の増加がどこにあるのかに注意を払うことに加えて、int / bigintの最大値と比較して空き領域がどれだけあるかにも注意します。 。そのため、現在使用されている比率を保存するためにautoIncrUsage列が計算されました。 🎜🎜次に、InfluxDB の Python クライアントを使用して、influxdb にバッチで保存します。 InfluxDB がない場合、結果は json として出力されます。これは Zabbix であり、Open です。 -Falcon など 監視ツールで一般的にサポートされている形式。 🎜🎜最後のステップは、Grafana を使用して influxdb データ ソースから画像を描画することです。 🎜🎜3. 使用法🎜- 🎜環境🎜 Python 2.7 環境で書かれています。2.6 と 3.x はテストされていません。 🎜
MySQLdbとinfluxdb: 🎜rrreee- 🎜設定🎜
settings_dbs.py設定ファイル🎜 - 🎜🎜🎜
- 🎜
DBLIST_INFO: リストには、収集する必要がある MySQL インスタンス テーブル情報が保存されます。タプルは、接続アドレス、ポート、ユーザー名、およびパスワードです。ユーザーは、テーブルを選択する権限が必要です。そうでない場合、対応する情報を取得することはできません。 🎜 - 🎜
InfluxDB_INFO: Influxdb 接続情報。データベース名 mysql_info🎜結果を json として出力するには、Noneに設定します。🎜 - 🎜influxdb 上にデータベースとストレージ戦略を作成します🎜ストレージは 2 年間、 1 レプリカ セット: (オンデマンド調整) 🎜 rrreee🎜次のような大きなメッセージを参照してください: 🎜
- 🎜crontabを実行🎜監視用のサーバーに別途置くこともできますが、セキュリティ上の理由から、mysql インスタンスが配置されているホストの実稼働環境で実行することをお勧めします。 🎜
- 🎜チャートを生成します🎜
サブデータベースとテーブルの場合、テーブル autoIncrUsage でグローバル一意の ID を計算することはできません
実装は非常に簡単で、より重要なことはこの情報を収集する意識
を高めることができます グラファイト出力フォーマット
CREATE DATABASE "mysql_info" CREATE RETENTION POLICY "mysql_info_schema" ON "mysql_info" DURATION 730d REPLICATION 1 DEFAULT
看大的信息类似于: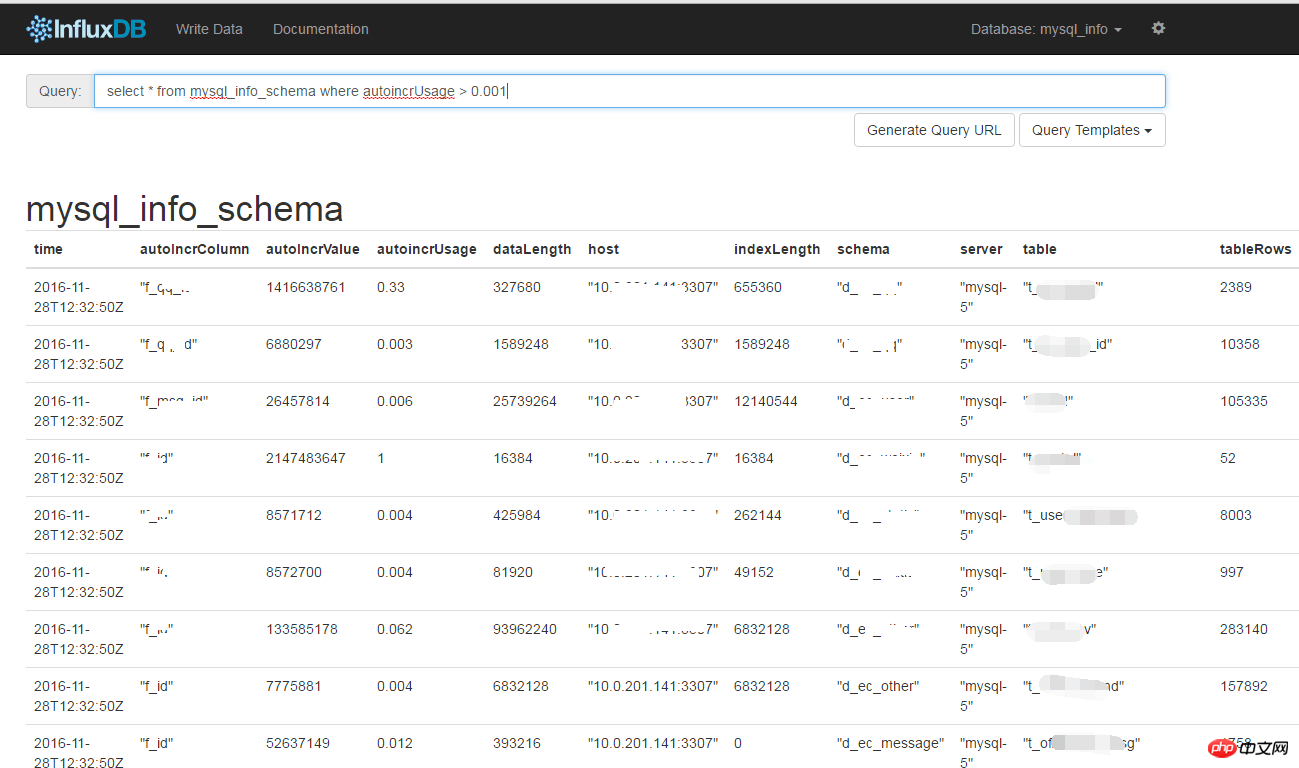
一般库在晚上会有数据迁移的动作,可以在迁移前后分别运行 mysql_schema_info.py 来收集一次。不建议太频繁。
40 23,5,12,18 * * * /opt/DBschema_info/mysql_schema_info.py >> /tmp/collect_DBschema_info.log 2>&1
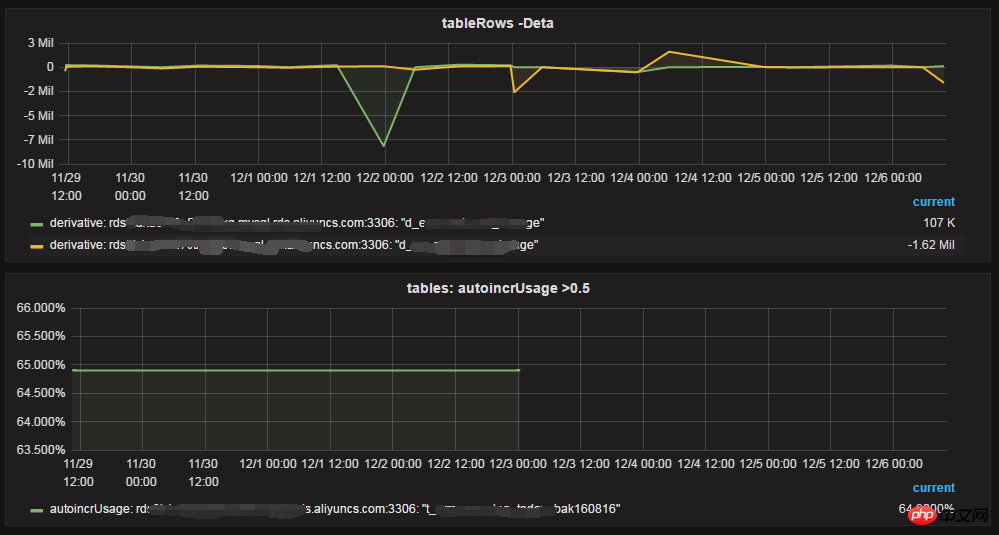
 🎜
🎜mysql_schema_info.py を実行してデータを収集できます。あまり頻繁にはお勧めしません。 🎜rrreeegrafana_table_stats.json を Grafana パネルにインポートします。効果は次のとおりです: 🎜🎜🎜🎜テーブルのデータサイズと行数🎜🎜🎜🎜🎜🎜毎日の行番号変更の増分、auto_incrementの使用🎜🎜4. 詳細
以上がMySQLを監視しながらテーブル情報を収集するコードの詳細説明(画像とテキスト)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7708
7708
 15
1640
14
1394
52
1288
25
1232
29
15
1640
14
1394
52
1288
25
1232
29

 MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQLはオープンソースのリレーショナルデータベース管理システムであり、主にデータを迅速かつ確実に保存および取得するために使用されます。その実用的な原則には、クライアントリクエスト、クエリ解像度、クエリの実行、返品結果が含まれます。使用法の例には、テーブルの作成、データの挿入とクエリ、および参加操作などの高度な機能が含まれます。一般的なエラーには、SQL構文、データ型、およびアクセス許可、および最適化の提案には、インデックスの使用、最適化されたクエリ、およびテーブルの分割が含まれます。
 phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
次の手順でphpmyadminを開くことができます。1。ウェブサイトコントロールパネルにログインします。 2。phpmyadminアイコンを見つけてクリックします。 3。MySQL資格情報を入力します。 4.「ログイン」をクリックします。
 なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
MySQLは、そのパフォーマンス、信頼性、使いやすさ、コミュニティサポートに選択されています。 1.MYSQLは、複数のデータ型と高度なクエリ操作をサポートし、効率的なデータストレージおよび検索機能を提供します。 2.クライアントサーバーアーキテクチャと複数のストレージエンジンを採用して、トランザクションとクエリの最適化をサポートします。 3.使いやすく、さまざまなオペレーティングシステムとプログラミング言語をサポートしています。 4.強力なコミュニティサポートを提供し、豊富なリソースとソリューションを提供します。
 MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
データベースとプログラミングにおけるMySQLの位置は非常に重要です。これは、さまざまなアプリケーションシナリオで広く使用されているオープンソースのリレーショナルデータベース管理システムです。 1)MySQLは、効率的なデータストレージ、組織、および検索機能を提供し、Web、モバイル、およびエンタープライズレベルのシステムをサポートします。 2)クライアントサーバーアーキテクチャを使用し、複数のストレージエンジンとインデックスの最適化をサポートします。 3)基本的な使用には、テーブルの作成とデータの挿入が含まれ、高度な使用法にはマルチテーブル結合と複雑なクエリが含まれます。 4)SQL構文エラーやパフォーマンスの問題などのよくある質問は、説明コマンドとスロークエリログを介してデバッグできます。 5)パフォーマンス最適化方法には、インデックスの合理的な使用、最適化されたクエリ、およびキャッシュの使用が含まれます。ベストプラクティスには、トランザクションと準備された星の使用が含まれます
 Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheはデータベースに接続するには、次の手順が必要です。データベースドライバーをインストールします。 web.xmlファイルを構成して、接続プールを作成します。 JDBCデータソースを作成し、接続設定を指定します。 JDBC APIを使用して、接続の取得、ステートメントの作成、バインディングパラメーター、クエリまたは更新の実行、結果の処理など、Javaコードのデータベースにアクセスします。
 DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerでMySQLを起動するプロセスは、次の手順で構成されています。MySQLイメージをプルしてコンテナを作成および起動し、ルートユーザーパスワードを設定し、ポート検証接続をマップしてデータベースを作成し、ユーザーはすべての権限をデータベースに付与します。
 MySQLの役割:Webアプリケーションのデータベース
Apr 17, 2025 am 12:23 AM
MySQLの役割:Webアプリケーションのデータベース
Apr 17, 2025 am 12:23 AM
WebアプリケーションにおけるMySQLの主な役割は、データを保存および管理することです。 1.MYSQLは、ユーザー情報、製品カタログ、トランザクションレコード、その他のデータを効率的に処理します。 2。SQLクエリを介して、開発者はデータベースから情報を抽出して動的なコンテンツを生成できます。 3.MYSQLは、クライアントサーバーモデルに基づいて機能し、許容可能なクエリ速度を確保します。
 MySQLをCentos7にインストールする方法
Apr 14, 2025 pm 08:30 PM
MySQLをCentos7にインストールする方法
Apr 14, 2025 pm 08:30 PM
MySQLをエレガントにインストールするための鍵は、公式のMySQLリポジトリを追加することです。特定の手順は次のとおりです。MYSQLの公式GPGキーをダウンロードして、フィッシング攻撃を防ぎます。 mysqlリポジトリファイルを追加:rpm -uvh https://dev.mysql.com/get/mysql80-community-rease-el7-3.noarch.rpm update yumリポジトリキャッシュ:yumアップデートインストールmysql:yumインストールmysql-server startup mysql sportin
