

MySQLインデックスの詳しい説明

MySQL のインデックスは B+tree を介しています。 B+tree はバランス型バイナリ ツリーの一種であるため、クエリ速度が非常に高速です。
インデックスは主にクラスター化インデックスと補助インデックスに分けられます:
クラスター化インデックス: mysqlのデータは主キーのクラスター化インデックスを介して保存されるため、リーフノードは各行のデータを保存するため、主キーを使用します。
これが非常に高速である理由は、主キーがクラスター化インデックスであるためですが、実際の使用では、そのような B+ ツリーが 1 つだけ構築されるため、主キーが一意である理由が説明できます。
インターネット上の画像の引用:
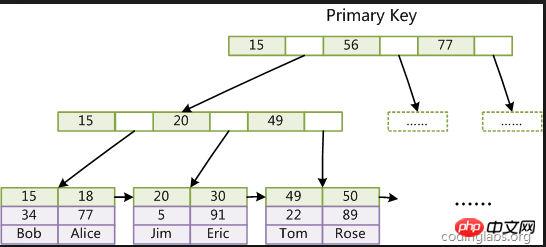
各層での検索は IO 操作であり、一般的に B+tree 層の数は 2 ~ 4 であるため、最悪の場合のみ実行する必要があります。 4 回の IO 操作。
補助インデックス: 補助インデックスとクラスター化インデックスの違いは、すべてのデータがリーフ ノードに保存されるわけではなく、データの場所が保存されることです。これは、補助インデックスを使用してデータを検索し、クラスター化インデックスのツリーを通じて詳細情報を検索することと同じです。
インターネット上の画像からの引用:
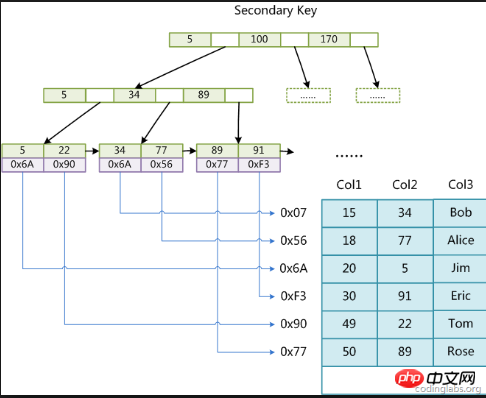 この画像は論理的な画像ですが、最下層はリーフ ノードを介してクラスター化インデックスを指します。つまり、最初のタイプの画像を通過する必要があります。次は
この画像は論理的な画像ですが、最下層はリーフ ノードを介してクラスター化インデックスを指します。つまり、最初のタイプの画像を通過する必要があります。次は
ロジック。
最終結果は、クラスター化インデックス ツリーを指す複数の補助インデックス ツリーになります
(図は本当に醜いです)
いつインデックスを作成すべきかについてこれはツリーなので、 through 二分探索法で検索するため、whereの条件として使用するのに適しており、値の範囲も広く、インデックスを作成するのに適しています。範囲が狭いもの (is_delete、sex などの列挙型) には適していません。
特定の状況については、show Index を通じて分析できます:
show index from company_related_person
結果:
 次にカーディナリティを通じて計算します
次にカーディナリティを通じて計算します
select 105/(select count(*) from company_related_person) from DUAL
ここで得られた結果は 0.913 です (この値はストレージ容量に関連しており、これが最適です)この値が 1 に近いほど、インデックスの効率が高くなります。計算された値が非常に小さい場合は、インデックスを作成しないことをお勧めします
Explain
EXPLAIN select * from company_related_person where company_id='2'
Output
によるインデックス  key は現在使用されているインデックス列を表します。最後の追加は、どのメソッドが使用されるかを示します。ここで、「インデックスを使用」は、ディスクが直接読み取られることを示します。 。
key は現在使用されているインデックス列を表します。最後の追加は、どのメソッドが使用されるかを示します。ここで、「インデックスを使用」は、ディスクが直接読み取られることを示します。 。
SQL パフォーマンス最適化の目標: 少なくとも範囲レベルに達すること。要件は参照レベルであり、const にできればそれが最善です。
1) 定数 1 つのテーブルには一致する行 (主キーまたは一意のインデックス) が最大 1 つあり、最適化フェーズ中にデータを読み取ることができます。
2) ref は、通常のインデックスの使用を指します。
3) range はインデックスの範囲取得を実行します
4) インデックスはディスクから直接読み取ることを意味します
上の図からも、ref を使用していることがわかります
インデックスとキーの違いについて:インデックスを作成するときに、「インデックスとキーの違いは何ですか?」という質問がよくあります。 。キーは、主キー (Primary Key)、外部キー (Foreign Key) など、データの整合性チェックや一意性制約に使用される、リレーショナル モデル理論の一部であるキー値です。インデックスは実装レベルにあります。たとえば、テーブルの任意の列にインデックスを付けることができ、インデックス付きの列が SQL ステートメントの Where 条件に含まれる場合、データの場所を高速に取得できるようになります。 Unique Index については、インデックスの 1 つの種類にすぎません。Unique Index の確立は、この列のデータを繰り返すことができないことを意味します。
以上がMySQLインデックスの詳しい説明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1662
1662
 14
1418
52
1311
25
1261
29
1234
24
14
1418
52
1311
25
1261
29
1234
24

 MySQLの役割:Webアプリケーションのデータベース
Apr 17, 2025 am 12:23 AM
MySQLの役割:Webアプリケーションのデータベース
Apr 17, 2025 am 12:23 AM
WebアプリケーションにおけるMySQLの主な役割は、データを保存および管理することです。 1.MYSQLは、ユーザー情報、製品カタログ、トランザクションレコード、その他のデータを効率的に処理します。 2。SQLクエリを介して、開発者はデータベースから情報を抽出して動的なコンテンツを生成できます。 3.MYSQLは、クライアントサーバーモデルに基づいて機能し、許容可能なクエリ速度を確保します。
 Laravelは紹介例
Apr 18, 2025 pm 12:45 PM
Laravelは紹介例
Apr 18, 2025 pm 12:45 PM
Laravelは、Webアプリケーションを簡単に構築するためのPHPフレームワークです。次のような強力な機能を提供します。インストール:Laravel CLIを作曲家にグローバルにインストールし、プロジェクトディレクトリにアプリケーションを作成します。ルーティング:ルート/web.phpのURLとハンドラーの関係を定義します。ビュー:リソース/ビューでビューを作成して、アプリケーションのインターフェイスをレンダリングします。データベース統合:MySQLなどのデータベースとのすぐ外側の統合を提供し、移行を使用してテーブルを作成および変更します。モデルとコントローラー:モデルはデータベースエンティティを表し、コントローラーはHTTP要求を処理します。
 DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerでMySQLを起動するプロセスは、次の手順で構成されています。MySQLイメージをプルしてコンテナを作成および起動し、ルートユーザーパスワードを設定し、ポート検証接続をマップしてデータベースを作成し、ユーザーはすべての権限をデータベースに付与します。
 MySQLおよびPHPMYADMIN:コア機能と関数
Apr 22, 2025 am 12:12 AM
MySQLおよびPHPMYADMIN:コア機能と関数
Apr 22, 2025 am 12:12 AM
MySQLとPHPMyAdminは、強力なデータベース管理ツールです。 1)MySQLは、データベースとテーブルを作成し、DMLおよびSQLクエリを実行するために使用されます。 2)PHPMyAdminは、データベース管理、テーブル構造管理、データ操作、ユーザー許可管理のための直感的なインターフェイスを提供します。
 データベース接続の解決問題:Minii/DBライブラリを使用する実用的なケース
Apr 18, 2025 am 07:09 AM
データベース接続の解決問題:Minii/DBライブラリを使用する実用的なケース
Apr 18, 2025 am 07:09 AM
小さなアプリケーションを開発する際には、軽量データベース操作ライブラリをすばやく統合する必要性という厄介な問題に遭遇しました。複数のライブラリを試した後、私はそれらがあまりにも多くの機能を持っているか、あまり互換性がないかのどちらかであることがわかりました。最終的に、私は問題を完全に解決したYii2に基づいた単純化されたバージョンであるMinii/DBを見つけました。
 MySQL対その他のプログラミング言語:比較
Apr 19, 2025 am 12:22 AM
MySQL対その他のプログラミング言語:比較
Apr 19, 2025 am 12:22 AM
他のプログラミング言語と比較して、MySQLは主にデータの保存と管理に使用されますが、Python、Java、Cなどの他の言語は論理処理とアプリケーション開発に使用されます。 MySQLは、データ管理のニーズに適した高性能、スケーラビリティ、およびクロスプラットフォームサポートで知られていますが、他の言語は、データ分析、エンタープライズアプリケーション、システムプログラミングなどのそれぞれの分野で利点があります。
 Laravel Frameworkインストール方法
Apr 18, 2025 pm 12:54 PM
Laravel Frameworkインストール方法
Apr 18, 2025 pm 12:54 PM
記事の概要:この記事では、Laravelフレームワークを簡単にインストールする方法について読者をガイドするための詳細なステップバイステップの指示を提供します。 Laravelは、Webアプリケーションの開発プロセスを高速化する強力なPHPフレームワークです。このチュートリアルは、システム要件からデータベースの構成とルーティングの設定までのインストールプロセスをカバーしています。これらの手順に従うことにより、読者はLaravelプロジェクトのための強固な基盤を迅速かつ効率的に築くことができます。
 初心者向けのMySQL:データベース管理を開始します
Apr 18, 2025 am 12:10 AM
初心者向けのMySQL:データベース管理を開始します
Apr 18, 2025 am 12:10 AM
MySQLの基本操作には、データベース、テーブルの作成、およびSQLを使用してデータのCRUD操作を実行することが含まれます。 1.データベースの作成:createdatabasemy_first_db; 2。テーブルの作成:createTableBooks(idintauto_incrementprimarykey、titlevarchary(100)notnull、authorvarchar(100)notnull、published_yearint); 3.データの挿入:InsertIntoBooks(タイトル、著者、公開_year)VA
