

この記事では、cassandra の高度な操作を実装するための ページネーション の例を主に紹介します (特定のプロジェクト要件を伴う)。興味のある方は参考にしてください。
前回のブログでは cassandra ページングについて説明しましたが、皆さんも注目していただけると思います。次の クエリ は前のクエリ (前のクエリの最後のレコードのすべての主キー) に依存しますが、これは ほど柔軟ではありません。そのため、前ページと次ページの機能しか実装できませんが、最初のページの機能は実装できません(無理に実装すると性能が落ちてしまいます)。
まずは クエリで取得したレコード数が多すぎて一度に返すと効率が非常に低く、メモリオーバーフローを引き起こす可能性がありますアプリケーション全体をクラッシュさせます。したがって、ドライバーは結果セットをページ分割し、データの適切なページを返します。1. フェッチ サイズの設定
フェッチ サイズは、cassandra から一度に取得できるレコードの数を指します。つまり、クラスター インスタンスを作成するときに指定します。フェッチ サイズのデフォルト値。指定しない場合、デフォルト値は 5000 です// At initialization:
Cluster cluster = Cluster.builder()
.addContactPoint("127.0.0.1")
.withQueryOptions(new QueryOptions().setFetchSize(2000))
.build();
// Or at runtime:
cluster.getConfiguration().getQueryOptions().setFetchSize(2000);Statement statement = new SimpleStatement("your query");
statement.setFetchSize(2000);2. 結果セットの反復
フェッチ サイズは、特定のページを反復すると、ドライバーがバックグラウンドで次のページのレコードを自動的にフェッチします。次の例のように、フェッチ サイズ = 20: 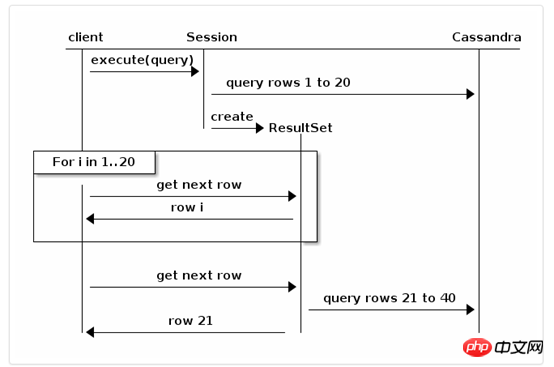
インターフェースが次のメソッドを提供します:
getAvailableWithoutFetching() and isFullyFetched() to check the current state; fetchMoreResults() to force a page fetch;
ResultSet rs = session.execute("your query");
for (Row row : rs) {
if (rs.getAvailableWithoutFetching() == 100 && !rs.isFullyFetched())
rs.fetchMoreResults(); // this is asynchronous
// Process the row ...
System.out.println(row);
}オブジェクト を公開します。
ResultSet resultSet = session.execute("your query");
// iterate the result set...
PagingState pagingState = resultSet.getExecutionInfo().getPagingState();
// PagingState对象可以被序列化成字符串或字节数组
String string = pagingState.toString();
byte[] bytes = pagingState.toBytes();PagingState.fromBytes(byte[] bytes); PagingState.fromString(String str);
ページング状態を保存すると、あるページから次のページへの移動が適切に機能するようになります (前のページも実装できます)。ただし、ページ 10 に直接ジャンプするなどのランダムなジャンプは満たされません。 10ページ目 前ページのページングステータス。オフセットクエリを必要とするこのような機能は、cassandra ではネイティブにサポートされていません。その理由は、オフセットクエリが非効率であるため (パフォーマンスはスキップされる行の数に線形反比例するため)、cassandra は公式にオフセットの使用を推奨していません。オフセット クエリを実装する必要がある場合は、クライアント側でシミュレートできます。ただし、パフォーマンスは依然として線形に反比例します。つまり、パフォーマンスが許容範囲内であれば、オフセットが大きいほどパフォーマンスは低下します。たとえば、各ページは 10 行表示され、最大 20 ページを表示できます。これは、20 ページ目を表示するときに最大 190 行を追加で取得する必要があることを意味しますが、これによってパフォーマンスが大幅に低下することはありません。 , データ量が大きくない場合でも、オフセット クエリをシミュレートすることは可能です。
たとえば、各ページに 10 レコードが表示され、フェッチ サイズが 50 であると仮定すると、ページ 12 (つまり、行 110 から 119) を要求します:
1 クエリが初めて実行されるとき、結果セット。 49 行目には、ページング ステータスを使用する必要はありません。
2. 最初のクエリで取得したページング ステータスを使用して、2 番目のクエリを実行します。 2 番目のクエリから、3 番目のクエリを実行します。結果セットには 100 ~ 149 行が含まれます。
4. 3 番目のクエリで取得した結果セットを使用して、最初に最初の 10 レコードを除外し、次に 10 レコードを読み取り、最後に残りのレコードを破棄して 10 レコードを読み取ります。 12ページに表示する必要があるレコード。
最適なバランスを実現するには、最適なフェッチ サイズを見つける必要があります。小さすぎるとバックグラウンドでのクエリが多くなり、大きすぎると大量の情報と不要な行が返されます。
また、cassandra 自体はオフセットクエリをサポートしていません。満足のいくパフォーマンスを前提とした場合、クライアント側のシミュレーション オフセットの実装は妥協にすぎません。公式の推奨事項は次のとおりです。
1. 想定が正しいことを確認するために、予想されるクエリ パターンを使用してコードをテストします。
2. 悪意のあるユーザーが大量のページをスキップするクエリをトリガーしないように、最大ページ数にハード制限を設定します。行
5 つ目、概要 Cassandra ではページングのサポートが制限されており、前のページと次のページの実装がより簡単です。オフセット クエリはサポートされていません。どうしても実装したい場合は、クライアント シミュレーションを使用できます。ただし、cassandra は一般にビッグ データの問題を解決するために使用され、データ量をオフセットするため、このシナリオは cassandra では使用しないことをお勧めします。クエリ内の値が大きすぎると、パフォーマンスを向上させることができません。私のプロジェクトでは、
indexrepair は cassandra のページングを使用します。シナリオは次のとおりです。cassandra テーブルはセカンダリ インデックスを構築せず、elasticsearch を使用して cassandra テーブルのセカンダリ インデックスを実装します。これには整合性修復が含まれます。この問題では、cassandra のページングを使用して、cassandra の特定のテーブルを 1 つずつ検索し、elasticsearch に存在しない場合は、elasticsearch に追加します。矛盾している場合は、elasticsearch で修正します。 elasticsearch が cassandra のインデックス作成機能をどのように実装するかについては、次回のブログで具体的に説明するので、ここでは詳しく説明しません。 cassandra テーブル全体を走査する場合、テーブル内のデータ量が大きすぎて、一度に数億のデータをメモリにロードすることができないため、ページングが必要になります。
以上がJava が cassandra の高度な操作のページング例を実装 (写真)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



