

は、PHP プログラムを使用して、他の Web サイトから情報を独自のデータベースと Web サイトに取り込むことです。
PHPの生成および収集技術:
基盤となるソケットから高レベルのファイル操作関数まで、収集を実現するには合計3つの方法があります。
1. ソケットテクノロジーを使用したコレクション:
ソケットコレクションは長い接続を確立するだけであり、その後、リクエストを送信するために http プロトコル文字列を構築する必要があります。
たとえば、このページ tv.youku.com/?spm=a2hww.20023042.topNav.5~1~3!2~A のコンテンツを取得したい場合は、ソケットを使用して次のように書き込みます
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
返されたヘッダー情報とページのソースコードを含む出力結果は次のとおりです:

2. カプセル化するには、curl_a セットを使用します
HTTP プロトコルを多くの関数に直接渡すだけで、対応するパラメーターを渡すだけで、HTTP プロトコル文字列を記述する難しさが軽減されます。
前提条件:curl 拡張機能が php.ini で有効になっている必要があります。
1 2 3 4 5 6 7 8 |
|
出力結果は次のとおりで、ページのソース コードのみが含まれています: 
3. file_get_contents (最上位) を直接使用します
前提条件: 開く権限を設定します。 php.ini内 ネットワークの URL アドレス。

1 2 3 |
|

3つの方法から選択
上記の3つは主にネットワーク間の通信に使用されます。このうち、後者の 2 つはより一般的に使用されます: 大量のデータをバッチで収集したい場合は、パフォーマンスと安定性に優れた 2 番目の [CURL] を使用します。
頻繁ではないが時々いくつかのリクエストを送信する場合は、3 番目の方法を使用します。
拡張: 写真のアンチリーチを解除するにはどうすればよいですか?
たとえば、7060 の Web サイト上の写真はホットリンクから保護されています。写真は彼の Web サイトで見ることができますが、サイトの外からはアクセスできません。
原則: HTTP プロトコルにはリクエストの送信元アドレスを表すリファラー項目があり、サーバーはリクエストがこの Web サイトからのものではないと判断し、リクエストを除外します。 :
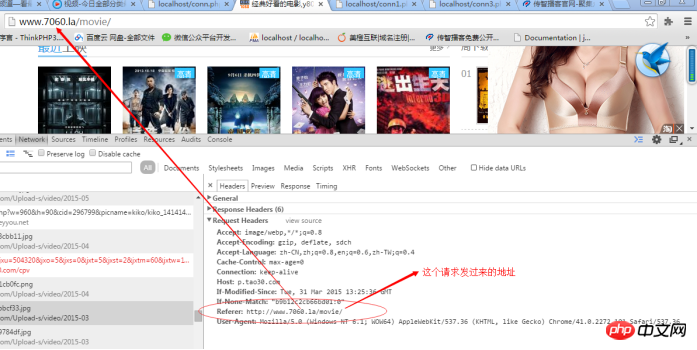
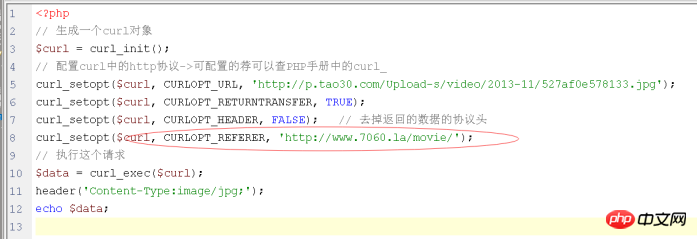
解決策: HTTP を送信するときにリファラーを自分でシミュレートするだけです:
拡張機能: 最初にログインする必要があるときに一部のデータを収集する必要があります。シミュレートされたトライアルを使用できます。ログイン状態でコレクションをシミュレートします:
a. 先用浏览登录一下,登录完,浏览器的COOKIE中就会有SESSIONID
b. 发PHP发HTTP协议时,把浏览器中的SESSIONID放到PHP的HTTP协议请求里,这样就在以登录的状态发请求。
总结:所有客户端发过来的数据都可以被模拟,所以服务器上的程序必须要必要的地方过滤客户端的数据。
什么时候用以上东西?接口开发时、采集时。
二、数据采集
例如我要采集这个url里的所有美国电影的信息,
list.youku.com/category/show/c_96_a_%E7%BE%8E%E5%9B%BD_s_1_d_1_p_3.html
则先要知道电影所在的节点的结构,我们使用firebug查看。
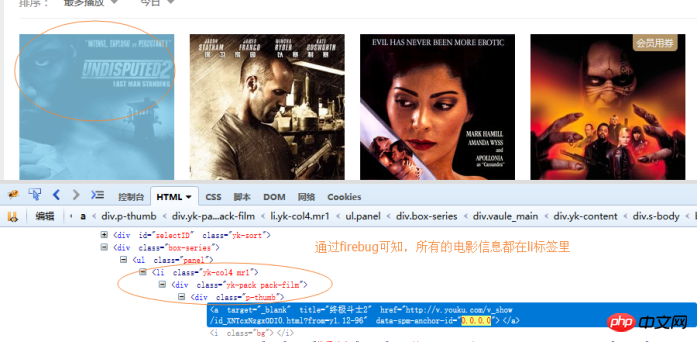
然后开始写代码:完整代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
|
测试:
打印$list;

打印$img

打印$video

最终效果:
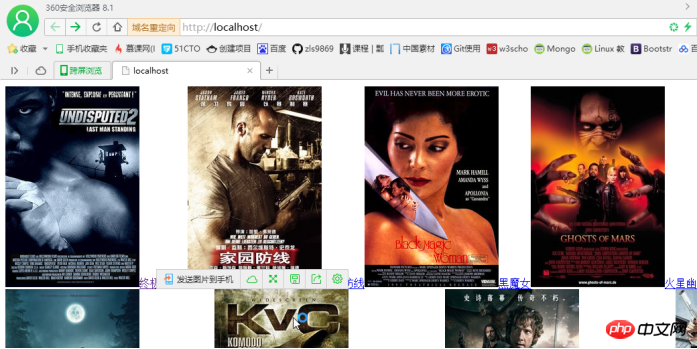
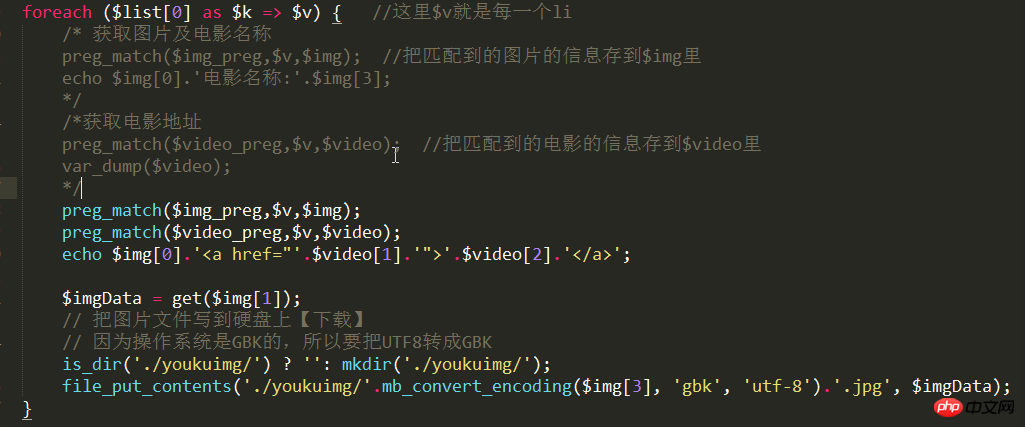
如果需要把图片拷贝到硬盘上,则在foreach循环里加上以下代码:
1 2 3 4 5 |
|
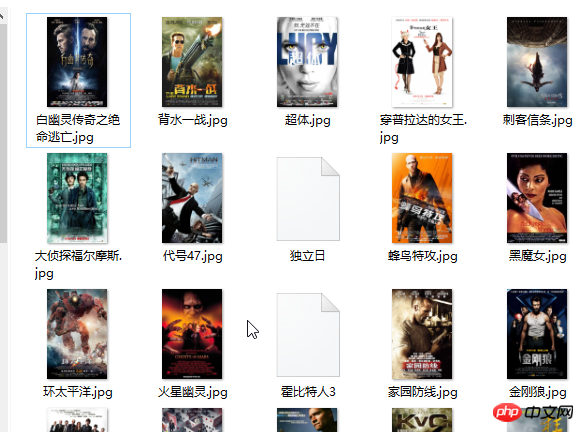
效果如下:在当前目录下的youkuimg目录下就会有下载好的图片。
以上がPHP でデータ収集を実装する 3 つの方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



