

前の記事のノードエントリシナリオ - クローラーでは、最も単純なノード クローラーの実装を紹介しました。この記事では、元のベースにさらに進み、ログインをバイパスしてログイン領域のデータをクロールする方法について説明します
理論的根拠
ログインステータスを維持する方法
ブラウザはどのようにしてそれを行うのでしょうか?
認証コードがある場合解除方法
プロトコルとして、クライアントとサーバーの間で長い接続は維持されません。サーバーは、独立したリクエストとレスポンスの間でどのインターフェースが同じクライアントからのものかをどのように識別しますか?あなたは賢いので、次のメカニズムを簡単に考えることができます:
クライアントがサーバーをリクエストするとき、サーバーは、クライアントが sessionId を渡していないと判断し、セッション ID を生成してメモリに保存し、この sessionId をクライアントに返します
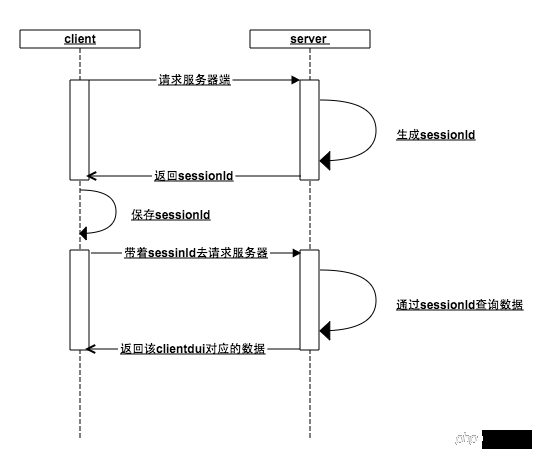
クライアントは sessionId を取得します。次のリクエストを行うときに、このセッション ID がサーバーから取得され、ローカルに保存されます。サーバーは、セッション ID がメモリに存在するかどうかを確認します (前のステップで、ユーザーがログイン インターフェイスにアクセスした場合、メモリにはセッション ID が存在します)。セッション ID を
、ユーザー データを値 として保存されているため、サーバーはセッション ID
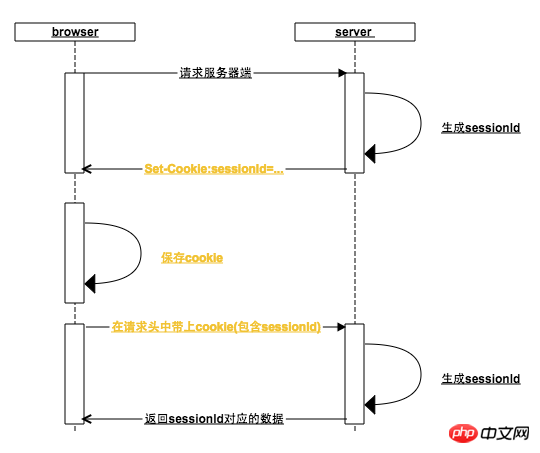
の固有の識別子に基づいてクライアントに対応するデータを返すことができます。 sessionId を指定すると、前の手順が繰り返されます。誰も知らないので、最初からやり直します1. すべての http リクエストで、ブラウザはリクエスト アドレスのドメイン名に対応する Cookie を追加します。上の図では、サーバーへの最初のリクエストにもリクエスト ヘッダーに Cookie が含まれていますが、Cookie には sessionId がありません。2. ブラウザはサーバーの応答ヘッダーに従って応答します。
Set-Cookie は、Cookie を設定します。この目的のために、サーバーは、生成された sessionId を Set-Cookie に入れます。ブラウザは Set-Cookie 命令を受信すると、ローカル Cookie を設定します。通常の状況では、サーバーが Set-cookie を返すとき、sessionId の有効期限はブラウザが閉じられたときに期限切れになるように設定されます。これが理由です。は、開始から終了までのセッションです (一部の Web サイトでは、長期間にわたって Cookie の有効期限が切れないように設定して、ログインしたままにすることもできます)3. ブラウザーがバックグラウンドで再度リクエストを開始すると、リクエストヘッダーには既にセッション ID が含まれています。ユーザーが以前にログイン インターフェイスにアクセスしたことがある場合、そのセッション ID に基づいてユーザー データが照会されます
例は次のとおりです。まず、chr
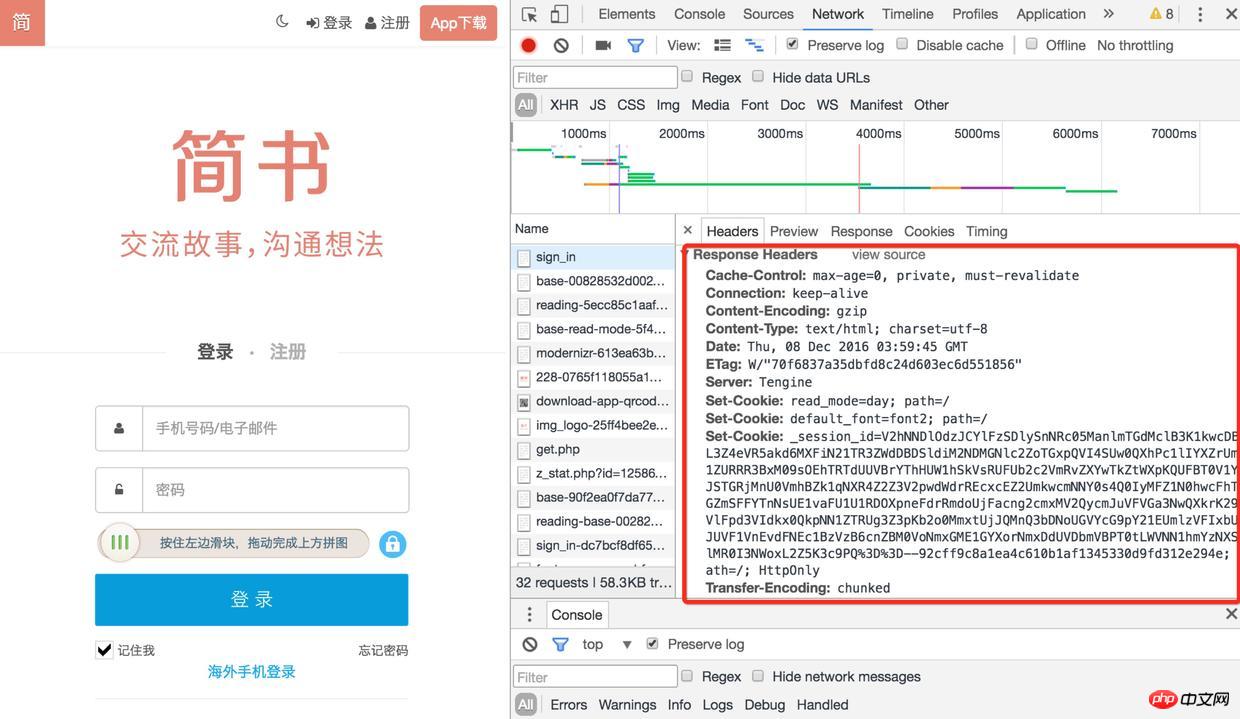
ome によって開かれたログイン ページを使用して、アプリケーション内で http://www.jianshu を見つけ、[ネットワーク] 項目を入力して、ログの保存にチェックを入れます (そうしないと、後で以前のログを見ることができなくなります)。ページはリダイレクトされます)
ログイン
2) 次に、ページを更新してサインイン インターフェイスを見つけます。応答ヘッダーには多くの Set-Cookie があります
。
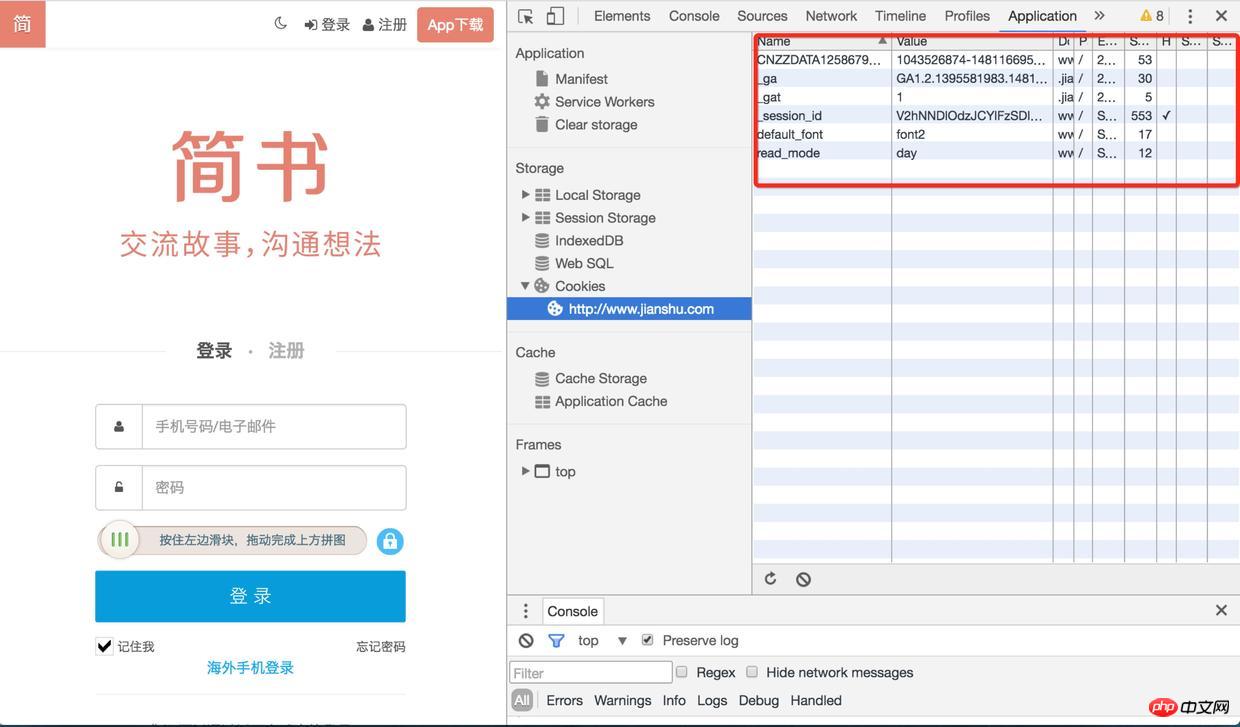
ログイン
3) Cookie を再度確認すると、次回 他のインターフェースをリクエストするとき (確認コードの取得、ログインなど)、セッション ID が保存されます。このセッション ID、ユーザーの情報はログイン後のセッション ID にも関連付けられます
ログイン
ブラウザの動作方法をシミュレートしてアクセスする必要があります。 Web サイトのログイン領域
)。
テスト用に検証コードのない Web サイトが見つかりました。 検証コードのある Web サイトには、検証コードの識別も含まれます (ログインは考慮されていません。検証コードの複雑さは次のセクションで説明されます
// 浏览器请求报文头部部分信息
var browserMsg={
"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36",
'Content-Type':'application/x-www-form-urlencoded'
};
//访问登录接口获取cookie
function getLoginCookie(userid, pwd) {
userid = userid.toUpperCase();
return new Promise(function(resolve, reject) {
superagent.post(url.login_url).set(browserMsg).send({
userid: userid,
pwd: pwd,
timezoneOffset: '0'
}).redirects(0).end(function (err, response) {
//获取cookie
var cookie = response.headers["set-cookie"];
resolve(cookie);
});
});
}サーバーがこれらのリクエスト ヘッダー情報を検証する可能性があるため、Chrome でリクエストをキャプチャし、いくつかのリクエスト ヘッダー情報を取得する必要があります。たとえば、私が実験した Web サイトでは、最初に User-Agent を渡さなかったのですが、サーバーはリクエストがサーバーからのものではないことを検出し、一連の エラー メッセージ を返したので、後で User-Agent を設定しました。 -エージェントとChromeブラウザに偽装~~
superagentは、クライアントサイドのHTTPリクエストライブラリです。これを使用すると、簡単にリクエストを送信したり、Cookieを処理したりできます(httpを呼び出してヘッダフィールドのデータを操作するのはあまり便利ではありません)。自分で設定してください - Cookie を作成した後、それらを適切な形式の Cookie に組み立てる必要があります。 redirects(0)は主にリダイレクトしないように設定しています
function getData(cookie) {
return new Promise(function(resolve, reject) {
//传入cookie
superagent.get(url.target_url).set("Cookie",cookie).set(browserMsg).end(function(err,res) {
var $ = cheerio.load(res.text);
resolve({
cookie: cookie,
doc: $
});
});
});
}前手順でset-cookieを取得した後、getDataメソッドを渡し、スーパーエージェント経由のリクエストに設定します(set-cookie は Cookie にフォーマットされます)、通常はログイン データを取得できます
実際のシナリオでは、Web サイトごとに異なるセキュリティ対策があるため、それほどスムーズではない可能性があります。たとえば、一部の Web サイトでは、次のことが必要になる場合があります。トークンの場合、一部の Web サイトではパラメータを暗号化する必要があり、一部の Web サイトではより高いセキュリティが必要で、リプレイ防止メカニズムが備えられています。方向性クローラーでは、Web サイトの処理メカニズムを詳細に分析する必要があります。それを回避できない場合でも、十分です~~
しかし、一般的なコンテンツと情報を含む Web サイトを扱うにはまだ十分です
。上記のメソッドでリクエストされたのは単なる段落の htmlstring です。ここではまだ古いメソッドが使用されています。cheerio ライブラリを使用して文字列をロードすると、jquerydom に似た object を取得でき、 jquery のような dom、これはまさに良心によって作られたアーティファクトです。
認証コードを入力せずにログインできる Web サイトは何個ありますか?もちろん、12306 の認証コードを特定しようとはしません。このような良心的な認証コードは期待できません。Zhihu のような若すぎて単純すぎる認証コードにも挑戦できます。
TesseractはGoogleのオープンソースOCR認識ツールですが、nodeとは関係ありませんが、具体的な使用方法は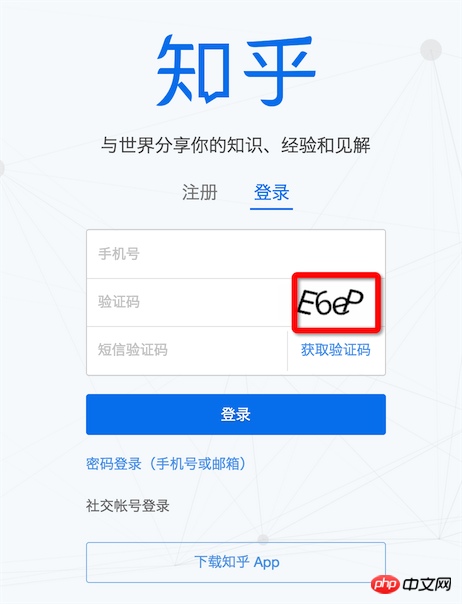 node.js
node.js
を使って簡単な検証コード認識を実装します
。 graphicsmagick を使用した場合でも、
imagesの前処理は高い認識率を保証しません。このため、tesseract をトレーニングすることもできます。参考: jTessBoxEditor ツールを使用して Tesseract3.02.02 サンプルをトレーニングし、検証コードの認識率を向上させることはできますか?認識率の高さはあなたのキャラクターに依存します~~~ 4 番目に、拡張機能
ログイン状態をバイパスする簡単な方法があります。PhantomJS は、Webkitapi をベースにしたオープンソース サーバー JS です。 、ブラウザと考えることができますが、js スクリプトを通じて制御できます。
ブラウザの
動作このメソッドには欠点がないわけではありません。つまり、必要のない JS、CSS、および画像の 静的リソースを読み込む必要がありません。複数回クリックすると目的のページに到達する可能性がありますが、目的のURLに直接アクセスするよりも効率は低くなります
興味があれば検索してください 5. まとめ
ディスカッション用のメッセージです。役に立った場合は、いいねを残してください~~
以上がノード クローラーの詳細 - ログインの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



