Java Web開発の実用的な古典
プロジェクト開発では、HTMLの主な機能はデータの表示であり、データの保存構造を標準化するにはXMLを使用する必要があります。 XML には独自の構文があり、すべてのマークアップ要素はユーザーが任意に定義できます。
1. XML を理解する
XML (eXtended Markup Language、拡張可能なマークアップ言語) は、XML を使用すると便利なクロスプラットフォーム、クロスネットワーク、クロスプログラム言語のデータ記述メソッドを提供します。データ交換、システム構成、コンテンツ管理などの共通機能を実装します。
XML は HTML に似ており、どちらもマークアップ言語です。最大の違いは、HTML の要素は固定されており、主に表示に焦点を当てているのに対し、XML 言語のタグはユーザーによってカスタマイズされ、主にデータの保存に焦点を当てていることです。
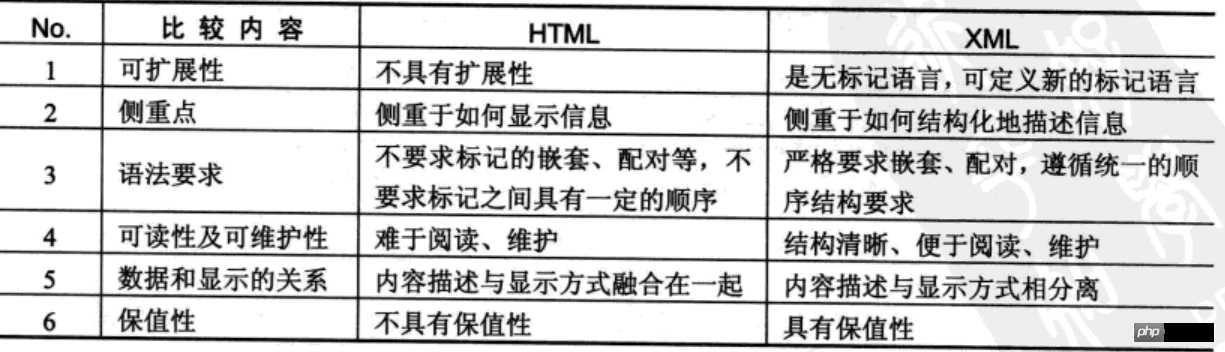
XMLとHTMLの比較
実際、すべてのXMLファイルは、先頭領域とデータ領域という2つの部分グループ化で構成されています。
リーダー領域: XML ページのいくつかの 属性 を指定します。次の 3 つの属性があります:
version: 使用されている XML バージョンを示します (現在 1.0)。
エンコーディング: ページで使用されるテキストエンコーディング。中国語がある場合は、エンコーディングを指定する必要があります。
スタンドアロン: この XML ファイルが独立して実行されるかどうかにかかわらず、表示する必要がある場合は CSS または XSL を使用して制御できます。
属性が表示される順序は固定されており、バージョン、エンコーディング、スタンドアロンの順序が間違っていると、XML でエラーが発生します。
1 | <?xml version="1.0" encoding="GB2312" standalone="no"?>
|
ログイン後にコピー
データ領域: すべてのデータ領域にはルート要素が必要です。複数のサブ要素を 1 つのルート要素に格納できますが、各要素は大文字と小文字を区別する必要があります。
XML 言語は、ファイル データを識別するための CDATA タグを提供します。XML パーサーは、データ内のシンボルやタグを解析せず、元のデータをそのままアプリに渡します。
CDATA 構文形式:
2. XML 解析
XML ファイルでは、内容の多くが説明情報であるため、XML ドキュメントを取得した後、このアプリケーションを使用して要素の定義名に従って対応する内容を抽出しますこのような操作は XML 解析と呼ばれます。
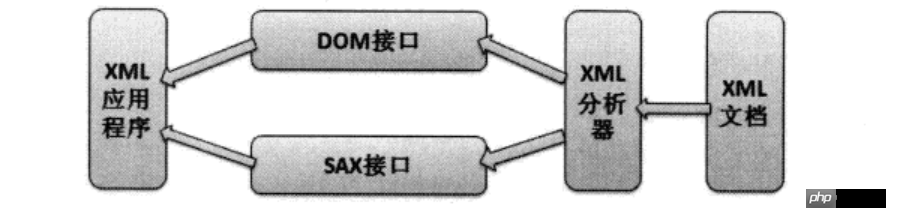
XML 解析では、W3C は SAX と DOM という 2 つの解析メソッドを定義しています。これら 2 つの解析メソッドのプログラム操作は次のとおりです:

XML 解析操作
XML ドキュメントを処理する代わりに、XML パーサーは最初に XML ドキュメントを分析し、次にアプリケーションは XML パーサーによって提供される DOM インターフェイス または SAX インターフェイスを介して分析構造を操作し、それによって間接的に XML ドキュメントにアクセスします。
2.1. DOM 解析操作
アプリケーションでは、DOM に基づく XML パーサー (Document Object Model、DocumentObjectModel) が XML ドキュメントをオブジェクト モデルのコレクション (一般的に) に変換します。 DOM ツリーと呼ばれる)、アプリケーション Cheng Xun は、このオブジェクト モデルの操作を通じて XML 文書データの操作を実現します。 DOM インターフェイスを介して、アプリケーションはいつでも XML ドキュメント内のデータの任意の部分にアクセスできるため、DOM インターフェイスを利用するこのメカニズムはランダム アクセス メカニズムとも呼ばれます。
DOM パーサーは XML ドキュメント全体を DOM ツリーに変換してメモリに格納するため、ドキュメントが大きい場合や複雑な構造がある場合、メモリ要件が比較的高く、複雑な構造のツリーを走査するのも作業になります時間のかかる操作。
DOM 操作 は、すべての XML ファイルをメモリ内の DOM ツリーに変換します。
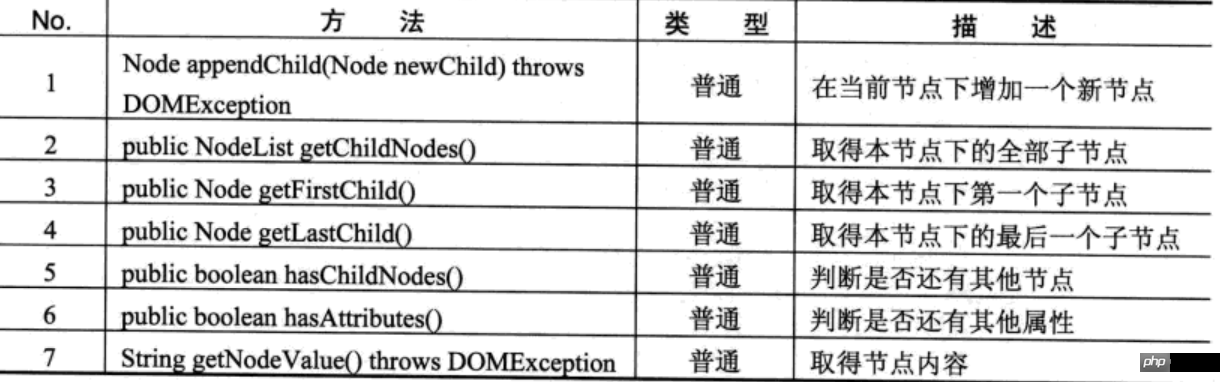
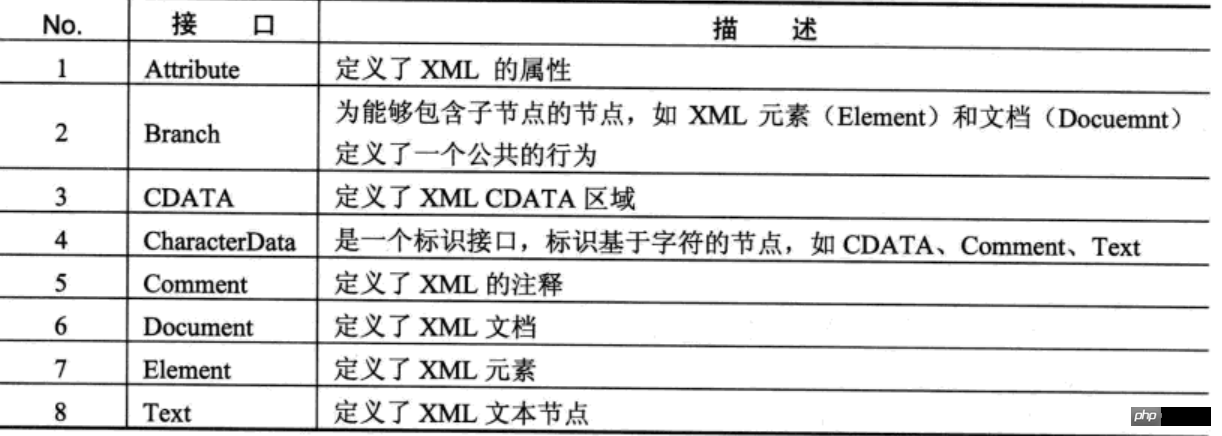
DOM 解析には次の 4 つのコア操作インターフェイスがあります:
Documentインターフェースの一般的なメソッド
Node接口的常用方法
NodeList接口的常用方法
出以上4个核心接口外,如果一个程序需要进行DOM解析读操作,则需要按如下步骤进行:
(1)建立DocumentBuilderFactory:DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
(2)建立DocumentBuilder:DocumentBuilder builder = factory.newDocumentBuilder();
(3)建立Document:Document doc= builder.parse("要读取的文件路径");
(4)建立NodeList:NodeList nl = doc.getElementsByTagName("读取节点");
(5)进行XML信息读取。
1 2 3 4 5 6 7 8 9 10 11 12 13 | <?xml version="1.0" encoding="GBK"?>
<addresslist>
<linkman>
<name>小明</name>
<email>asaasa@163.com</email>
</linkman>
<linkman>
<name>小张</name>
<email>xiaoli@163.com</email>
</linkman>
</addresslist>
|
ログイン後にコピー
DOM完成XML的读取。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | package com.demo;
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class XmlDomDemo {
public static void main(String[] args) {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = null;
try {
builder = factory.newDocumentBuilder();
} catch (ParserConfigurationException e) {
e.printStackTrace();
}
Document doc = null;
try {
doc = builder.parse("xml_demo.xml");
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
NodeList nl = doc.getElementsByTagName("linkman");
for (int i = 0; i < nl.getLength(); i++) {
Element element = (Element) nl.item(i);
System.out.println("姓名:" + element.getElementsByTagName("name").item(0).getFirstChild().getNodeValue());
System.out.println("邮箱:" + element.getElementsByTagName("email").item(0).getFirstChild().getNodeValue());
}
}
}
|
ログイン後にコピー
DOM完成XML的文件输出。
此时就需要使用DOM操作中提供的各个接口(如Element接口)并手工设置各个节点的关系,同时在创建Document对象时就必须使用newDocument()方法建立一个新的DOM树。
如果现在需要将XML文件保存在硬盘上,则需要使用TransformerFactory、Transformer、DOMSource、StreamResult 4个类完成。
TransformerFactory类:取得一个Transformer类的实例对象。
DOMSource类:接收Document对象。
StreamResult 类:指定要使用的输出流对象(可以向文件输出,也可以向指定的输出流输出)。
Transformer类:通过该类完成内容的输出。
StreamResult类的构造方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 | package com.demo;
import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
public class XmlDemoWrite {
public static void main(String[] args) {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = null;
try {
builder = factory.newDocumentBuilder();
} catch (ParserConfigurationException e) {
e.printStackTrace();
}
Document doc = null;
doc = builder.newDocument();
Element addresslist = doc.createElement("addresslist");
Element linkman = doc.createElement("linkman");
Element name = doc.createElement("name");
Element email = doc.createElement("email");
name.appendChild(doc.createTextNode("小明"));
email.appendChild(doc.createTextNode("xiaoming@163.com"));
linkman.appendChild(name);
linkman.appendChild(email);
addresslist.appendChild(linkman);
doc.appendChild(addresslist);
TransformerFactory tf = TransformerFactory.newInstance();
Transformer t = null;
try {
t = tf.newTransformer();
} catch (TransformerConfigurationException e) {
e.printStackTrace();
}
t.setOutputProperty(OutputKeys.ENCODING, "GBK");
DOMSource source = new DOMSource(doc);
StreamResult result = new StreamResult(new File("xml_wirte.xml"));
try {
t.transform(source, result);
System.out.println("yes");
} catch (TransformerException e) {
e.printStackTrace();
}
}
}
|
ログイン後にコピー
生成文档:
1 2 3 4 5 6 7 8 9 | <?xml version="1.0" encoding="GBK" standalone="no"?>
<addresslist>
<linkman>
<name>小明</name>
<email>xiaoming@163.com</email>
</linkman>
</addresslist>
|
ログイン後にコピー
2.2、SAX解析操作
SAX(Simple APIs for XML,操作XML的简单接口)与DOM操作不同的是,SAX采用的是一种顺序的模式进行访问,是一种快速读取XML数据的方式。
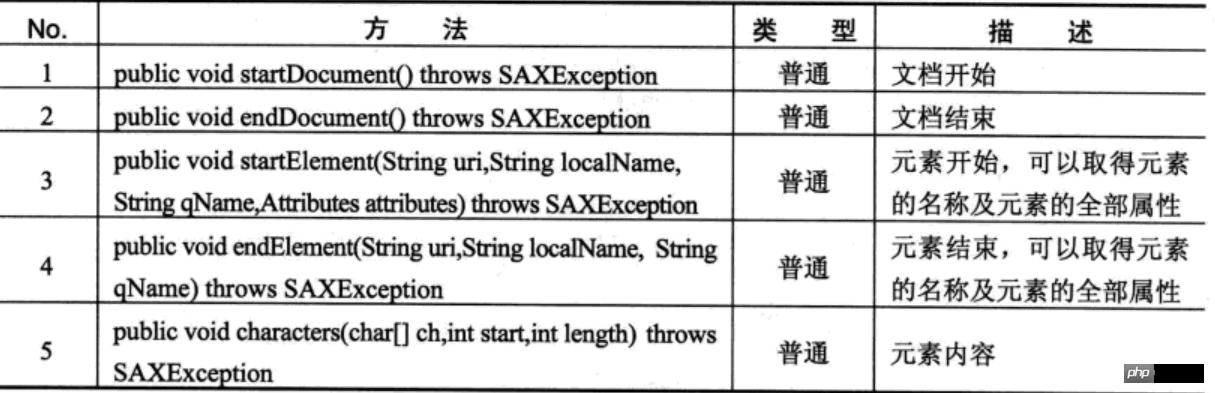
当使用SAX 解析器进行操作时会触发一系列的事件。
SAX主要事件
当扫描到文档(Document)开始与结束、元素(Element)开始与结束时都会调用相关的处理方法,并由这些操作方法做出相应的操作,直到整个文档扫描结束。
如果在开发中想要使用SAX解析,则首先应该编写一个SAX解析器,再直接定义一个类,并使该类继承自DefaultHandler类,同时覆写上述的表中的方法即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | package com.sax.demo;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class XmlSax extends DefaultHandler {
@Override
public void startDocument() throws SAXException {
System.out.println("<?xml version=\"1.0\" encoding=\"GBK\"?>");
}
@Override
public void endDocument() throws SAXException {
System.out.println("\n 文档读取结束。。。");
}
@Override
public void startElement(String url, String localName, String name,
Attributes attributes) throws SAXException {
System.out.print("<");
System.out.print(name);
if (attributes != null) {
for (int x = 0; x < attributes.getLength(); x++) {
System.out.print("" + attributes.getQName(x) + "=\"" + attributes.getValue(x) + "\"");
}
}
System.out.print(">");
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
System.out.print(new String(ch, start, length));
}
@Override
public void endElement(String url, String localName, String name)
throws SAXException {
System.out.print("</");
System.out.print(name);
System.out.print(">");
}
}
|
ログイン後にコピー
建荔湾SAX解析器后,还需要建立SAXParserFactory和SAXParser对象,之后通过SAXPaeser的parse()方法指定要解析的XML文件和指定的SAX解析器。
建立要读取的文件:sax_demo.xml
1 2 3 4 5 6 7 8 9 10 11 | <?xml version="1.0" encoding="GBK"?>
<addresslist>
<linkman id="xm">
<name>小明</name>
<email>xiaoming@163.com</email>
</linkman>
<linkman id="xl">
<name>小李</name>
<email>xiaoli@163.com</email>
</linkman>
</addresslist>
|
ログイン後にコピー
使用SAX解析器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | package com.sax.demo;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
public class SaxTest {
public static void main(String[] args) throws Exception {
SAXParserFactory factory = SAXParserFactory.newInstance();
SAXParser parser = factory.newSAXParser();
parser.parse("sax_demo.xml", new XmlSax());
}
}
|
ログイン後にコピー
通过上面的程序可以发现,使用SAX解析比使用DOM解析更加容易。
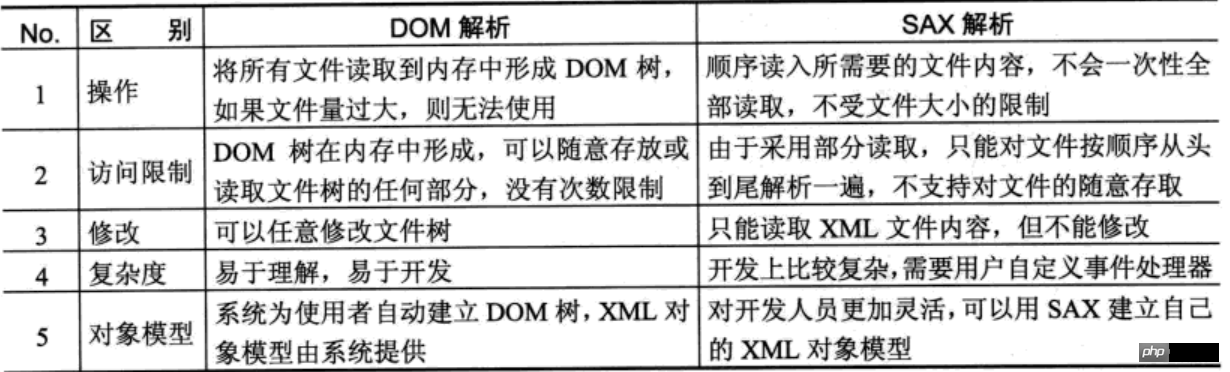
DOM解析与SAX解析的区别
有两者的特点可以发现两者的区别:
DOM解析适合于对文件进行修改和随机存取的操作,但是不适合于大型文件的操作。
SAX采用部分读取的方式,所以可以处理大型文件,而且只需要从文件中读取特定内容。SAX解析可以由用户自己建立自己的对象模型。
2.3、XML解析的好帮手:jdom
jdom是使用Java编写的,用于读、写、操作XML的一套组件。
jdom = dom 修改文件的有点 + SAX读取快速的优点
jdom的主要操作类
使用jdom生成XML文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | package com.jdom.demo;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import org.jdom.Attribute;
import org.jdom.Document;
import org.jdom.Element;
import org.jdom.output.XMLOutputter;
public class WriteXml {
public static void main(String[] args) {
Element addresslist = new Element("addresslist");
Element linkman = new Element("linkman");
Element name = new Element("name");
Element email = new Element("email");
Attribute id = new Attribute("id", "xm");
Document doc = new Document(addresslist);
name.setText("小明");
email.setText("xiaoming@163.com");
name.setAttribute(id);
linkman.addContent(name);
linkman.addContent(email);
addresslist.addContent(linkman);
XMLOutputter out = new XMLOutputter();
out.setFormat(out.getFormat().setEncoding("GBK"));
try {
out.output(doc, new FileOutputStream("jdom_write.xml"));
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
|
ログイン後にコピー
1 2 3 4 5 6 7 8 9 | <?xml version="1.0" encoding="GBK"?>
<addresslist>
<linkman>
<name id="xm">小明</name>
<email>xiaoming@163.com</email>
</linkman>
</addresslist>
|
ログイン後にコピー
使用jdom读取XML文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | package com.jdom.demo;
import java.io.IOException;
import java.util.List;
import org.jdom.Document;
import org.jdom.Element;
import org.jdom.JDOMException;
import org.jdom.input.SAXBuilder;
public class ReadXml {
public static void main(String[] args) throws JDOMException, IOException {
SAXBuilder builder = new SAXBuilder();
Document readDoc = builder.build("jdom_write.xml");
Element stu = readDoc.getRootElement();
List list = stu.getChildren("linkman");
for (int i = 0; i < list.size(); i++) {
Element e = (Element) list.get(i);
String name = e.getChildText("name");
String id = e.getChild("name").getAttribute("id").getValue();
String email = e.getChildText("email");
System.out.println("----联系人----");
System.out.println("姓名:" + name + "编号:" + id);
System.out.println("Email:" + email);
}
}
}
|
ログイン後にコピー
jdom是一种常见的操作组件
在实际的开发中使用非常广泛。
2.4、解析工具:dom4j
dom4j也是一组XML操作组件包,主要用来读写XML文件,由于dom4j性能优异、功能强大,且具有易用性,所以现在已经被广泛地应用开来。如,Hibernate、Spring框架中都使用了dom4j进行XML的解析操作。
开发时需要引入的jar包:dom4j-1.6.1.jar、lib/jaxen-1.1-beta-6.jar
dom4j中的所用操作接口都在org.dom4j包中定义。其他包根据需要把选择使用。
dom4j的主要接口
用dom4j生成XML文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | package com.dom4j.demo;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.XMLWriter;
public class Dom4jWrite {
public static void main(String[] args) {
Document doc = DocumentHelper.createDocument();
Element addresslist = doc.addElement("addresslist");
Element linkman = addresslist.addElement("linkman");
Element name = linkman.addElement("name");
Element email = linkman.addElement("email");
name.setText("小明");
email.setText("xiaoming@163.com");
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("GBK");
try {
XMLWriter writer = new XMLWriter(new FileOutputStream(new File(
"dom4j_demo.xml")), format);
writer.write(doc);
writer.close();
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
|
ログイン後にコピー
1 2 3 4 5 6 7 8 9 10 | <?xml version="1.0" encoding="GBK"?>
<addresslist>
<linkman>
<name>小明</name>
<email>xiaoming@163.com</email>
</linkman>
</addresslist>
|
ログイン後にコピー
用dom4j读取XML文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | package com.dom4j.demo;
import java.io.File;
import java.util.Iterator;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class Dom4jRead {
public static void main(String[] args) {
File file = new File("dom4j_demo.xml");
SAXReader reader = new SAXReader();
Document doc = null;
try {
doc = reader.read(file);
} catch (DocumentException e) {
e.printStackTrace();
}
Element root = doc.getRootElement();
Iterator iter = root.elementIterator();
while (iter.hasNext()) {
Element linkman = (Element) iter.next();
System.out.println("姓名:"+linkman.elementText("name"));
System.out.println("邮件地址:"+linkman.elementText("email"));
}
}
}
|
ログイン後にコピー
小结
以上がXML 解析の基本の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。






















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



