

pandasライブラリで導入されたDataFrameの基本操作

リスト白抜き文字を削除するには? 最も簡単な方法: new
_list = [ x for x in li if x != '' ]
このパートでは主に、前の 2 つのデータ構造に基づいて pandas の基本操作を学習します。
设有DataFrame结果的数据a如下所示: a b c one 4 1 1 two 6 2 0 three 6 1 6
オブジェクト
を表示する方法はシリーズにも適用されます)
1. DataFramea=DataFrame(data);a の最初の xx 行または最後の xx 行を表示します。
head
(6) は、head() にパラメータがない場合、データの最初の 6 行を表示することを意味します。 a.tail(6) は、データの最後の 6 行を表示することを意味します。tail() にパラメータがない場合は、すべてのデータが表示されます。
a.index; a.columns; a.values のインデックス、列、値を表示します
3.describe()
a.describe () 個数、平均値、標準偏差、各分位数などを含む、データの各列の統計を実行します。 4. データを転置します
a.
5. 軸を並べ替えます
a.
_index(axis=1,ascending=False);
axis=1 は並べ替えall を意味します列、および次の数字もそれに応じて移動します。次の ascending=False は降順で並べ替えることを意味し、パラメータが欠落している場合のデフォルトは昇順です。
6. DataFrame 内の値を並べ替えます a.sort(columns='x')
2. オブジェクトを選択します
1. 特定の列と行のデータを選択します
a['x'] このメソッドは一度に 1 つの列しか返せないことに注意してください。 。
a.x は a['x'] と同じ意味です。行データを取得し、[] でスライスして選択します。例: a[0:3] は最初の 3 行のデータを返します。
2.loc はラベルを通じてデータを選択します
a.loc['one'] はデフォルトで
動作
a.loc[:,['a',' b'] ] は、列が a と b であるすべての行と列を選択することを意味します。
a.loc[['one','two'],['a','b']] は、'one' と'two' と列 a と b を持つ列 a.loc['one','a'] と a.loc[['one'],['a']] は同じ効果がありますが、前者は対応する値のみを表示し、後者は対応する行と列のラベルを表示します。
a.iloc[1:2,1:2] は、最初の行と最初の列 (スライスの後) にデータを表示します。値が取得できない)
a.iloc[1:2] つまり、後続の列の値が取得できない場合、デフォルトで行位置 1 のデータが選択されます;
a.iloc[[0, 2],[1 ,2]] つまり、行位置と列位置に対応するデータを自由に選択できます。
4. 条件を使用して選択します
個別の列を使用してデータを選択します
a[a.c>0] は、列 c で 0 より大きいデータを選択することを意味しますデータを選択する場所を使用しますa[a> ] テーブルは、a 内の 0 より大きいすべてのデータを直接選択します
isin() を使用して、特定の列に特定の値を含む行を選択します
copy
()
3. 設定値(割り当て)
上記の選択操作を元に、直接割り当て動作を割り当てることができます。 例 a.loc[:,['a','c']]=9 は、列 a と c のすべての行の値を 9 に設定しますa.iloc[:,[1,3]]= 9も a列とc列のすべての行の値を9に設定することを意味します
a[a>0]=-aはすべての数値を変換することを意味します4. 欠損値の処理
pandas では、np.nan を使用して欠損値を置き換えます。これらの値はデフォルトでは計算に含まれません。
1.reindex() メソッド
は、指定された軸上の
index
変更/追加/削除するために使用され、元のデータのコピーを返します。
a.reindex(index=list(a.index)+['five'],columns=list(a.columns)+['d'])a.reindex(index=['one','five'],columns=list(a.columns)+['d'])
即用index=[]表示对index进行操作,columns表对列进行操作。
2.对缺失值进行填充
a.fillna(value=x)
表示用值为x的数来对缺失值进行填充
3.去掉包含缺失值的行
a.dropna(how='any')
表示去掉所有包含缺失值的行
五、合并
1.contact
contact(a1,axis=0/1,keys=['xx','xx','xx',...]),其中a1表示要进行进行连接的列表数据,axis=1时表横着对数据进行连接。axis=0或不指定时,表将数据竖着进行连接。a1中要连接的数据有几个则对应几个keys,设置keys是为了在数据连接以后区分每一个原始a1中的数据。
例:a1=[b['a'],b['c']]
result=pd.concat(a1,axis=1,keys=['1','2'])
2.Append 将一行或多行数据连接到一个DataFrame上
a.append(a[2:],ignore_index=True)
表示将a中的第三行以后的数据全部添加到a中,若不指定ignore_index参数,则会把添加的数据的index保留下来,若ignore_index=Ture则会对所有的行重新自动建立索引。
3.merge类似于SQL中的join
设a1,a2为两个dataframe,二者中存在相同的键值,两个对象连接的方式有下面几种:
(1)内连接,pd.merge(a1, a2, on='key')
(2)左连接,pd.merge(a1, a2, on='key', how='left')
(3)右连接,pd.merge(a1, a2, on='key', how='right')
(4)外连接, pd.merge(a1, a2, on='key', how='outer')
至于四者的具体差别,具体学习参考sql中相应的语法。
六、分组(groupby)
用pd.date_range函数生成连续指定天数的的日期
pd.date_range('20000101',periods=10)
def shuju():
data={
'date':pd.date_range('20000101',periods=10),
'gender':np.random.randint(0,2,size=10),
'height':np.random.randint(40,50,size=10),
'weight':np.random.randint(150,180,size=10)
}
a=DataFrame(data)
print(a)
date gender height weight
0 2000-01-01 0 47 165
1 2000-01-02 0 46 179
2 2000-01-03 1 48 172
3 2000-01-04 0 45 173
4 2000-01-05 1 47 151
5 2000-01-06 0 45 172
6 2000-01-07 0 48 167
7 2000-01-08 0 45 157
8 2000-01-09 1 42 157
9 2000-01-10 1 42 164
用a.groupby('gender').sum()得到的结果为: #注意在python中groupby(''xx)后要加sum(),不然显示
不了数据对象。
gender height weight
0 256 989
1 170 643此外用a.groupby('gender').size()可以对各个gender下的数目进行计数。
所以可以看到groupby的作用相当于:
按gender对gender进行分类,对应为数字的列会自动求和,而为字符串类型的列则不显示;当然也可以同时groupby(['x1','x2',...])多个字段,其作用与上面类似。
七、Categorical按某一列重新编码分类
如六中要对a中的gender进行重新编码分类,将对应的0,1转化为male,female,过程如下:
a['gender1']=a['gender'].astype('category')
a['gender1'].cat.categories=['male','female'] #即将0,1先转化为category类型再进行编码。
print(a)得到的结果为:
date gender height weight gender1
0 2000-01-01 1 40 163 female
1 2000-01-02 0 44 177 male
2 2000-01-03 1 40 167 female
3 2000-01-04 0 41 161 male
4 2000-01-05 0 48 177 male
5 2000-01-06 1 46 179 female
6 2000-01-07 1 42 154 female
7 2000-01-08 1 43 170 female
8 2000-01-09 0 46 158 male
9 2000-01-10 1 44 168 female所以可以看出重新编码后的编码会自动增加到dataframe最后作为一列。
八、相关操作
描述性统计:
1.a.mean() 默认对每一列的数据求平均值;若加上参数a.mean(1)则对每一行求平均值;
2.统计某一列x中各个值出现的次数:a['x'].value_counts();
3.对数据应用函数
a.apply(lambda x:x.max()-x.min())
表示返回所有列中最大值-最小值的差。
4.字符串相关操作
a['gender1'].str.lower() 将gender1中所有的英文大写转化为小写,注意dataframe没有str属性,只有series有,所以要选取a中的gender1字段。
九、时间序列
在六中用pd.date_range('xxxx',periods=xx,freq='D/M/Y....')函数生成连续指定天数的的日期列表。
例如pd.date_range('20000101',periods=10),其中periods表示持续频数;
pd.date_range('20000201','20000210',freq='D')也可以不指定频数,只指定起始日期。
此外如果不指定freq,则默认从起始日期开始,频率为day。其他频率表示如下:
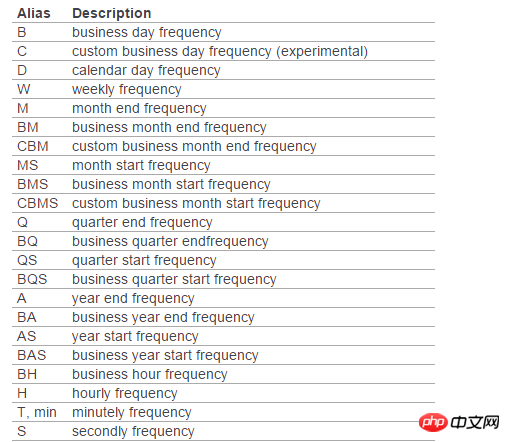
1.png
十、画图(plot)
在pycharm中首先要:import matplotlib.pyplot as plt
a=Series(np.random.randn(1000),index=pd.date_range('20100101',periods=1000))
b=a.cumsum()
b.plot()
plt.show() #最后一定要加这个plt.show(),不然不会显示出图来。
2.PNG
也可以使用下面的代码来生成多条时间序列图:
a=DataFrame(np.random.randn(1000,4),index=pd.date_range('20100101',periods=1000),columns=list('ABCD'))
b=a.cumsum()
b.plot()
plt.show()
3.png
十一、导入和导出文件
写入和读取excel文件
虽然写入excel表时有两种写入xls和csv,但建议少使用csv,不然在表中调整数据格式时,保存时一直询问你是否保存新格式,很麻烦。而在读取数据时,如果指定了哪一张sheet,则在pycharm又会出现格式不对齐。
还有将数据写入表格中时,excel会自动给你在表格最前面增加一个字段,对数据行进行编号。
a.to_excel(r'C:\\Users\\guohuaiqi\\Desktop\\2.xls',sheet_name='Sheet1') a=pd.read_excel(r'C:\\Users\\guohuaiqi\\Desktop\\2.xls','Sheet1',na_values=['NA']) 注意sheet_name后面的Sheet1中的首字母大写;读取数据时,可以指定读取哪一张表中的数据,而 且对缺失值补上NA。 最后再附上写入和读取csv格式的代码: a.to_csv(r'C:\\Users\\guohuaiqi\\Desktop\\1.csv',sheet_name='Sheet1') a=pd.read_csv(r'C:\\Users\\guohuaiqi\\Desktop\\1.csv',na_values=['NA'])
以上がpandasライブラリで導入されたDataFrameの基本操作の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7542
7542
 15
1381
52
83
11
21
86
15
1381
52
83
11
21
86

 PHPおよびPython:コードの例と比較
Apr 15, 2025 am 12:07 AM
PHPおよびPython:コードの例と比較
Apr 15, 2025 am 12:07 AM
PHPとPythonには独自の利点と短所があり、選択はプロジェクトのニーズと個人的な好みに依存します。 1.PHPは、大規模なWebアプリケーションの迅速な開発とメンテナンスに適しています。 2。Pythonは、データサイエンスと機械学習の分野を支配しています。
 CentosでPytorchモデルを訓練する方法
Apr 14, 2025 pm 03:03 PM
CentosでPytorchモデルを訓練する方法
Apr 14, 2025 pm 03:03 PM
CentOSシステムでのPytorchモデルの効率的なトレーニングには手順が必要であり、この記事では詳細なガイドが提供されます。 1。環境の準備:Pythonおよび依存関係のインストール:Centosシステムは通常Pythonをプリインストールしますが、バージョンは古い場合があります。 YumまたはDNFを使用してPython 3をインストールし、PIP:sudoyumupdatepython3(またはsudodnfupdatepython3)、pip3install-upgradepipをアップグレードすることをお勧めします。 cuda and cudnn(GPU加速):nvidiagpuを使用する場合は、cudatoolをインストールする必要があります
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
 CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
Pytorch GPUアクセラレーションを有効にすることで、CentOSシステムでは、PytorchのCUDA、CUDNN、およびGPUバージョンのインストールが必要です。次の手順では、プロセスをガイドします。CUDAおよびCUDNNのインストールでは、CUDAバージョンの互換性が決定されます。NVIDIA-SMIコマンドを使用して、NVIDIAグラフィックスカードでサポートされているCUDAバージョンを表示します。たとえば、MX450グラフィックカードはCUDA11.1以上をサポートする場合があります。 cudatoolkitのダウンロードとインストール:nvidiacudatoolkitの公式Webサイトにアクセスし、グラフィックカードでサポートされている最高のCUDAバージョンに従って、対応するバージョンをダウンロードしてインストールします。 cudnnライブラリをインストールする:
 Python vs. JavaScript:コミュニティ、ライブラリ、リソース
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript:コミュニティ、ライブラリ、リソース
Apr 15, 2025 am 12:16 AM
PythonとJavaScriptには、コミュニティ、ライブラリ、リソースの観点から、独自の利点と短所があります。 1)Pythonコミュニティはフレンドリーで初心者に適していますが、フロントエンドの開発リソースはJavaScriptほど豊富ではありません。 2)Pythonはデータサイエンスおよび機械学習ライブラリで強力ですが、JavaScriptはフロントエンド開発ライブラリとフレームワークで優れています。 3)どちらも豊富な学習リソースを持っていますが、Pythonは公式文書から始めるのに適していますが、JavaScriptはMDNWebDocsにより優れています。選択は、プロジェクトのニーズと個人的な関心に基づいている必要があります。
 ミニオペンCentosの互換性
Apr 14, 2025 pm 05:45 PM
ミニオペンCentosの互換性
Apr 14, 2025 pm 05:45 PM
MINIOオブジェクトストレージ:CENTOSシステムの下での高性能展開Minioは、Amazons3と互換性のあるGO言語に基づいて開発された高性能の分散オブジェクトストレージシステムです。 Java、Python、JavaScript、Goなど、さまざまなクライアント言語をサポートしています。この記事では、CentosシステムへのMinioのインストールと互換性を簡単に紹介します。 Centosバージョンの互換性Minioは、Centos7.9を含むがこれらに限定されない複数のCentosバージョンで検証されています。
 Centosの下でPytorchバージョンを選択する方法
Apr 14, 2025 pm 02:51 PM
Centosの下でPytorchバージョンを選択する方法
Apr 14, 2025 pm 02:51 PM
CentOSでPytorchバージョンを選択する場合、次の重要な要素を考慮する必要があります。1。CUDAバージョンの互換性GPUサポート:NVIDIA GPUを使用してGPU加速度を活用したい場合は、対応するCUDAバージョンをサポートするPytorchを選択する必要があります。 NVIDIA-SMIコマンドを実行することでサポートされているCUDAバージョンを表示できます。 CPUバージョン:GPUをお持ちでない場合、またはGPUを使用したくない場合は、PytorchのCPUバージョンを選択できます。 2。PythonバージョンPytorch
 NginxをCentosにインストールする方法
Apr 14, 2025 pm 08:06 PM
NginxをCentosにインストールする方法
Apr 14, 2025 pm 08:06 PM
NGINXのインストールをインストールするには、次の手順に従う必要があります。開発ツール、PCRE-Devel、OpenSSL-Develなどの依存関係のインストール。 nginxソースコードパッケージをダウンロードし、それを解凍してコンパイルしてインストールし、/usr/local/nginxとしてインストールパスを指定します。 nginxユーザーとユーザーグループを作成し、アクセス許可を設定します。構成ファイルnginx.confを変更し、リスニングポートとドメイン名/IPアドレスを構成します。 nginxサービスを開始します。依存関係の問題、ポート競合、構成ファイルエラーなど、一般的なエラーに注意する必要があります。パフォーマンスの最適化は、キャッシュをオンにしたり、ワーカープロセスの数を調整するなど、特定の状況に応じて調整する必要があります。
