

CBOのSQL最適化問題を解く(画像と文章で詳しく解説)

この共有の概要:
CBO オプティマイザーの落とし穴とは何ですか
CBO オプティマイザーの落とし穴に対する解決策
SQL 監査を強化してパフォーマンスの問題を芽のうちに摘み取ります
-
オンサイト FAQ を共有
CBO (Cost Based Optimizer) オプティマイザーは現在 Oracle で広く使用されており、統計情報、クエリ変換などを使用して、さまざまな可能なアクセス パスのコストを計算し、複数の代替実行プランを生成します。 , Oracle は最終的に、最適な実行計画として最低コストを選択します。 「古代」の時代の RBO (Rule Based Optimizer) と比較すると、明らかにデータベースの実際の状況により即しており、より多くのアプリケーション シナリオに適応できます。ただし、CBO は非常に複雑であるため、日常的な最適化プロセスでは解決できない現実的な問題やバグが多数あり、現時点では、どのように統計情報を収集しても正しい実行計画に従えない状況に遭遇する可能性があります。 、CBOを騙した可能性があります。
この共有では主に、CBO の落とし穴に対する解決策を探るための導入として、一般的な日常のオプティマイザーの問題を使用します。
1. CBO オプティマイザーの落とし穴は何ですか? まず CBO オプティマイザーのコンポーネントを見てみましょう:
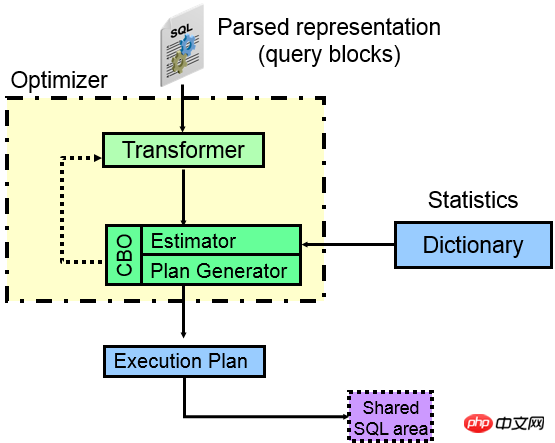 上の図からわかるように、SQL が ORACLE に入るとき、各部分は実際にはたとえば、サブクエリはクエリ ブロックになり、外部クエリはクエリ ブロックになります。その場合、ORACLE オプティマイザは各クエリ ブロック内で何が起こるかを決定します。アクセス パスはより優れています (
上の図からわかるように、SQL が ORACLE に入るとき、各部分は実際にはたとえば、サブクエリはクエリ ブロックになり、外部クエリはクエリ ブロックになります。その場合、ORACLE オプティマイザは各クエリ ブロック内で何が起こるかを決定します。アクセス パスはより優れています (
、フル テーブル、パーティションを使用しますか?)。2 つ目は、各クエリ ブロック間でどのような種類の JOIN メソッドと JOIN 順序を使用するかであり、最終的にどの実行プランが優れているかを計算します。 オプティマイザーの中核は、クエリコンバーター、コスト見積り、および実行計画
ジェネレーターです。 トランスフォーマー (クエリ トランスフォーマー):
図からわかるように、オプティマイザーの最初のコア デバイスはクエリ トランスフォーマーです。クエリ トランスフォーマーの主な機能は、さまざまなクエリ ブロック間の関係を調査し、それらを分析することです。構文 SQL は意味的にも同等に書き換えられ、書き換えられた SQL はコア デバイスのコスト推定機能と実行プラン ジェネレーターによる処理が容易になり、それによって統計情報を使用して最適な実行プランを生成します。
クエリ コンバータには、オプティマイザでヒューリスティック クエリ変換 (ルールベース) と COST ベースのクエリ変換という 2 つの方法があります。 ヒューリスティックなクエリ変換は一般に比較的単純なステートメントであり、コストベースのクエリ変換は一般により複雑です。つまり、ルールベースのクエリに準拠する ORACLE はどのような状況でもクエリ変換を実行し、要件を満たさない ORACLE は考慮する可能性があります。コストベースのクエリ変換。ヒューリスティック クエリ変換は長い歴史があり、問題が少なく、CBO オプティマイザーと密接に関連しているため、一般的にクエリ変換を行わないクエリ変換よりも効率が高く、10G で導入されました。したがって、日常的な最適化プロセスでは、クエリ変換が失敗すると、Oracle が元の SQL をより適切な構造の SQL に変換できないため、多くのバグが発生します。 (プロセッサ処理)、明らかに、選択できる実行パスがはるかに少なくなります。たとえば、サブクエリを UNNEST にできない場合、それは多くの場合、惨事の始まりです。実際、Oracle がクエリ変換で最も行うことは、HASH JOIN などのさまざまな効率的な JOIN メソッドを使用できるように、さまざまなクエリを JOIN メソッドに変換することです。
クエリ変換には 30 を超える方法があります。いくつかの一般的なヒューリスティックおよび COST ベースのクエリ変換を以下に示します。
ヒューリスティック クエリ変換 (一連の RULE):
RBO の場合には、多くのヒューリスティック クエリ変換がすでに存在します。一般的なものは次のとおりです:
Simple View merge (シンプル ビュー マージ)、SU (サブクエリのネスト解除サブクエリ拡張)、OJPPD (古いスタイルの結合述語プッシュダウン古い結合述語プッシュ方式)、FPD (フィルター プッシュダウン フィルター述語) プッシュ) 、OR Expansion(OR拡張)、OBYE(Order by Elimination)、JE(Join Elimination接続の削除または接続内のテーブルの削除)、Transitive Predicate(述語転送)などの技術。
COST ベースのクエリ変換 (COST によって計算):
複雑なステートメントの COST ベースのクエリ変換、一般的なものは次のとおりです:
CVM (複雑なビューのマージ、複雑なビューのマージ)、JPPD (結合述語プッシュダウン アソシエーション) テクノロジー述語プッシュなど)、DP(個別配置)、GBP(配置によるグループ化)など。
一連のクエリ変換テクノロジーを通じて、元の SQL はオプティマイザーが理解し、分析しやすい SQL に変換され、より多くの述語、接続条件などを使用して最適なプランを取得するという目的を達成できるようになります。 。変換プロセスを問い合わせるには、10053 を通じて詳細情報を取得できます。クエリ変換が成功するかどうかは、バージョン、オプティマイザの制限、暗黙的なパラメータ、パッチなどに関係します。
MOS でクエリ変換を検索すると、たくさんのバグが表示されます:
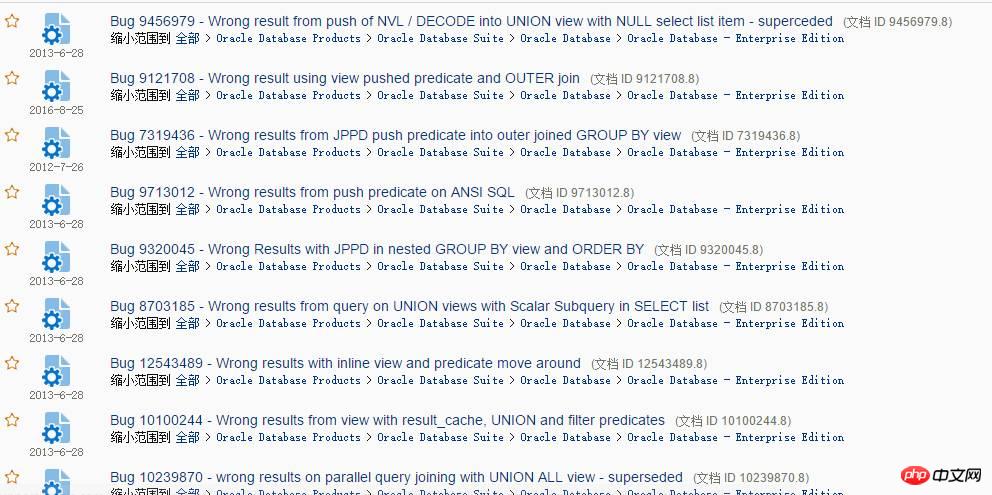
この種のバグに遭遇することはパフォーマンスの問題ではなく、重大なデータの正確性の問題であることが判明しました。もちろん、MOS ではこのようなバグを簡単に見つけることができます。アプリケーションでは、SQL クエリの結果が間違っている可能性があることに気付いた場合は、問題が発生したときに大胆に質問する必要があると思います。非常に正しい考え方です。この種の間違った結果の問題は、データベースのメジャー バージョンのアップグレード プロセス中に発生することがあります。問題には主に 2 つのタイプがあります。 --新しいバージョンのバグに遭遇しました
結果は正しいですが、元の結果は間違っていました。 --新しいバージョンは古いバージョンのバグを修正します
最初の状況は正常ですが、2 番目の状況も存在する可能性があります。検証した結果、結果が間違っていることが判明したというお客様を見たことがあります。古いバージョンの実行計画は間違っていましたが、新しいバージョンの実行計画は正しかった、つまり、長年にわたって間違っていたことが、バージョンアップ後に正しかったことが判明しました。間違っていると考えられていました。
間違った結果が発生した場合、それが非コア関数でない場合、実際には何年も深く埋もれている可能性があります。
Estimator (
Estimator):明らかに、Estimator は統計情報 (テーブル、インデックス、列、パーティションなど) を使用して、対応する実行計画操作の選択性を推定し、それによって対応する操作のカーディナリティを計算します。対応する操作の COST を生成し、最終的に計画全体の COST を計算します。推定者にとって非常に重要なのは、推定 モデル の精度と統計情報の保存の精度です。推定されたモデルがより科学的であればあるほど、より多くの統計情報が実際のデータ分布を反映し、より多くの特殊なデータをカバーできるようになります。生成される COST はより正確になります。
しかし、これは不可能です。例えば、文字列の選択性を計算するとき、ORACLEはRAW
型を数値に変換した後、内部的に文字列をRAW型に変換します。この場合、数値に変換すると文字列が 15 桁を超えるため、内部変換後の結果が類似する可能性があり、最終的に計算の選択性が不正確になります。 プラン ジェネレーター(プラン ジェネレーター):
プラン ジェネレーターは、さまざまなアクセス パス、JOIN メソッド、および JOIN シーケンスを分析して、さまざまな実行プランを生成します。したがって、この部分に問題がある場合、対応する部分のアルゴリズムや制限が不十分である可能性があります。たとえば、JOIN テーブルが多数ある場合、さまざまなアクセス シーケンスの選択肢が等比級数的に増加します。つまり、ORACLE 内では制限があり、すべてを計算することは不可能になります。 たとえば、HASH JOIN アルゴリズムは一般にビッグ データ処理に推奨されるアルゴリズムですが、HASH JOIN には本質的に制限があります。HASH 衝突が発生すると、必然的に効率が大幅に低下します。
CBO オプティマイザーには多くの制限があります。詳細については、「MOS: Oracle Cost Based Optimizer の制限」(文書 ID 212809.1) を参照してください。
2. CBO オプティマイザーの落とし穴への解決策
このセクションでは、主に一般的なオプティマイザーの問題のケースを紹介します。CBO は現在広く使用されているオプティマイザーであるため、それらはすべて CBO に含まれます。質問。
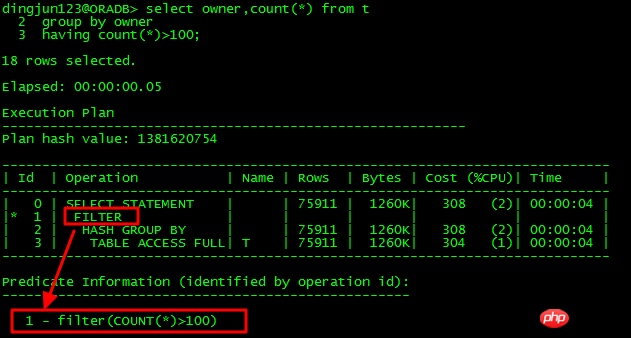
1 FILTER パフォーマンスのキラー問題
FILTER 操作は、実行プランの一般的な操作です。この操作には 2 つの状況があります:
に子ノードが 1 つしかない場合、それは単純なフィルター操作です。
-
複数の子ノードがある場合、NESTED LOOPS 操作と似ていますが、NESTED LOOPS との唯一の違いは、FILTER が繰り返しの一致に対して
loop 検索を実行しないことです。再度実行しますが、既存のものを使用します。その結果、効率が向上します。ただし、繰り返される一致が減り、ループが増えると、FILTER 操作がパフォーマンスに重大な影響を及ぼし、SQL が数日間実行できなくなる可能性があります。 - 単一の子ノード:
 複数の子ノード:
複数の子ノード:
FILTER 複数の子ノードは、主にサブクエリを UNNEST クエリに変換できない場合に発生します。NOT IN サブクエリ、OR と結合されたサブクエリ、複雑なサブクエリなどです。
(1) NOT IN サブクエリのフィルター
まず NOT IN の状況を見てみましょう:
上記の NOT IN サブクエリの場合、サブクエリ object_id に NULL がある場合、11g より前では、メインテーブルとサブテーブルの object_id に同時に NOT NULL 制約がなかった場合、クエリ全体には結果がありません。時間、または IS NOT NULL 制限が追加されていない場合、ORACLE は FILTER を使用します。 11g には、効率を向上させるためにサブクエリを UNNEST できる新しい ANTI NA (NULL AWARE) 最適化機能があります。
unNEST サブクエリの場合は、FILTER を使用し、少なくとも 2 つの子ノードを持ちます。実行プランのもう 1 つの特徴は、述語部分に次の要素が含まれていることです。B1、バインディング 変数 に似たもの、および内部操作は NESTED LOOPS 操作に似ています。 。
11g には、以下に示すように NOT IN 問題に特化して最適化された NULL AWARE があります:
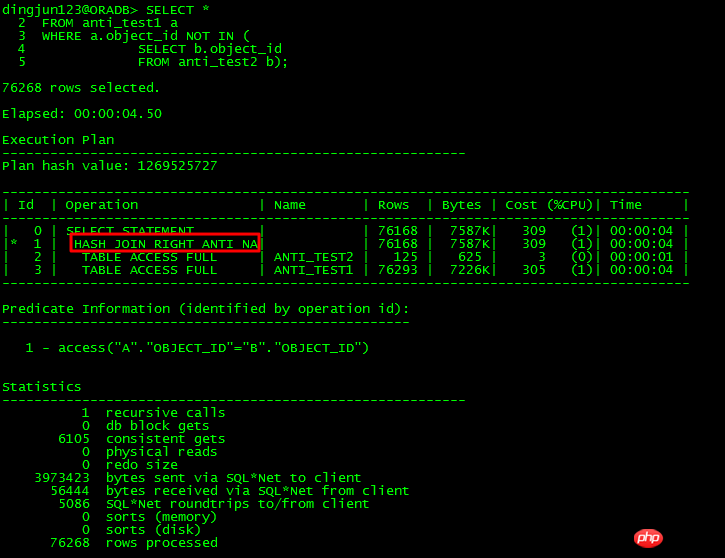
NULL AWARE 操作により、UNNEST できない NOT IN サブクエリを JOIN 形式に変換できるため、効率が大幅に向上します。 11g より前に NOT IN が発生し、UNNEST できない場合はどうすればよいですか?
NOT IN部分のマッチング条件を設定します。この場合、ANTI_TEST1.object_idとANTI_TEST2.object_idの両方にNOT NULL制約が設定されます。
NOT NULL 制約を変更しない場合は、両方の object_id に IS NOT NULL 条件を追加する必要があります。
「存在しない」に変更されました。
ANTI JOINフォームに変更しました。
上記の 4 つの方法は、ほとんどの場合、オプティマイザーに JOIN を使用させるという目的を達成できます。
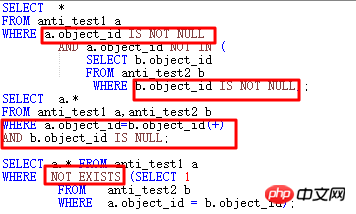
上記の実行計画は、以下に示すように同じです。
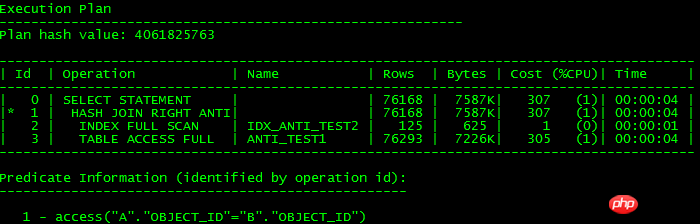
端的に言えば、unnestサブクエリをJOIN形式に変換できれば、効率的なJOIN機能を使用できます。変換できない場合は、FILTER を使用してください。これは、ORACLE の条件がないため、11g の NULL AWARE がまだ使用されていないことがわかります。 object_id が NULL である可能性があるため、インデックスを使用できないことがわかります。
OK、データベースのアップグレード プロセス中に発生したケースについて話しましょう。その背景には、11.2.0.2 から 11.2.0.4 へのアップグレード後に次の SQL にパフォーマンスの問題があることが考えられます。
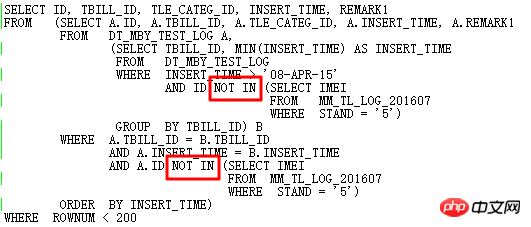
実行計画は次のとおりです。
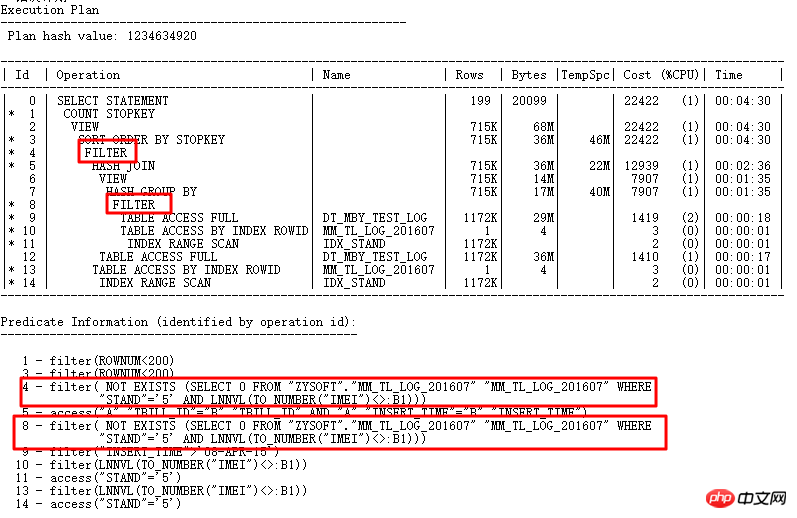
ここで、FILTER ID=4 と ID=8 の両方に 2 つの子ノードがあります。これは明らかに UNNEST に対する NOT IN サブクエリの失敗が原因です。前述したように、NOT IN は 11g ORACLE CBO で NULL AWARE ANTI JOIN に変換でき、11.2.0.2 では変換できますが、11.2.0.4 では変換できません。 2 つの FILTER 操作はどの程度有害ですか? 実際の実行計画は、次のクエリで確認できます。
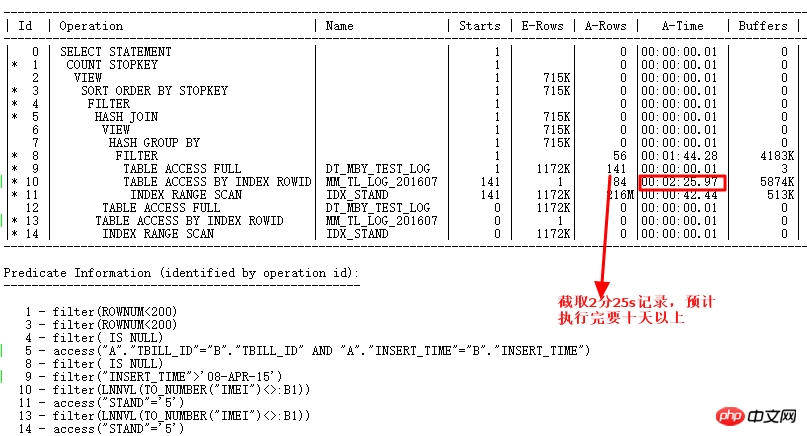
2 分 25 秒のレコードをインターセプトして、実際の状況を確認します (ID=9 ステップ)。 CARD= 行 141 には 2 分 25 秒かかります。実際の手順は次のとおりです: 27w 行
- NULL AWARE ANTI JOIN に関連する暗黙のパラメータが有効かどうかをクエリします
- 統計情報の収集が有効かどうか
- 新しいバージョンのバグですか、それともアップグレード中にパラメータが変更されましたか? 結果の

本題に戻り、問題の原因が新しいバージョンのバグなのか、パラメータの変更なのかを調べる必要があります。 次に、SQLT の高度なメソッドである XPLORE を使用する必要があります。 XPLORE は ORACLE のさまざまなパラメータを開いたり閉じたりして実行計画を出力します。最後に、生成されたレポートを通じて一致する実行計画を見つけて、バグの問題なのかパラメータ設定の問題なのかを判断します。

readme.txt を参照して、テストが必要な SQL を別のファイルに編集します。通常、テストには XPLAIN メソッドを使用し、テストには EXPLAIN PLAN FOR を呼び出します。テストの効率化。
SQLT 問題の原因を見つけます:

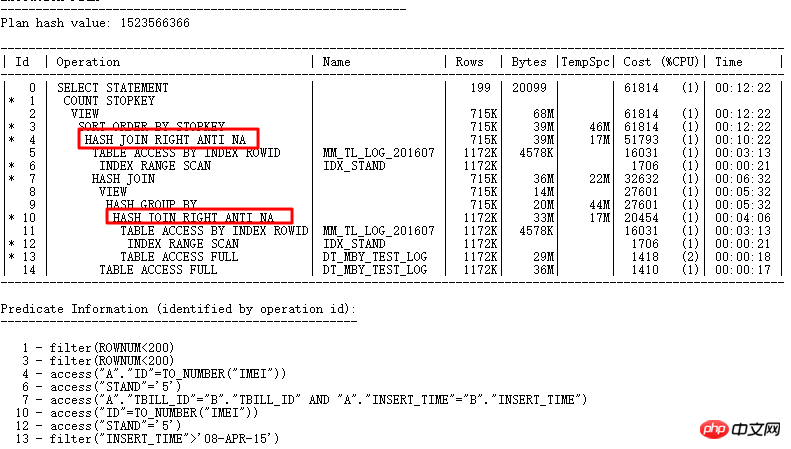
最後に SQLT を通してこの点から、多くのクエリ変換が成功する可能性があり、1 つのパラメータだけが機能するわけではなく、複数のパラメータが連携して機能することもあることもわかります。したがって、特別な理由がない限り、デフォルトのパラメータをオフにし、デフォルト値を簡単に変更しないでください。この時点では、この問題は SQLT のおかげですぐに解決されました。SQLT を使用しなかった場合、問題を解決するプロセスは明らかにさらに複雑になるでしょう。開発者は最初に SQL を変更する必要があります。
考えてみてください、元の SQL をもっと最適化できないでしょうか?
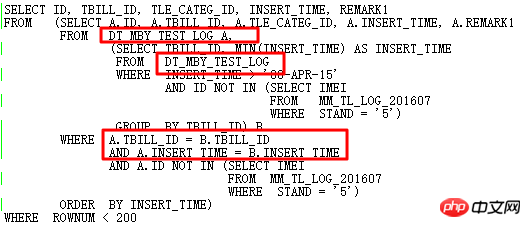
明らかに、さらに最適化したい場合は、SQL を完全に書き直す必要があります。観察すると、2 つのサブクエリには類似点があります。各 TBILL_ID に従って、指定された INSERT_TIME 範囲内でテーブル DT_MBY_TEST_LOG を検索します。最小の INSERT_TIME であり、ID がサブクエリに含まれていない場合は、INSERT_TIME に従って結果を並べ替え、最終的に TOP 199 を取得します。
元の SQL は自己結合と 2 つのサブクエリを使用しており、冗長で複雑です。当然、分析関数で書き換えて自己結合を避けて効率を上げることも考えます。書き換えられた SQL は次のとおりです。
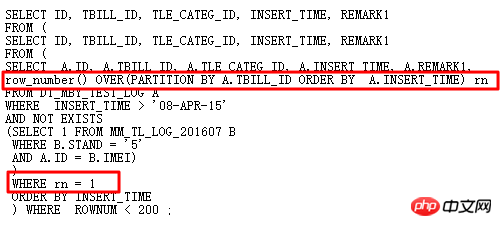
実行計画:
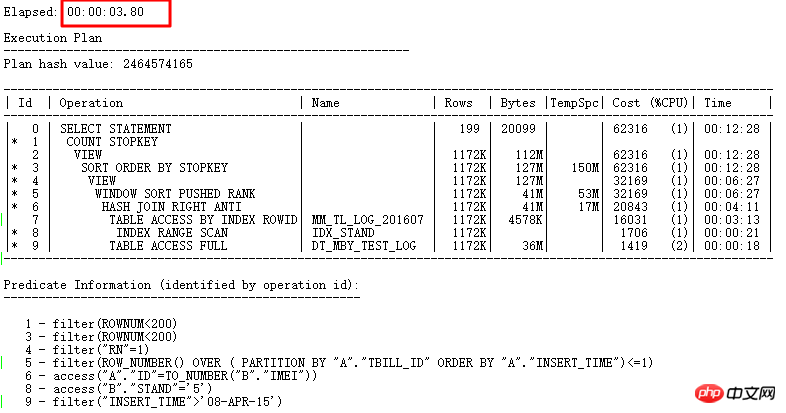
この時点で、この SQL は元々 FILTER を使用するのに 10 日かかり、NULL AWARE ANTI JOIN を使用してソースを見つけるのに 7 日かかりました。問題は数秒以上かかり、最終的な完全な書き換えには 3.8 秒かかりました。
(2) OR サブクエリのフィルター
OR とサブクエリの一般的な使用方法を見てみましょう。実際の最適化プロセスでは、OR がサブクエリと併用されると、一般にサブクエリのネストを解除することができなくなります。重大な問題がある場合は、サブクエリで OR を使用する方法が 2 つあります:
条件またはサブクエリ
-
サブクエリに含まれる、または内部 (条件 1 または条件 2 のタブから ... を選択)
または特定の OR サブクエリを最適化する方法を共有する事例を取り上げます。特定のライブラリ 11g R2 で次の SQL に遭遇しましたが、数時間実行されませんでした。

まず、実行計画を見てください:
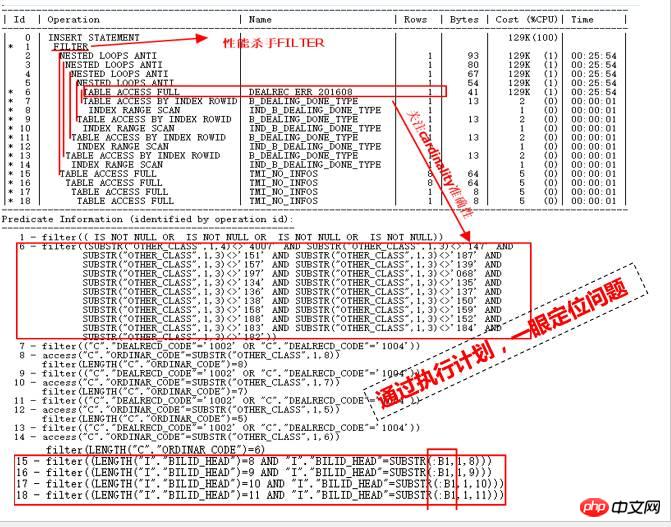
どのようにこの実行計画を見ると、パフォーマンスが遅い原因を一目で特定できますか?分析と位置付けは主に次の点に基づいています:
実行プラン内の行、つまり各ステップによって返されるカーディナリティは非常に小さく、数行のみであり、分析テーブルはそれほど大きくありません。 1 時間以内に完了できない場合はどうすればよいでしょうか?大きな理由としては、不正確な統計情報が CBO オプティマイザーによる誤った推定につながることが考えられます。これが最初のポイントです。
ID=15 から 18 の部分を見てください。これらは ID=1 の FILTER 操作の 2 番目の子ノードです。ID=2 の推定カーディナリティの場合、最初の子ノードは明らかに ID=2 の部分です。部分が間違っていますが、実際の状況 これが非常に大きい場合、ID=15 ~ 18 の 4 つのテーブルに対するフルスキャンの数が膨大になり、大惨事につながります。
明らかに、ID=2 部分の一連の NESTED LOOPS も非常に疑わしいです。ID=2 操作の入り口は、テーブル全体で DEALREC_ERR_201608 がスキャンされています。明らかに、これが NESTED LOOPS 操作の原因であるため、正確性を検証する必要があります。
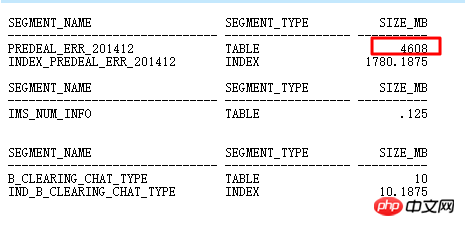
メインテーブル DEALREC_ERR_201608 は、ID=6 クエリ条件で 2000w 行を返します。そのため、実際には NESTED LOOPS の数が数千万回実行されると推定されます。効率を高めるには HASH JOIN を使用し、統計情報を更新する必要があります。
さらに、ID=1 は FILTER で、その子ノードは ID=2 と ID=15、16、17、18 です。同じ ID 15 ~ 18 も数千万回駆動されています。
問題の根本原因を見つけたら、段階的に解決してください。まず、ID=6 部分の DEALREC_ERR_201608 テーブルのクエリ条件 substr(other_class, 1, 3) NOT IN ('147', '151', …) によって取得されるカーディナリティの精度を解決する必要があります。 、統計情報を収集するため。
ただし、size auto と sizerepeat を使用しても、other_class のヒストグラムの収集には影響がありません。実行プラン内の other_class のクエリ条件の戻り値の推定値は、依然として 1 (実際には 2,000 万行) であることがわかりました。

再実行後の実行計画は次のとおりです:
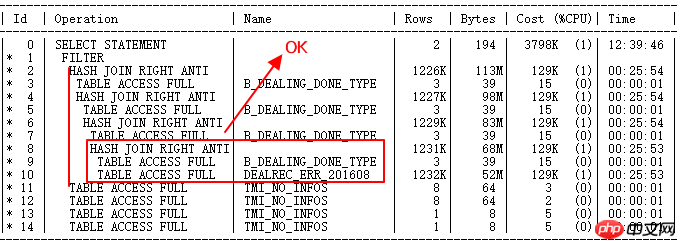
DEALREC_ERR_201608 および B_DEALING_DONE_TYPE は元々 NL を使用していましたが、現在は HASH JOIN を正しく使用しています。ビルド テーブルは小さな結果セットであり、プローブ テーブルは ERR テーブルの大きな結果セットです。正しいです。
しかし、ID=2 と ID=11 から 14、つまり TMI_NO_INFOS または FILTER を伴う OR サブクエリは、数千万の子ノード クエリを駆動します。これは、最適化の次のステップで解決される問題です。
パフォーマンスは12時間から2時間まで。
今解決する必要があるのは、サブクエリに OR 条件がある場合、単純な条件をクエリして変換できる場合、通常は union の全ビューに変換され、次にセミビューになります。 join と anti join (すべて結合ビューに変換されます。述語の型が異なる場合、SQL はエラーを報告する可能性があります)。この複雑さのため、オプティマイザは変換をクエリできないため、再書き込みが唯一の実行可能な方法です。 SQLを解析してみると、クエリは同じテーブルで条件も似ていますが、長さが違うので扱いやすいです!

ORを使用したサブクエリの実行プランをFILTERからJOINに変更する方法。 2 つの方法:
1) UNION ALL/UNION に変更する
2) セマンティックな書き換えは以前から使用されており、テーブル アクセスを引き続き削減したい場合は、内部的に UNION のような操作に変換するしかありません。 UNION 演算への変換を避けるために、OR 条件を書き換えます。
元の OR 条件を分析してみましょう:
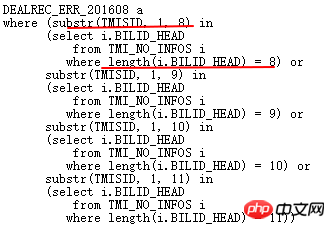
上記の意味は、ERR テーブル内の TMISID の最初の 8、9、10、11 桁が TMI_NO_INFOS.BILLID_HEAD と一致し、対応する一致する BILLID_HEAD の長さが正確に 8 であることを意味します。 、9、10、11。明らかに、セマンティクスは次のように書き換えることができます。
ERR テーブルは TMI_NO_INFOS テーブルに関連付けられており、ERR.TMISID の最初の 8 桁は、8 ~ 11 の間の長さを持つ ITMI_NO_INFOS.BILLID_HEAD の最初の 8 桁と正確に一致します。前提として、TMISID は「BILLID_HEAD %」のようなものです。
SQL をより合理化して効率的にするために、今すぐ複数の OR サブクエリを完全に変更してください。次のように書き換えられました:
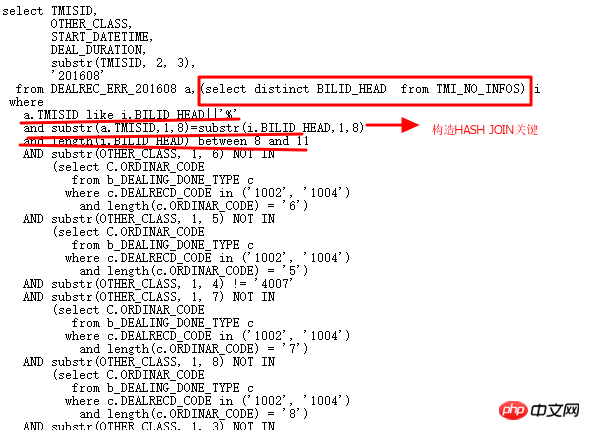
実行計画は次のとおりです:
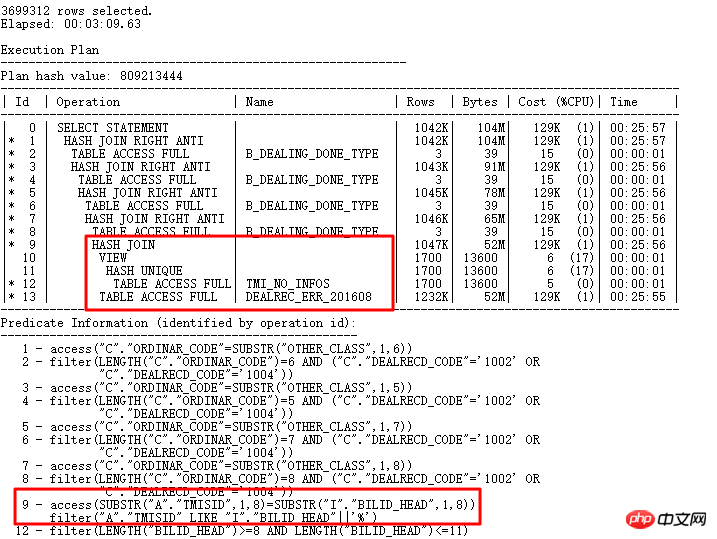
1) 現在の実行計画は、論理的な書き換えによって最終的に短くなり、より読みやすくなり、最終的な SQL はより多くの値を返します。 300 万行を超えるデータの実行には、当初は 12 時間かかっていましたが、現在では 3 分で実行されます。
2) 考え方: 適切な構造と明確なセマンティクスで SQL を記述することは、オプティマイザーがより合理的な実行計画を選択するのに役立ちます。 したがって、SQL を適切に記述することも技術的な仕事です。
このケースを通じて、クエリ コンバーターとして機能する SQL の作成方法についてヒントを得ることができれば幸いです。作成された SQL により、テーブル、インデックス、パーティションなどへのアクセスが軽減され、ORACLE によるアクセスが容易になります。いくつかの効率的なアルゴリズムを使用して操作を実行することで、SQL の実行効率が向上します。
実際、OR サブクエリは必ずしも完全にネスト解除されるわけではありません。ほとんどの場合、ネスト解除できないだけです。次の例を参照してください。
ネスト解除できないクエリ:
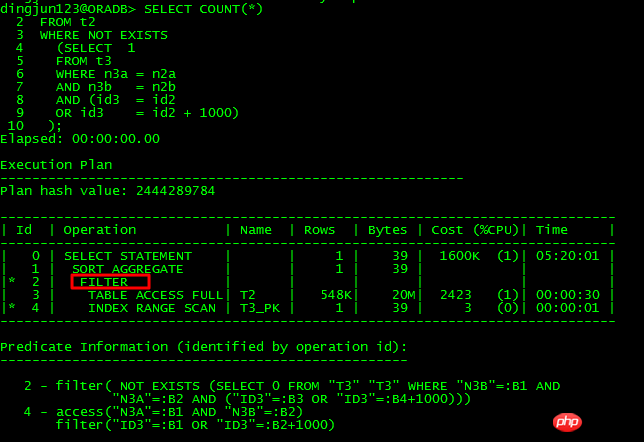
ネスト解除できるクエリ:
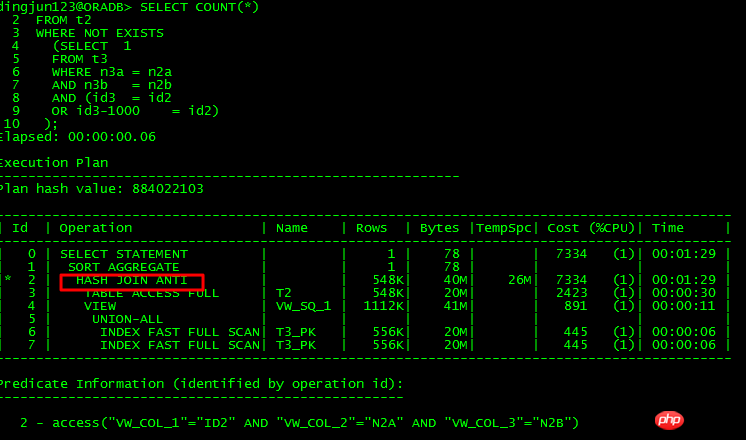
これら 2 つの SQL の違いは、条件 or id3 = id2-1000 を or id3-1000 = id2 に変換することです。前者はネスト解除できませんが、後者はネスト解除できます。10053 を分析すると、次のことがわかります。アンネストの発生は許可されません :
SU: ネスト解除が有効なクエリ ブロック SEL$1 (#1) 内のクエリ ブロックをアンネストします。
クエリ ブロック SEL$1 (#1)SU のネスト解除を実行するサブクエリコスト計算が必要です。
SU: クエリブロック SEL$1 (#1) でのサブクエリのネスト解除を検討しています。
SU: サブクエリ SEL$2 (#2) のネスト解除の有効性を確認しています
SU: SU バイパス: 無効な相関述語。
SU: 有効性チェックに失敗しました。
次のようにネストを解除できます:

SQL を次のように書き換えます:

最後に、CBO は最初に T3 条件をクエリして、 UNION ALL ビュー。後で T2 に関連付けられます。この観点から見ると、OR サブクエリのネスト解除要件は比較的厳しいことがわかります。このステートメントを分析すると、ORACLE はメイン テーブルの列に対する操作を必要とせずにネスト解除操作を実行できます。オプティマイザ自体は +1000 条件を左にシフトしません。厳密であるため、ほとんどの場合、OR サブクエリのネストを解除できず、さまざまなパフォーマンスの問題が発生します。
(3) FILTER に似た問題
FILTER に似た問題は、主に UPDATE 関連の更新とスカラー サブクエリに反映されますが、FILTER キーワードはそのような SQL ステートメントに明示的に現れませんが、内部操作は FILTER 操作とまったく同じです。 。
まず UPDATE 関連付けの更新を確認します。

ここで 14999 行を更新する必要があります。 実行計画は次のとおりです。
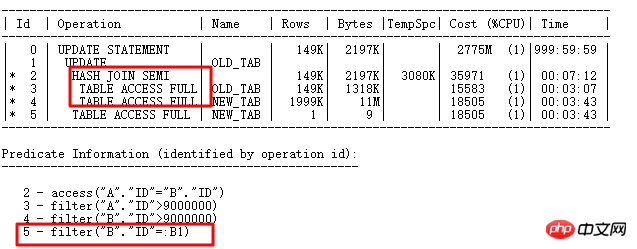
最初にクエリを実行します。更新する必要がある条件を指定してから、UPDATE 関連のサブクエリ更新を実行すると、バインディング変数が ID=5 の部分に表示されることがわかります。B1. 明らかに、選択された各行およびサブクエリに対する UPDATE 操作は同じです。テーブル NEW_TAB に関連付けられたクエリ。ID 列の重複値が より大きい場合、それより小さい場合、サブクエリが何度も実行されるため、効率に影響します。つまり、ID=5 の操作が実行されます。何度も。
もちろん、ここでのフィールド ID は非常に一意です。UNIQUE INDEX ライトと通常の INDEX ライトを作成して、そのインデックスをステップ 5 で使用できるようにします。この UPDATE 最適化メソッドの例を次に示します。インデックスを構築せずに、UPDATE: MERGR メソッドや UPDATE INLINE VIEW メソッドも実現できます。
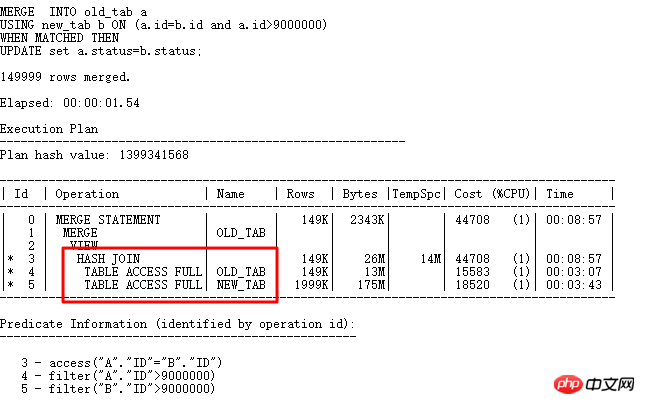
MERGE は HASH JOIN を直接使用して複数のアクセス操作を回避するため、効率が大幅に向上します。 UPDATE LINE VIEW の書き方を見てみましょう:
UPDATE
(SELECT a.status astatus,
b.status)。 bstatus
FROM old_tab a,
new_tab b
WHERE a.id=b.id
AND a.id > 9000000
)
SET astatus=bstatus;
b.id が保存されている必要がありますキー (一意のインデックス)、一意の制約、主キー)、11g bypass_ujvc は MERGE 操作と同様のエラーを報告します。
スカラー サブクエリを見てみましょう。スカラー サブクエリは、多くの場合、重大なパフォーマンスの問題を引き起こす原因となります。
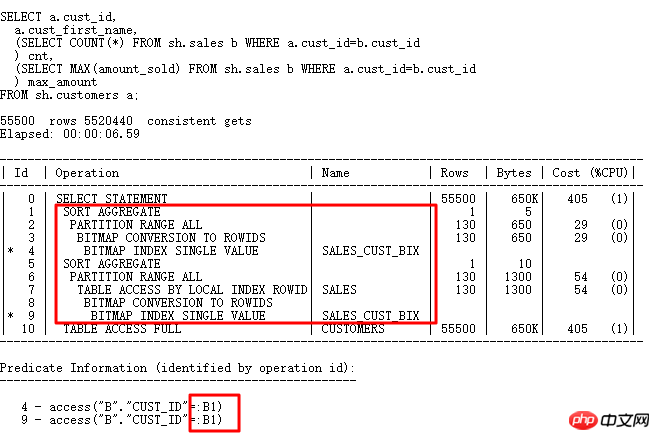
スカラー サブクエリ プランの実行順序は、通常のプランの実行順序とは異なります。 CUSTOMERS テーブルの結果は駆動され、各行はスカラー サブクエリ (CACHE を除く) によって駆動されます。これは FILTER 操作にも似ています。
スカラー サブクエリを最適化する場合は、通常、SQL を書き換えて、スカラー サブクエリを外部結合形式に変更する必要があります (制約とビジネスが満たされている場合は、通常の JOIN に書き換えることもできます):

書き換え後の効率が大幅に向上し、HASH JOINアルゴリズムを使用します。スカラー サブクエリの CACHE を見てみましょう (FILTER および UPDATE 関連の更新も同様です)。関連する列に多くの繰り返し値がある場合、サブクエリの実行頻度が減り、この時点で効率が向上します。
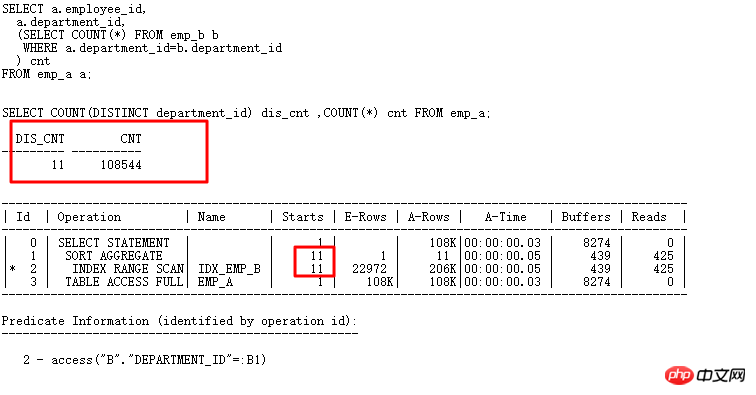
2 HASH JOIN 操作が実行されると、T テーブル インデックスは使用できなくなります。実行頻度が高くなると、必然的にシステムへの影響が大きくなります。なぜ ORACLE は、TABLE 関数がほとんど渡さないことを認識しないのでしょうか。価値観?
さらなる分析:
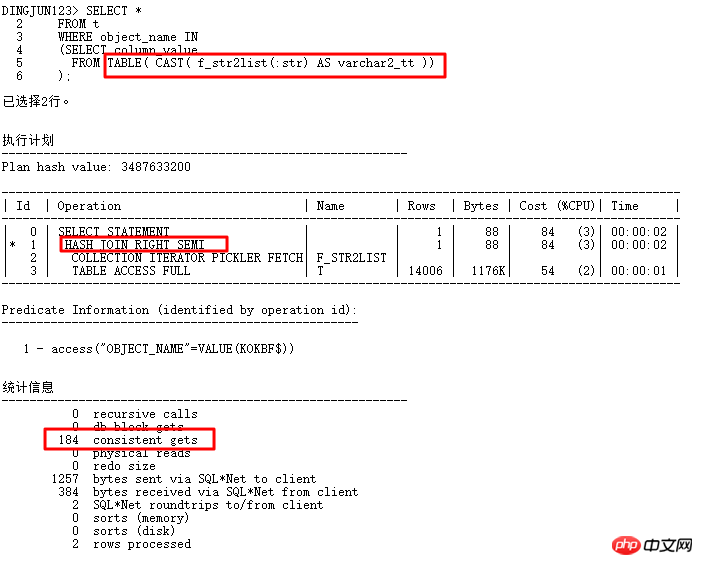
上記の結果から、TABLE 関数のデフォルトの行数は 8168 行であることがわかります (TABLE 関数によって作成された疑似テーブルには統計情報がありません)。この値は一般的には 8168 行よりもはるかに大きくなっています。実際のアプリケーションでは多くの場合、これにより、実行プランでネストされたループの代わりにハッシュ結合が使用されます。この状況を変更するにはどうすればよいでしょうか? もちろん、ヒント プロンプトを通じて実行計画を変更できます。一般的に使用されるヒントは、
first_rows、index、cardinality、use_nl などです。
ここでは、cardinality(table|alias,n) について特別に紹介します。このヒントは、CBO オプティマイザーにテーブル内の行数が n であると認識させ、実行計画を変更できるようにします。次に、上記のクエリを書き換えます:
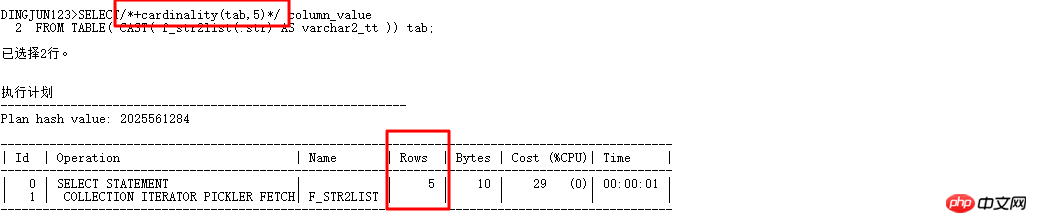
Add Cardinality(tab,5) により、CBO オプティマイザーが自動的に実行されます。オプティマイザーは、テーブルのカーディナリティを 5 として扱います。以前の where in list クエリでは、カーディナリティがデフォルトの 8168 のときにそれが使用されていました。ハッシュ結合です。カーディナリティが使用できるようになりました。
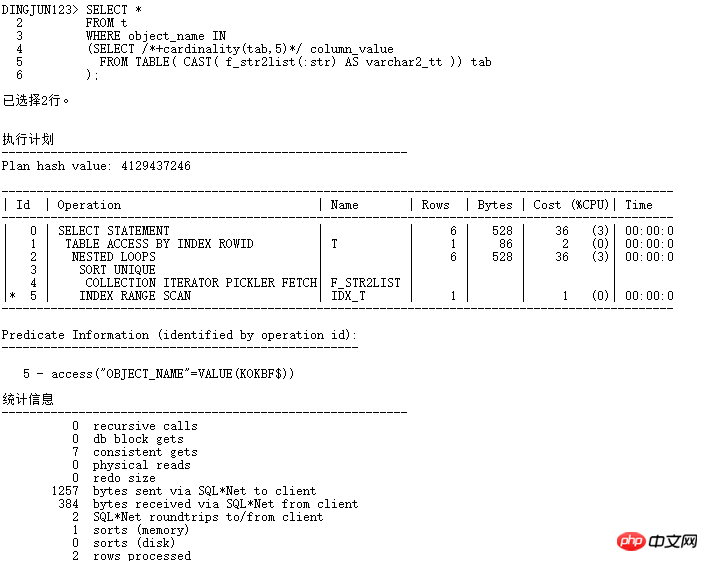
子ノードは INDEX RANGE SCAN を使用できるようになり、効率が向上します。何十回も改善されました。もちろん、実際のアプリケーションではヒントを追加しないことが最善であり、SQL PROFILER バインディングを使用できます。
3 不正確な選択性計算の問題
Oracle の内部計算選択性は数値形式で計算されるため、文字列型に遭遇すると、文字列を RAW 型に変換し、次に RAW 型を数値に変換し、ROUND を 15 に変換します。左からの桁数が大きい場合、変換された数値が非常に大きい場合、元の文字列はかなり異なる可能性がありますが、内部的に変換された数値は比較的近いため、不正確な選択計算が発生する可能性があります。次の例を考えてみましょう:

実行計画は次のとおりです:
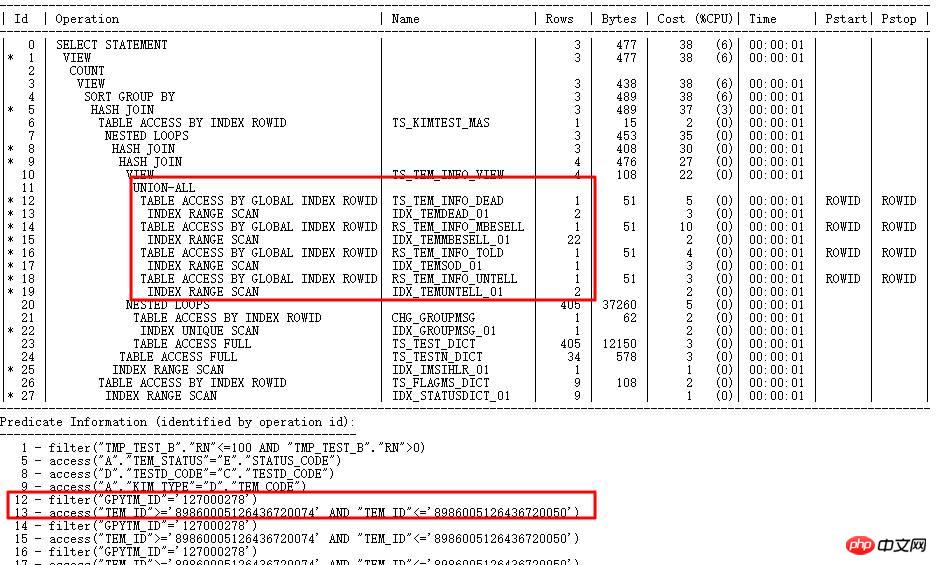
SQL 実行計画は TEM_ID インデックスを使用し、1 時間以上実行する必要があります。 計画内の対応するステップにはカーディナリティがほとんどありません。 (数十レベル) ですが、実際には非常に大きい(数百万レベル))、統計情報が間違っていると判断されます。
なぜ間違ったインデックスに移動してしまうのでしょうか?
TEM_ID は長さ 20 の CHAR 文字列タイプであるため、CBO の内部計算選択性により、まず文字列が RAW に変換され、次に RAW が左から 15 桁を ROUND した数値に変換されます。したがって、文字列値が大きく異なっていても、数値に変換すると値が似てしまう可能性があり (15 桁を超える数字には 0 が埋め込まれているため)、選択的な計算エラーが発生します。例として TS_TEM_INFO_DEAD の TEM_ID 列を取り上げます。

条件に基づいてクエリされた実際の行数は 29737305 です。したがって、インデックスが間違ってしまいます。
解決策:
内部アルゴリズムの特定の制限により、異なる値を持つ文字列は同じ内部計算値を持つ可能性があるため、ヒストグラムを収集した後の文字列値は異なります。同様に、ORACLE は検証のために実際の値を ENDPOINT_ACTUAL_VALUE に保存し、実行計画の精度を向上させます。 GPYTM_ID に正しくインデックスを作成した後の実行時間は、1 時間以上から 5 秒未満の範囲になります。
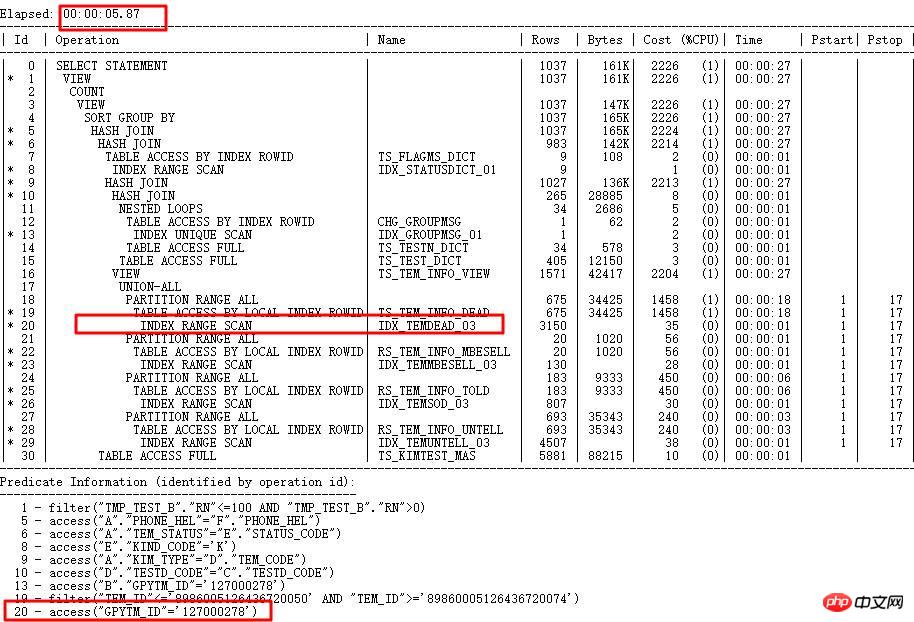
4 新機能は実行エラーを引き起こす
どのバージョンでも多くの新機能が導入されますが、ACS やカーディナリティ フィードバックなどの一般的な問題は、実行計画の頻繁な変更につながり、効率に影響を及ぼします。したがって、前述の 11g null 対応アンチ結合などの新機能は注意して使用する必要がありますが、これにも多くのバグがあります。
今日分析するケースは、10g から 11g へのメジャー バージョン アップグレード中に発生した SQL です。10g では正常に実行されましたが、11g では不正に実行されました。 SQL は次のとおりです。
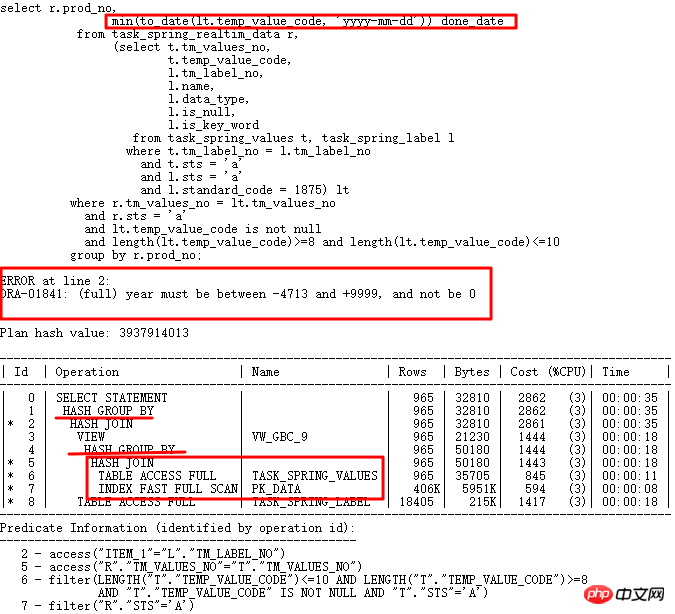
10g は正常です。11g r2 にアップグレードすると、temp_value_code に複数の形式の文字列が格納されます。正しい実行計画: LT 関連のクエリが最初に実行され、次にテーブルに関連付けられます。間違った実行プランは、TASK_SPRING_VALUES が最初にテーブルに関連付けられ、次に VIEW としてグループ化され、次に TASK_SPRING_LABEL に関連付けられ、その後再びグループ化されることです。ここには 2 つの GROUP BY 操作があります。これは、1 つだけの 10g 実行プランとは異なります。 GROUP BY 操作。最終的にエラーが発生します。
明らかに、GROUP BY 操作が 2 つある理由については調査が必要です。10053 が最初の選択肢です。
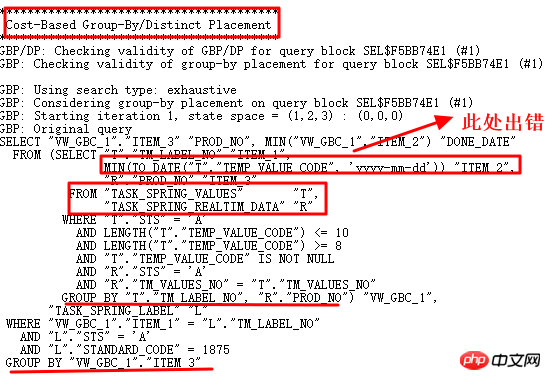
10053 に従って操作を分析し、非日付形式の値が見つかったかどうかを確認します。
yyyy-mm-dd 以外の形式文字列が実際に見つかったので、to_date 操作は失敗しました。 10053 からわかるように、ここでは Group by/Distinct Placement 操作が使用されているため、対応する制御パラメーターを見つけて、このクエリ変換をオフにする必要があります。
GBP の暗黙的パラメーターをオフにした後に修正します: _optimizer_group_by_placement。正しい実行計画は次のとおりです。
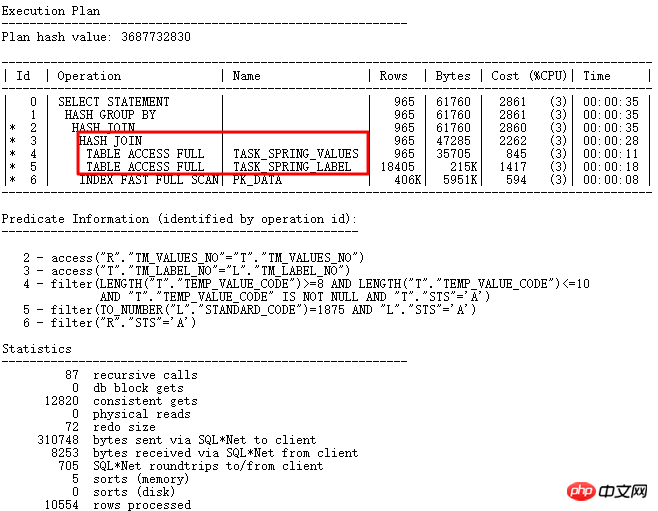
考察: この問題の本質は、temp_value_code が通常の文字、数字、および日付形式 yyyy-mm-dd を格納するために varchar2 として使用される不合理な設計にあります。プログラムには to_number や to_date などがあり、変換は実行計画内のテーブルの結合順序と条件に大きく依存します。したがって、特に関連するフィールド タイプとフィールドの単一の役割の一貫性を確保し、パラダイムの要件を満たすためには、優れた設計が非常に重要です。
5 、その結果、CBO は何もできなくなります。以下はページネーションライティングの事例です。 非効率なページング記述方法:独自の記述方法 最内層はuse_dateなどの条件でクエリを行ってソートし、rownumを取得してエイリアスし、最外層はrnルールを使用します。どうしたの? 

上の 2 つはインデックス実行プランです。クリックしてください: 
MOS にクエリを実行すると、_fix_control=8275054 は非常に疑わしいです。 >b, 当然インデックスは使用できませんが、この 8275054 を閉じることで解決できます。 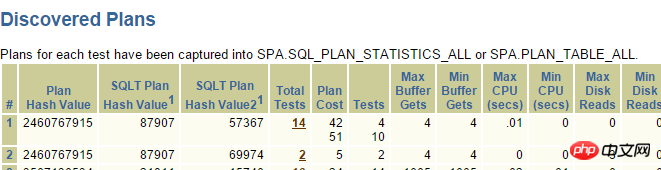
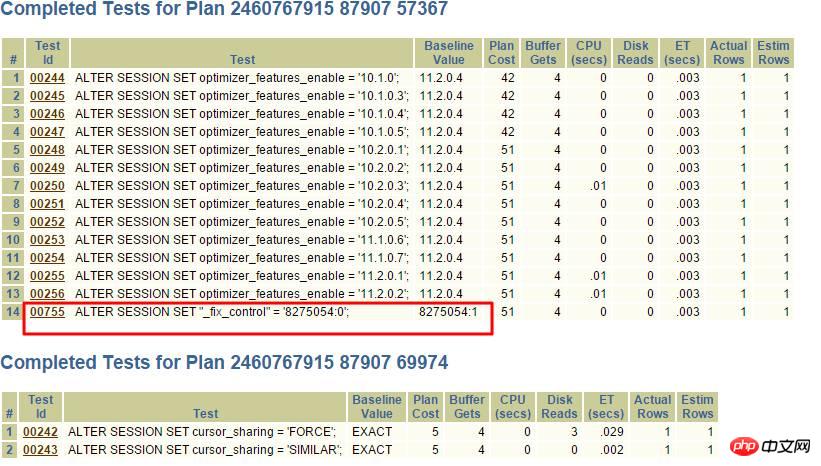 一般的な形式は次のとおりです:
一般的な形式は次のとおりです:
HASH JOIN
ビルドテーブル
小さな例を使用してハッシュの衝突を分析してみましょう:
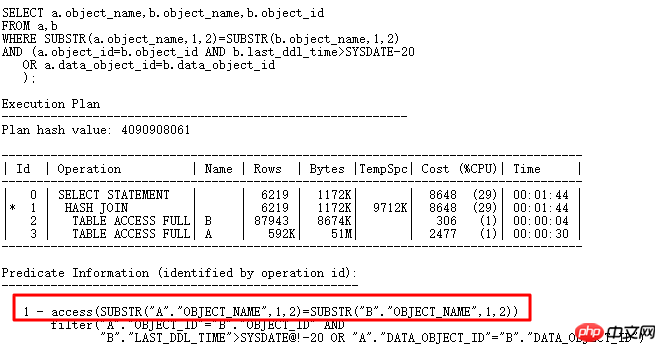
テーブル a には 61w の複数のレコードがあり、テーブル b には 7w の複数のレコードがあり、この SQL の結果は実行計画からは 80,000 のレコードを返しますが、HASH JOIN 操作には問題ありませんが、この SQL の実際の実行にはそれ以上の時間がかかります。 10 分間。どれも実行されていないため、CPU 使用率が急激に増加し、2 つのテーブルにアクセスする時間よりもはるかに大きくなります。
HASHJOIN を知っている場合は、この時点でハッシュ衝突が発生したかどうかを考慮する必要があります。大量のデータが多くのバケットに保存されている場合、そのようなハッシュ バケット内のデータ検索はネストされたループに似ており、非常に効率的です。さらなる分析は次のとおりです:

3000 を超える重複データを探します。もちろん、比較的大きなデータも多数残っています。 JOIN、EVENT 10104 を使用できます:
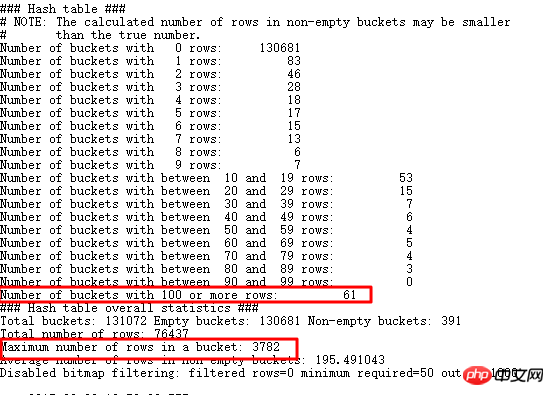
はい 100 行以上を保存するバケットが 61 個あり、最大のバケットには 3782 個の項目が保存されていることがわかります。これは、クエリした内容と一致しています。元の SQL に戻りましょう:
なぜ Oralce は HASH テーブルを構築するために substr(b.object_name,1,2) を選択したのでしょうか? OR を拡張でき、元の SQL が UNION ALL 形式に変更される場合、HASH はtable は substr( b.object_name,1,2) を使用でき、 b.object_id と data_object_id が構築されると、一意性が非常に優れている必要があり、ハッシュ衝突の問題を解決できるはずです。 次のように書き換えられます。
現在の SQL 実行時間は 10 以上から元の値に増加しました 4 秒の実行後に結果はありません。内部的に構築された HASHTABLE 情報を見てみましょう: 
最大のバケットには 6 個のデータのみが保存されます。したがって、パフォーマンスは以前よりもはるかに向上しているはずです。実際のアプリケーションでは、ハッシュの衝突はさらに複雑になる可能性があります。ハッシュの衝突の問題が発生した場合、最善の方法は、SQL をビジネスの観点から分析して、より選択的な列を追加できるかどうかを確認することです。参加する。 。 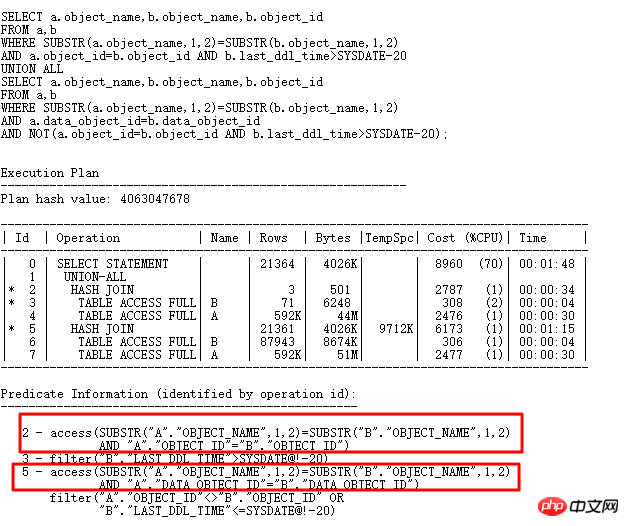
 次の問題は、SQL パフォーマンス管理プラットフォームを通じて解決できます。
次の問題は、SQL パフォーマンス管理プラットフォームを通じて解決できます。
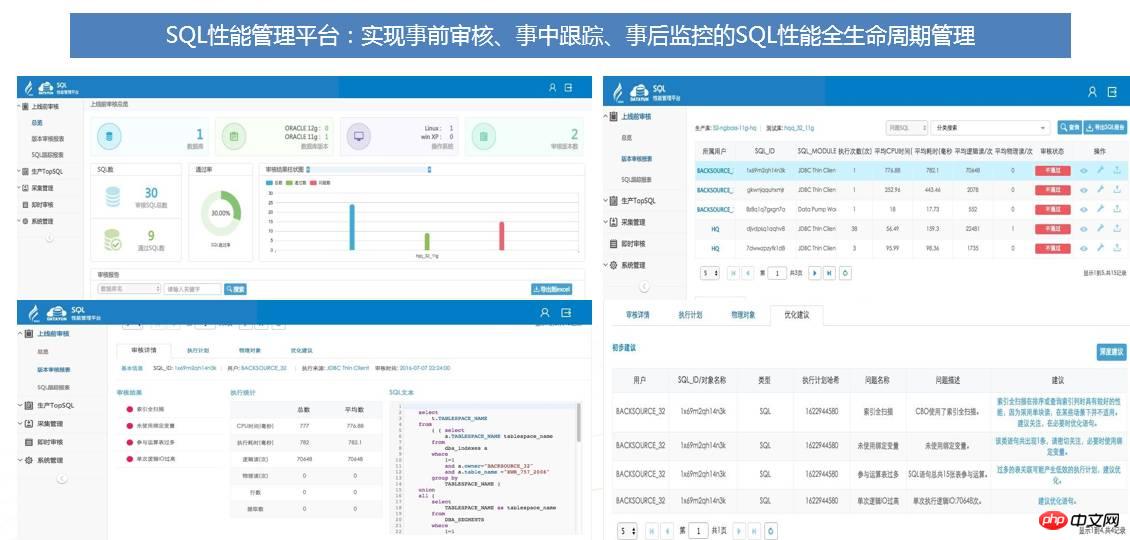
- その後: TOPSQL の監視、タイムリーなアラーム処理。
- SQL パフォーマンス管理プラットフォームは、360 度の完全なライフサイクル管理と SQL パフォーマンスの制御を実現し、さまざまなインテリジェントなプロンプトと処理を通じて、もともと SQL によって引き起こされたパフォーマンスの問題のほとんどを問題が発生する前に解決し、システムを改善します。安定性。
- 以下は SQL 監査の典型的なケースです:
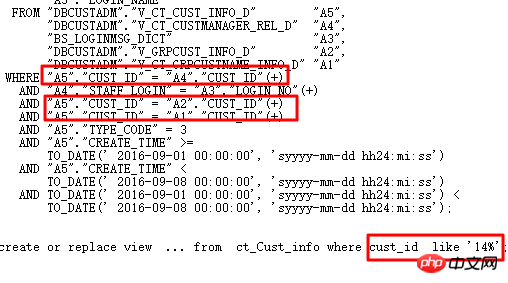
実行計画は次のとおりです:
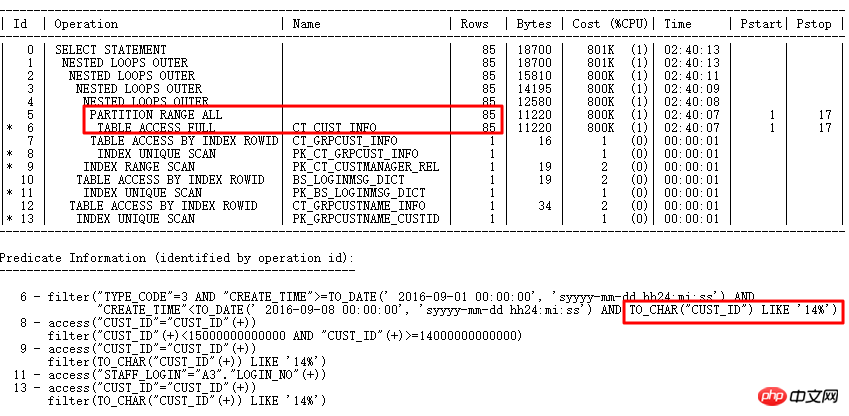
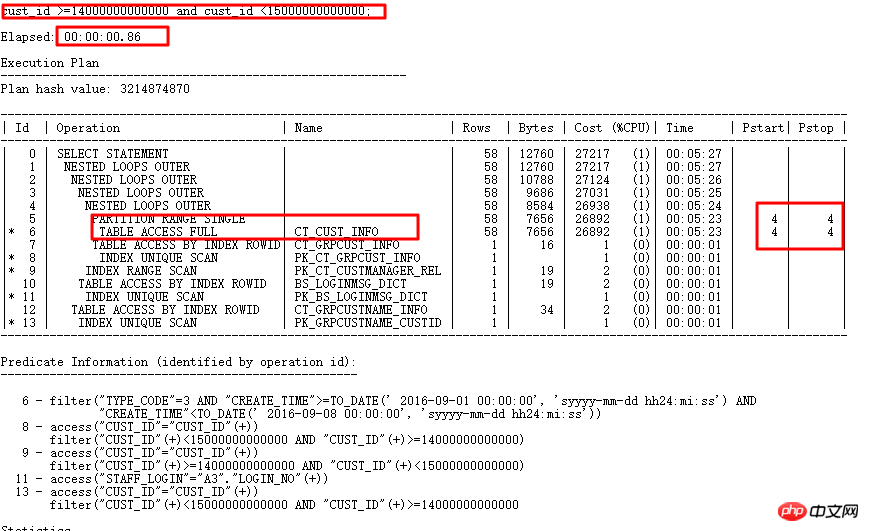
元の SQL 実行 1688 秒。 SQL 監査のインテリジェントな最適化により、最適化ポイントを正確に見つけます - パーティション列には型変換があります。 最適化後0.86秒。
SQL 監査は、Xinju データベース パフォーマンス管理プラットフォーム DPM のモジュールです。DPM について詳しく知りたい場合は、マスター Zou Deyu (WeChat: carydy) に参加してコミュニケーションとディスカッションを行うことができます。
今日は主に、Oracle オプティマイザーに存在するいくつかの問題と、一般的な問題の解決策を紹介します。もちろん、オプティマイザーの問題は現在共有されている問題に限定されませんが、CBO は非常に強力であり、12c では大幅に改善されています。問題はたくさんありますが、日常生活でより多くのことを観察し、蓄積し、特定の方法を習得する限り、問題に遭遇した後に戦略を立て、何千マイルも勝ち取ることができます。
Q&A
Q1: ハッシュ結合の原理を簡単に説明してもらえますか?
A1: ORACLE HASH JOIN 自体はソートする必要がありません。これは SORTMERGE JOIN の特徴の 1 つです。 ORACLE HASH JOIN の原理は比較的複雑です。Jonathan Lewis の『Cost-Based Oracle Fundamentals』の HASH JOIN の部分を参照してください。HASH JOIN で最も重要なことは、原理に基づいてどのような場合に速度が低下するかを把握することです。 、HASH_AREA_SIZE が小さすぎるため、HASH TABLE をメモリに完全に配置できず、ディスク HASH 操作が発生し、上記の HASH 衝突が発生します。
Q2: インデックスを作成しないのはどのような場合ですか?
A2: インデックスを使用しない場合が多いです。第一の理由は、統計情報が不正確であることです。第二の理由は、インデックスの使用効率がフルスキャンを使用するよりも悪いためです。もう 1 つの一般的な理由は、インデックス列に対して操作が実行されたため、インデックスを作成できなくなったことです。インデックスを使用できない理由は他にも多数あります。詳細については、MOS ドキュメント「クエリがインデックスを使用していない理由の診断 (ドキュメント ID 67522.1)」を参照してください。
以上がCBOのSQL最適化問題を解く(画像と文章で詳しく解説)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7681
7681
 15
1639
14
1393
52
1286
25
1229
29
15
1639
14
1393
52
1286
25
1229
29

 MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQLはオープンソースのリレーショナルデータベース管理システムであり、主にデータを迅速かつ確実に保存および取得するために使用されます。その実用的な原則には、クライアントリクエスト、クエリ解像度、クエリの実行、返品結果が含まれます。使用法の例には、テーブルの作成、データの挿入とクエリ、および参加操作などの高度な機能が含まれます。一般的なエラーには、SQL構文、データ型、およびアクセス許可、および最適化の提案には、インデックスの使用、最適化されたクエリ、およびテーブルの分割が含まれます。
 MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
データベースとプログラミングにおけるMySQLの位置は非常に重要です。これは、さまざまなアプリケーションシナリオで広く使用されているオープンソースのリレーショナルデータベース管理システムです。 1)MySQLは、効率的なデータストレージ、組織、および検索機能を提供し、Web、モバイル、およびエンタープライズレベルのシステムをサポートします。 2)クライアントサーバーアーキテクチャを使用し、複数のストレージエンジンとインデックスの最適化をサポートします。 3)基本的な使用には、テーブルの作成とデータの挿入が含まれ、高度な使用法にはマルチテーブル結合と複雑なクエリが含まれます。 4)SQL構文エラーやパフォーマンスの問題などのよくある質問は、説明コマンドとスロークエリログを介してデバッグできます。 5)パフォーマンス最適化方法には、インデックスの合理的な使用、最適化されたクエリ、およびキャッシュの使用が含まれます。ベストプラクティスには、トランザクションと準備された星の使用が含まれます
 なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
MySQLは、そのパフォーマンス、信頼性、使いやすさ、コミュニティサポートに選択されています。 1.MYSQLは、複数のデータ型と高度なクエリ操作をサポートし、効率的なデータストレージおよび検索機能を提供します。 2.クライアントサーバーアーキテクチャと複数のストレージエンジンを採用して、トランザクションとクエリの最適化をサポートします。 3.使いやすく、さまざまなオペレーティングシステムとプログラミング言語をサポートしています。 4.強力なコミュニティサポートを提供し、豊富なリソースとソリューションを提供します。
 Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheはデータベースに接続するには、次の手順が必要です。データベースドライバーをインストールします。 web.xmlファイルを構成して、接続プールを作成します。 JDBCデータソースを作成し、接続設定を指定します。 JDBC APIを使用して、接続の取得、ステートメントの作成、バインディングパラメーター、クエリまたは更新の実行、結果の処理など、Javaコードのデータベースにアクセスします。
 DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerでMySQLを起動するプロセスは、次の手順で構成されています。MySQLイメージをプルしてコンテナを作成および起動し、ルートユーザーパスワードを設定し、ポート検証接続をマップしてデータベースを作成し、ユーザーはすべての権限をデータベースに付与します。
 Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
CentOSにMySQLをインストールするには、次の手順が含まれます。適切なMySQL Yumソースの追加。 yumを実行して、mysql-serverコマンドをインストールして、mysqlサーバーをインストールします。ルートユーザーパスワードの設定など、MySQL_SECURE_INSTALLATIONコマンドを使用して、セキュリティ設定を作成します。必要に応じてMySQL構成ファイルをカスタマイズします。 MySQLパラメーターを調整し、パフォーマンスのためにデータベースを最適化します。
 MySQLの役割:Webアプリケーションのデータベース
Apr 17, 2025 am 12:23 AM
MySQLの役割:Webアプリケーションのデータベース
Apr 17, 2025 am 12:23 AM
WebアプリケーションにおけるMySQLの主な役割は、データを保存および管理することです。 1.MYSQLは、ユーザー情報、製品カタログ、トランザクションレコード、その他のデータを効率的に処理します。 2。SQLクエリを介して、開発者はデータベースから情報を抽出して動的なコンテンツを生成できます。 3.MYSQLは、クライアントサーバーモデルに基づいて機能し、許容可能なクエリ速度を確保します。
 MySQLをCentos7にインストールする方法
Apr 14, 2025 pm 08:30 PM
MySQLをCentos7にインストールする方法
Apr 14, 2025 pm 08:30 PM
MySQLをエレガントにインストールするための鍵は、公式のMySQLリポジトリを追加することです。特定の手順は次のとおりです。MYSQLの公式GPGキーをダウンロードして、フィッシング攻撃を防ぎます。 mysqlリポジトリファイルを追加:rpm -uvh https://dev.mysql.com/get/mysql80-community-rease-el7-3.noarch.rpm update yumリポジトリキャッシュ:yumアップデートインストールmysql:yumインストールmysql-server startup mysql sportin
