

概念としては、正規表現は Python に固有のものではありません。ただし、Python での正規表現の実際の使用には、まだいくつかの小さな違いがあります。
この記事は、Python 正規表現に関する一連の記事の一部です。このシリーズの最初の記事では、Python で正規表現を使用する方法に焦点を当て、Python のユニークな機能のいくつかを取り上げます。
Pythonで文字列を検索・見つける方法をいくつか紹介します。次に、グループ化を使用して、見つかった一致するオブジェクトのサブアイテムを処理する方法について説明します。
私たちが使用したい Python の正規表現のモジュールは、通常「re」と呼ばれます。 
1. Python のプリミティブ型文字列
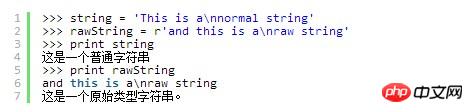
Python コンパイラーは、文字列定数内のエスケープ文字を表すために「」 (バックスラッシュ) を使用します。
バックスラッシュの後にコンパイラによって認識される特殊文字の文字列が続く場合、エスケープ シーケンス全体が対応する特殊文字に置き換えられます (たとえば、「n」はコンパイラによって改行文字に置き換えられます)。
しかし、これは Python で正規表現を使用する場合に問題を引き起こします。バックスラッシュは、正規表現内の特殊文字 (* や + など) をエスケープするために「re」モジュールでも使用されるためです。
この 2 つの混合物は、エスケープ文字自体をエスケープする必要がある場合 (特殊文字が Python と正規表現コンパイラーの両方で認識される場合) と、エスケープする必要がない場合があります (特殊文字のみが認識される場合) ことを意味します。 Python コンパイラによって認識されます)。
必要なバックスラッシュの数を把握することに集中する代わりに、代わりに生の文字列を使用できます。
プリミティブ型の文字列は、通常の文字列の二重引用符の前に文字「r」を追加するだけで作成できます。文字列がプリミティブ型の場合、Python コンパイラは置換を試みません。本質的には、文字列にまったく干渉しないようにコンパイラに指示していることになります。
Python で正規表現を使用して検索する
「re」モジュールは、入力文字列に対して正確なクエリを実行するためのメソッドをいくつか提供します。ここで説明するメソッドは次のとおりです:

各メソッドは、正規表現と一致する文字列を受け取ります。これらの各メソッドがどのように機能し、どのように異なるのかを理解するために、それぞれのメソッドを詳しく見てみましょう。
2. re.match を使用して検索 – マッチングが始まります
まず match() メソッドを見てみましょう。 match() メソッドの仕組みは、検索対象の文字列の先頭がパターンと一致する場合にのみ一致を見つけるというものです。
たとえば、文字列「dog cat Dog」に対して math() メソッドを呼び出すと、検索パターン「dog」が一致します:
 group() メソッドについては後で詳しく説明します。現時点では、引数として 0 を指定して呼び出したこと、および group() メソッドが見つかった一致するパターンを返すことだけを知っておく必要があります。
group() メソッドについては後で詳しく説明します。現時点では、引数として 0 を指定して呼び出したこと、および group() メソッドが見つかった一致するパターンを返すことだけを知っておく必要があります。
返された SRE_Match オブジェクトについては今のところスキップしました。これについてはすぐに説明します。
ただし、同じ文字列で math() メソッドを呼び出し、パターン「cat」を探しても、一致するものは見つかりません。
 3. re.search を使用して検索します – 任意の位置に一致します
3. re.search を使用して検索します – 任意の位置に一致します
search() メソッドは match() に似ていますが、search() メソッドは先頭から一致するもののみを検索することに限定されません。
ただし、search() メソッドは一致が見つかると停止するため、この例の文字列では searc() メソッドを使用して、 find 'dog' は最初に出現したもののみを検索します。 
4. re.findall を使用する – 一致するすべてのオブジェクト
これまで Python で最もよく使用した find メソッドは findall() メソッドです。 findall() メソッドを呼び出すと、一致オブジェクトを取得する代わりに、一致するすべてのパターンのリストを単純に取得できます (一致オブジェクトについては次に説明します)。私にとってはもっとシンプルです。サンプル文字列に対して findall() メソッドを呼び出すと次の結果が得られます:
 5. match.start メソッドと match.end メソッドを使用する
5. match.start メソッドと match.end メソッドを使用する
その後、前の search() によって以前に返された「match」および match() メソッド 「オブジェクト」とは正確には何ですか?
単純に文字列の一致する部分を返すのとは異なり、search() および match() によって返される「一致するオブジェクト」は、実際には部分文字列を一致させるためのラッパー クラスです。
先ほど、 group() メソッドを呼び出すことで一致した部分文字列を取得できることを見ましたが (次のセクションで説明するように、グループ化の問題を処理する場合、一致オブジェクトは実際に非常に役立ちます)、一致にはそれだけではありません。 object 一致する部分文字列に関する情報。
たとえば、match オブジェクトは、一致したコンテンツが元の文字列のどこで始まり、どこで終わるかを教えてくれます。 
この情報を知っていると、非常に役立つことがあります。
6. mathch.group を使用して数値でグループ化します
前に述べたように、match オブジェクトはグループ化を処理するのに非常に便利です。
グループ化は、正規表現全体の特定の部分文字列を見つける機能です。正規表現全体の一部としてグループを定義し、この部分の一致するコンテンツを個別に見つけることができます。
どのように機能するかを見てみましょう: 
私が作成した文字列は、誰かのアドレス帳から抜粋したスニペットのように見えます。この行を次のような正規表現と照合できます: 
正規表現の特定の部分を括弧 (文字 '(' および ')') で囲むことにより、コンテンツをグループ化でき、これらのサブグループは次のようになります。別々に扱われます。 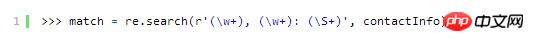
これらのグループは、グループ オブジェクトの group() メソッドを使用して取得できます。これらは、正規表現で左から右に表示される番号順 (1 から開始) によって見つけることができます。 
グループの序数が 1 から始まる理由は、0 番目のグループが保持するために予約されているためです。 all Match オブジェクト (以前に match() メソッドと search() メソッドを学習したときに確認しました)。 
7. match.group を使用してエイリアスでグループ化します
場合によっては、特に正規表現に多数のグループがある場合、グループの出現順による位置決めは非現実的になります。 Python では、次のステートメントを使用してグループ名を指定することもできます: 
引き続き group() メソッドを使用してグループの内容を取得できますが、今回は、代わりに指定したグループ名を使用する必要があります。以前に使用したもの グループの桁数。 
これにより、コードの明確さと読みやすさが大幅に向上します。正規表現が複雑になるにつれて、グループが何をキャプチャするのかを理解することがますます難しくなることが想像できます。グループに名前を付けると、あなたと読者にあなたの意図が明確に伝わります。
findall() メソッドはグループ化されたオブジェクトを返しませんが、グループ化も使用できます。同様に、findall() メソッドはタプルのコレクションを返します。各タプルの N 番目の要素は正規表現の N 番目のグループに対応します。 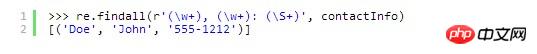
ただし、グループの名前付けは findall() メソッドには適用されません。
この記事では、Python で正規表現を使用するための基本をいくつか紹介しました。プリミティブ文字列型について (そして、それが正規表現を使用する際の問題点の解決にどのように役立つのか) について学びました。また、match()、search()、および findall() メソッドを使用して基本的なクエリを実行する方法と、グループ化を使用して一致したオブジェクトのサブコンポーネントを処理する方法も学びました。
いつものように、このトピックについてさらに詳しく知りたい場合は、re モジュールの公式 Python ドキュメントが素晴らしいリソースです。
今後の記事では、Python での正規表現の適用についてさらに詳しく説明します。マッチ オブジェクトをより包括的に見て、文字列内で置換を実行するためにそれらを使用する方法、さらにはテキスト ファイルから Python データ構造を解析するために使用する方法を学びます。
以上が7 つの Python 正規表現の使用例の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



