

Java はクロスプラットフォーム言語であり、異なるプラットフォームでのコーディングの切り替えが頻繁に行われるため、特に Java ではコーディングの問題が常にプログラム開発者を悩ませてきました。次に、Java エンコードの問題の根本的な原因、Java でよく発生するいくつかのエンコード形式の違い、Java Web の開発で発生する可能性のあるエンコードの問題の原因の分析、 HTTP リクエストのエンコード形式を制御する方法、中国語エンコードの問題を回避する方法など。
コンピュータに情報を保存する最小単位は 1 バイト、つまり 8 ビットなので、表現できる文字の範囲は 0 ~ 255 です。
シンボルが多すぎて、1バイトで完全に表現できません。
コンピュータはさまざまな変換方式を提供しており、一般的な変換方式には ASCII、ISO-8859-1、GB2312、GBK、UTF-8、UTF-16 などが含まれます。これらはすべて変換ルールを規定しており、これらのルールに従ってコンピュータは文字を正しく表現できます。これらのエンコード形式を以下に紹介します:
ASCII コード
合計128個あり、1バイトの下位7ビットで表され、0~31は改行、復帰、削除などの制御文字、32~126はキーボードから入力できる印刷文字であり、を表示することができます。
ISO-8859-1
128 文字では明らかに不十分であるため、ISO 組織は ASCII に基づいて拡張され、ISO-8859-1 から ISO-8859-15 までがカバーされ、最も広く使用されています。 ISO-8859-1 は依然としてシングルバイトエンコーディングであり、合計 256 文字を表現できます。
GB2312
これは 2 バイト エンコードであり、合計のエンコード範囲は A1 ~ F7 です。A1 ~ A9 はシンボル領域で、合計 682 個のシンボルが含まれます。B0 ~ F7 は漢字領域で、6763 個の漢字が含まれます。
GBk
GBK は GB2312 を拡張した「漢字内部コード拡張仕様」であり、そのエンコード範囲は 8140 ~ FEFE (XX7F を除く) で、合計 21003 個の漢字を表現できます。 GB2312のエンコーディングで文字化けしません。
UTF-16
これは、コンピュータ内で Unicode 文字にアクセスする方法を具体的に定義します。 UTF-16 は、Unicode 変換形式を表すために 2 バイトを使用します。つまり、どの文字であっても 2 バイトで表されます。 2 バイトが 16 ビットであるため、UTF-16 と呼ばれます。文字を表すのに非常に便利です。2 バイトで 1 文字を表すことはできないため、文字列操作が大幅に簡素化されます。
UTF-8
UTF-16 では文字を一律 2 バイトで表現するのが簡単で便利ですが、文字の大部分を 2 バイトで表現すると記憶容量が 2 倍になります。ネットワーク帯域幅には制限があります。この場合、ネットワーク送信のトラフィックが増加します。 UTF-8 は可変長テクノロジーを使用しており、各エンコード領域は異なる文字長を 1 ~ 6 バイトで構成できます。
UTF-8 には次のエンコード規則があります:
1 バイトの場合、最上位ビット (8 ビット目) は 0 で、ASCII 文字 (00 ~ 7F) であることを意味します
1 バイトの場合、11 から始まり、連続する 1 数字は、この文字のバイト数
それが10から始まる1バイトの場合、それは最初のバイトではないことを意味し、現在の文字の最初のバイトを取得するのを待つ必要があります
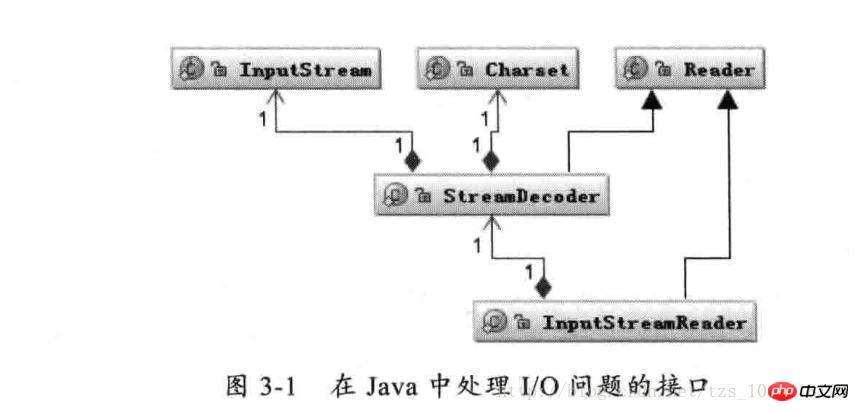
上に示すように、Reader クラスは Java I/O で文字を読み取るための親クラスであり、InputStream クラスはバイトを読み取るための親クラスであり、バイトを文字に関連付けるブリッジです。 I/O プロセス中に、読み取られたバイトの文字への変換を処理し、StreamDecoder のデコード プロセス中に、特定のバイトの文字へのデコードの実装を StreamDecoder に委託します。ユーザーは Charset エンコード形式を指定する必要があります。 Charset を指定しない場合、ローカル環境のデフォルトの文字セットが使用されることに注意してください。たとえば、中国語環境では GBK エンコーディングが使用されます。
たとえば、次のコードはファイルの読み取りおよび書き込み関数を実装します:
String file = "c:/stream.txt";
String charset = "UTF-8";
// 写字符换转成字节流
FileOutputStream outputStream = new FileOutputStream(file);
OutputStreamWriter writer = new OutputStreamWriter(
outputStream, charset);
try {
writer.write("这是要保存的中文字符");
} finally {
writer.close();
}
// 读取字节转换成字符
FileInputStream inputStream = new FileInputStream(file);
InputStreamReader reader = new InputStreamReader(
inputStream, charset);
StringBuffer buffer = new StringBuffer();
char[] buf = new char[64];
int count = 0;
try {
while ((count = reader.read(buf)) != -1) {
buffer.append(buffer, 0, count);
}
} finally {
reader.close();
}アプリケーションに I/O 操作が含まれる場合、統一されたエンコードおよびデコード Charset 文字セットの指定に注意を払っている限り、通常はコードの文字化けの問題は発生しません。
メモリ内で文字からバイトへのデータ型変換を実行します。
1. String クラスは、文字列をバイトに変換するためのメソッドを提供し、バイトを文字列に変換するためのコンストラクターもサポートします。
りー2. Charset は、char[] から byte[] へのエンコードと byte[] から char[] へのデコードにそれぞれ対応するエンコードとデコードを提供します。
りー...
Javaコーディングクラス図
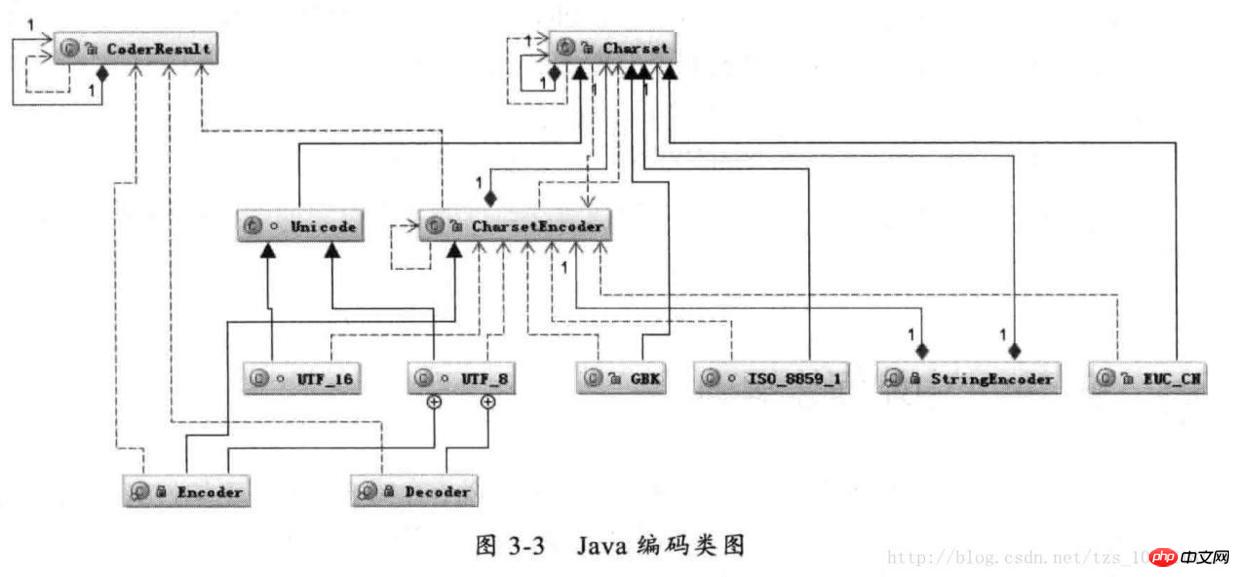
まず、Charset.forName(charsetName) によって指定された charsetName に従って Charset クラスを設定し、次に Charset に従って CharsetEncoder オブジェクトを作成し、次に CharsetEncoder.encode を呼び出して文字列をエンコードします。実際のエンコード タイプは 1 つのクラスに対応します。これらのクラスで処理が行われます。以下は、String.getBytes(charsetName) エンコードプロセスのタイミング図です
Javaコーディングシーケンス図
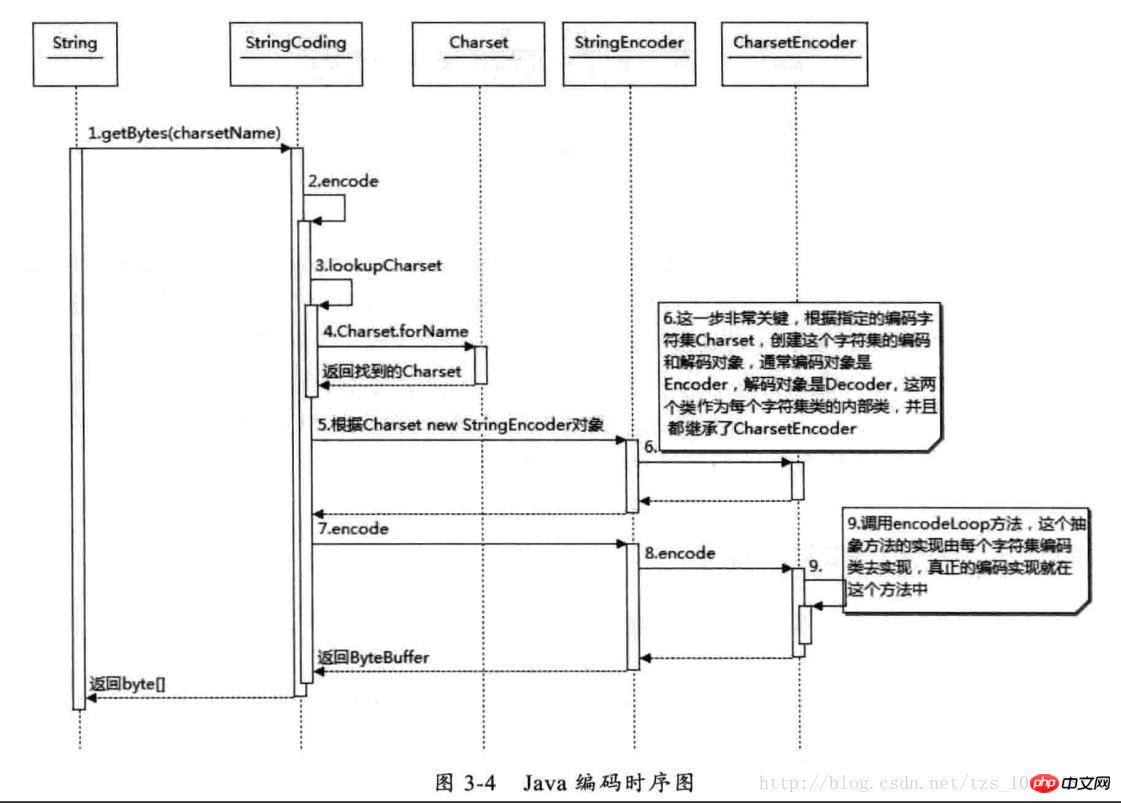
上の図からわかるように、Charset クラスは charsetName に基づいて検出され、その後 CharsetEncoder がこの文字セット エンコーディングに基づいて生成されます。このクラスは、さまざまな文字エンコーディング セットの方法を定義します。 CharsetEncoder オブジェクトを取得した後、encode メソッドを呼び出してエンコードを実装できます。これは String.getBytes エンコード メソッドであり、StreamEncoder などの他のメソッドも同様です。
中国語の文字が「?」になることがよくありますが、これはおそらく ISO-8859-1 エンコーディングの誤った使用が原因と考えられます。 ISO-8859-1 エンコード後、中国語の文字は情報を失います。これを私たちは通常「ブラック ホール」と呼び、未知の文字を吸収します。ほとんどの基本的な Java フレームワークまたはシステムのデフォルトの文字セット エンコーディングは ISO-8859-1 であるため、文字化けが発生しやすいため、さまざまな形式の文字化けがどのように発生するかを後で分析します。
GB2312 と GBK のエンコード規則は似ていますが、GBK の方が範囲が広く、すべての漢字を処理できるため、GB2312 と GBK を比較する場合は、GBK を選択する必要があります。 UTF-16 と UTF-8 は両方とも Unicode エンコードを扱いますが、エンコード規則は同じではありません。比較的言えば、UTF-16 エンコードが最も効率的で、文字をバイトに変換する方が簡単で、文字列の実行に適しています。オペレーション。ローカル ディスクとメモリの間での使用に適しており、たとえば、Java のメモリ エンコーディングは UTF-16 エンコーディングを使用します。ただし、ネットワーク転送ではバイト ストリームが破損しやすいため、ネットワーク間の転送には適していません。これに比べて、UTF-8 はネットワーク転送に適しており、単一のバイト ストリームを使用します。さらに、単一の文字が損傷しても、後続の文字には影響しません。したがって、UTF-8 は、エンコード効率とエンコードのセキュリティのバランスが取れており、理想的な中国語エンコードです。方法。
中国語の場合、I/O がある場合、エンコーディングが関係します。前述したように、I/O 操作によってエンコーディングが発生します。現在、ほとんどのアプリケーションで発生する I/O によって発生するコード化けのほとんどはネットワーク I/O です。ネットワーク操作が含まれており、ネットワーク上で送信されるデータはバイト単位であるため、すべてのデータをバイトにシリアル化する必要があります。 Java でシリアル化されるデータは、Serializable インターフェイスを継承する必要があります。
テキストの実際のサイズはどのように計算すればよいでしょうか? 私はかつて問題に遭遇しました。Cookie サイズを圧縮してネットワーク送信量を削減する方法を見つけたいと思ったとき、さまざまな圧縮アルゴリズムを選択したところ、次のことがわかりました。圧縮後に文字数は減りましたが、バイト数は減りませんでした。いわゆる圧縮は、エンコードを通じて複数のシングルバイト文字を 1 つのマルチバイト文字に変換するだけです。削減されるのは String.length() ですが、最終的なバイト数ではありません。たとえば、「ab」という 2 文字は、何らかのエンコードによって文字数が 2 文字から 1 文字に変化しますが、この文字が UTF-8 でエンコードされると、エンコード後に文字数が 3 文字になる場合があります。さらにバイト。同じ理由で、たとえば、整数 1234567 を文字として保存する場合、UTF-8 でエンコードすると 7 バイトが占有され、UTF-16 でエンコードすると 14 バイトが占有されますが、整数としてのみ保存されます。保存するには 4 バイトが必要です。したがって、テキストのサイズや文字自体の長さを見ることは意味がありません。同じ文字を異なるエンコーディングで保存したとしても、最終的に保存されるサイズは異なるため、エンコーディングの種類を確認する必要があります。文字からバイトへ。
我们能够看到的汉字都是以字符形式出现的,例如在 Java 中“淘宝”两个字符,它在计算机中的数值 10 进制是 28120 和 23453,16 进制是 6bd8 和 5d9d,也就是这两个字符是由这两个数字唯一表示的。Java 中一个 char 是 16 个 bit 相当于两个字节,所以两个汉字用 char 表示在内存中占用相当于四个字节的空间。
这两个问题搞清楚后,我们看一下 Java Web 中那些地方可能会存在编码转换?
用户从浏览器端发起一个 HTTP 请求,需要存在编码的地方是 URL、Cookie、Parameter。服务器端接受到 HTTP 请求后要解析 HTTP 协议,其中 URI、Cookie 和 POST 表单参数需要解码,服务器端可能还需要读取数据库中的数据,本地或网络中其它地方的文本文件,这些数据都可能存在编码问题,当 Servlet 处理完所有请求的数据后,需要将这些数据再编码通过 Socket 发送到用户请求的浏览器里,再经过浏览器解码成为文本。这些过程如下图所示:
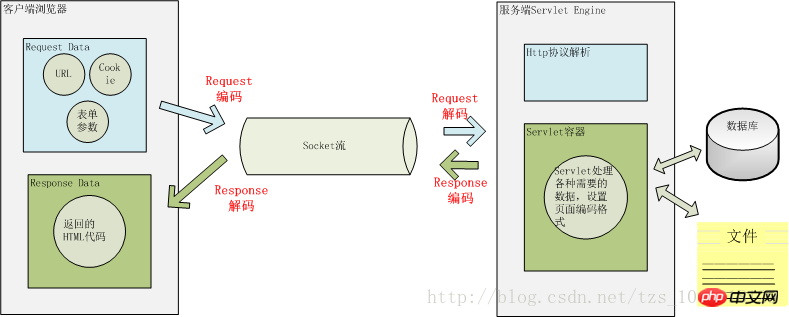
一次 HTTP 请求的编码示例
用户提交一个 URL,这个 URL 中可能存在中文,因此需要编码,如何对这个 URL 进行编码?根据什么规则来编码?有如何来解码?如下图一个 URL:

上图中以 Tomcat 作为 Servlet Engine 为例,它们分别对应到下面这些配置文件中:
Port 对应在 Tomcat 的
<servlet-mapping>
<servlet-name>junshanExample</servlet-name>
<url-pattern>/servlets/servlet/*</url-pattern>
</servlet-mapping>
上图中 PathInfo 和 QueryString 出现了中文,当我们在浏览器中直接输入这个 URL 时,在浏览器端和服务端会如何编码和解析这个 URL 呢?为了验证浏览器是怎么编码 URL 的我选择的是360极速浏览器并通过 Postman 插件观察我们请求的 URL 的实际的内容,以下是 URL:
HTTP://localhost:8080/examples/servlets/servlet/君山?author=君山
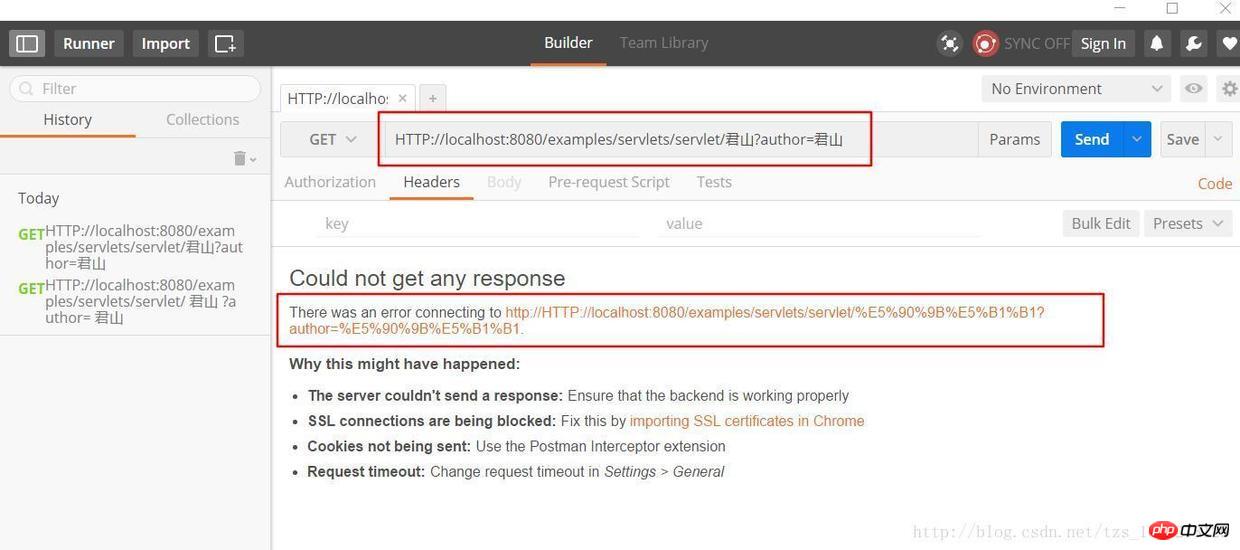
君山的编码结果是:e5 90 9b e5 b1 b1,和《深入分析 Java Web 技术内幕》中的结果不一样,这是因为我使用的浏览器和插件和原作者是有区别的,那么这些浏览器之间的默认编码是不一样的,原文中的结果是:

君山的编码结果分别是:e5 90 9b e5 b1 b1,be fd c9 bd,查阅上一届的编码可知,PathInfo 是 UTF-8 编码而 QueryString 是经过 GBK 编码,至于为什么会有“%”?查阅 URL 的编码规范 RFC3986 可知浏览器编码 URL 是将非 ASCII 字符按照某种编码格式编码成 16 进制数字然后将每个 16 进制表示的字节前加上“%”,所以最终的 URL 就成了上图的格式了。
从上面测试结果可知浏览器对 PathInfo 和 QueryString 的编码是不一样的,不同浏览器对 PathInfo 也可能不一样,这就对服务器的解码造成很大的困难,下面我们以 Tomcat 为例看一下,Tomcat 接受到这个 URL 是如何解码的。
解析请求的 URL 是在 org.apache.coyote.HTTP11.InternalInputBuffer 的 parseRequestLine 方法中,这个方法把传过来的 URL 的 byte[] 设置到 org.apache.coyote.Request 的相应的属性中。这里的 URL 仍然是 byte 格式,转成 char 是在 org.apache.catalina.connector.CoyoteAdapter 的 convertURI 方法中完成的:
protected void convertURI(MessageBytes uri, Request request)
throws Exception {
ByteChunk bc = uri.getByteChunk();
int length = bc.getLength();
CharChunk cc = uri.getCharChunk();
cc.allocate(length, -1);
String enc = connector.getURIEncoding();
if (enc != null) {
B2CConverter conv = request.getURIConverter();
try {
if (conv == null) {
conv = new B2CConverter(enc);
request.setURIConverter(conv);
}
} catch (IOException e) {...}
if (conv != null) {
try {
conv.convert(bc, cc, cc.getBuffer().length -
cc.getEnd());
uri.setChars(cc.getBuffer(), cc.getStart(),
cc.getLength());
return;
} catch (IOException e) {...}
}
}
// Default encoding: fast conversion
byte[] bbuf = bc.getBuffer();
char[] cbuf = cc.getBuffer();
int start = bc.getStart();
for (int i = 0; i < length; i++) {
cbuf[i] = (char) (bbuf[i + start] & 0xff);
}
uri.setChars(cbuf, 0, length);
}
从上面的代码中可以知道对 URL 的 URI 部分进行解码的字符集是在 connector 的
QueryStringを解析するにはどうすればよいですか? GET HTTP リクエストの QueryString と POST HTTP リクエストのフォームパラメータは Parameters として保存され、パラメータ値は request.getParameter を通じて取得されます。これらは、request.getParameter メソッドが初めて呼び出されたときにデコードされます。 request.getParameter メソッドが呼び出されると、org.apache.catalina.connector.Request の parseParameters メソッドが呼び出されます。このメソッドは GET および POST によって渡されたパラメータをデコードしますが、それらのデコード文字セットは異なる場合があります。 POST フォームのデコードについては後で紹介します。QueryString のデコード文字セットはどこで定義されていますか?これは HTTP ヘッダーを介してサーバーに送信され、URL にも含まれます。これは URI のデコード文字セットと同じですか?以前のブラウザでは PathInfo と QueryString に異なるエンコード形式が使用されていたことから、デコードされた文字セットは確実に一貫性がないことが推測できます。実際、QueryString のデコード文字セットは、ヘッダーの ContentType で定義された Charset またはデフォルトの ISO-8859-1 のいずれかです。ContentType で定義されたエンコーディングを使用するには、コネクタの
上記の URL のエンコードとデコードのプロセスから判断すると、これは比較的複雑であり、アプリケーションでエンコードとデコードを完全に制御できるわけではありません。そのため、アプリケーションの URL で非 ASCII 文字を使用することは避ける必要があります。もちろん、文字化けが発生する可能性があります。
クライアントが HTTP リクエストを開始するとき、上記の URL に加えて、Cookie や redirectPath などの他のパラメータもヘッダーで渡すことがあります。これらのユーザー設定値には、Tomcat がどのようにデコードするかというエンコードの問題も発生する可能性があります。 ?
ヘッダー内の項目のデコードは、request.getHeader を呼び出すことによっても実行されます。要求されたヘッダー項目がデコードされない場合は、MessageBytes の toString メソッドが呼び出され、バイトから文字への変換に使用されるデフォルトのエンコードも ISO-8859 です。 -1. であり、ヘッダーの他のデコード形式を設定することはできないため、ヘッダーに非 ASCII 文字のデコードを設定すると、確実に文字化けが発生します。
ヘッダーを追加する場合も同様です。ヘッダーに非 ASCII 文字を渡さないでください。渡す必要がある場合は、まず org.apache.catalina.util.URLEncoder でこれらの文字をエンコードしてからヘッダーに追加します。この方法では、ブラウザからサーバーへの転送中に情報が失われることはありません。これらの項目にアクセスするときに、対応する文字セットに従って情報をデコードできれば便利です。
前述したように、POST フォームによって送信されたパラメーターのデコードは、request.getParameter が初めて呼び出されたときに行われます。POST フォームのパラメーター転送メソッドは、HTTP の BODY を通じてサーバーに渡されます。ページ上の送信ボタンをクリックすると、ブラウザはまず ContentType の Charset エンコード形式に従ってフォームに入力されたパラメータをエンコードし、次にサーバーもデコードに ContentType の文字セットを使用します。したがって、POST フォームを通じて送信されたパラメータには通常問題はなく、文字セットのエンコーディングは独自に設定され、request.setCharacterEncoding(charset) を通じて設定できます。
さらに、multipart/form-data タイプのパラメーターの場合、つまり、アップロードされたファイルのエンコーディングも、ContentType で定義された文字セット エンコーディングを使用します。アップロードされたファイルは、バイト単位でサーバーのローカル一時ディレクトリに送信されることに注意してください。このプロセスには文字エンコーディングは含まれませんが、実際のエンコーディングでは、このエンコーディングを使用してエンコードできない場合は、デフォルトのエンコーディング ISO-8859-1 が使用されます。
ユーザーが要求したリソースが正常に取得されると、コンテンツは応答を通じてクライアント ブラウザーに返されます。このプロセスは、ブラウザーによって最初にエンコードされ、次にデコードされる必要があります。このプロセスのエンコードおよびデコード文字セットは、response.setCharacterEncoding を通じて設定できます。これは request.getCharacterEncoding の値をオーバーライドし、ブラウザが返されたソケット ストリームを受信すると、ヘッダーの Content-Type を通じてクライアントに返します。返された HTTP ヘッダーの Content-Type に文字セットが設定されていない場合、ブラウザは
除了 URL 和参数编码问题外,在服务端还有很多地方可能存在编码,如可能需要读取 xml、velocity 模版引擎、JSP 或者从数据库读取数据等。
xml 文件可以通过设置头来制定编码格式
<?xml version="1.0" encoding="UTF-8"?>
Velocity 模版设置编码格式:
services.VelocityService.input.encoding=UTF-8
JSP 设置编码格式:
<%@page contentType="text/html; charset=UTF-8"%>
访问数据库都是通过客户端 JDBC 驱动来完成,用 JDBC 来存取数据要和数据的内置编码保持一致,可以通过设置 JDBC URL 来制定如 MySQL:url="jdbc:mysql://localhost:3306/DB?useUnicode=true&characterEncoding=GBK"。
下面看一下,当我们碰到一些乱码时,应该怎么处理这些问题?出现乱码问题唯一的原因都是在 char 到 byte 或 byte 到 char 转换中编码和解码的字符集不一致导致的,由于往往一次操作涉及到多次编解码,所以出现乱码时很难查找到底是哪个环节出现了问题,下面就几种常见的现象进行分析。
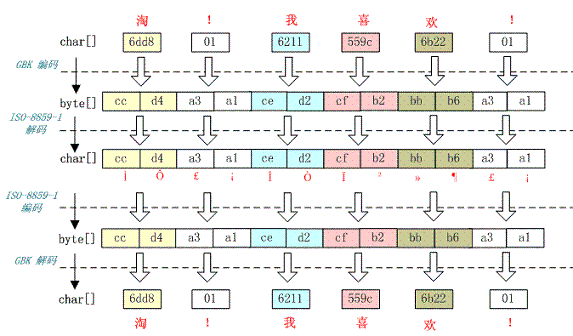
例如,字符串“淘!我喜欢!”变成了“Ì Ô £ ¡Î Ò Ï²»¶ £ ¡”编码过程如下图所示:
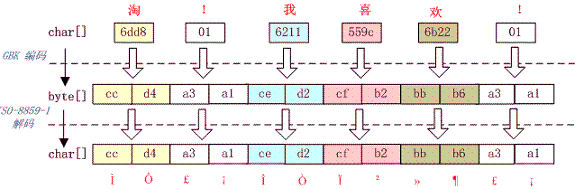
字符串在解码时所用的字符集与编码字符集不一致导致汉字变成了看不懂的乱码,而且是一个汉字字符变成两个乱码字符。
例如,字符串“淘!我喜欢!”变成了“??????”编码过程如下图所示:
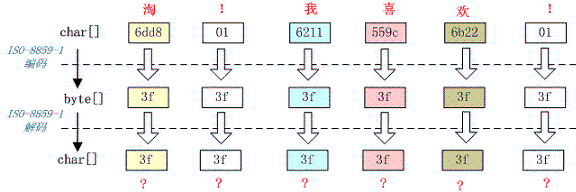
将中文和中文符号经过不支持中文的 ISO-8859-1 编码后,所有字符变成了“?”,这是因为用 ISO-8859-1 进行编解码时遇到不在码值范围内的字符时统一用 3f 表示,这也就是通常所说的“黑洞”,所有 ISO-8859-1 不认识的字符都变成了“?”。
例如,字符串“淘!我喜欢!”变成了“????????????”编码过程如下图所示:
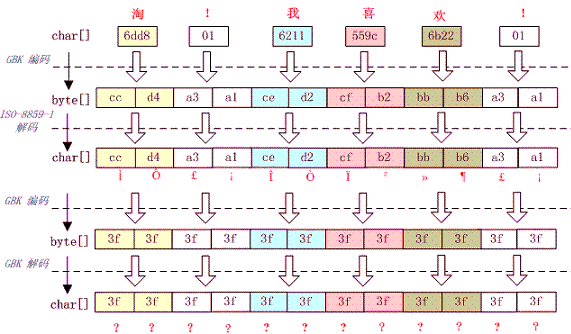
这种情况比较复杂,中文经过多次编码,但是其中有一次编码或者解码不对仍然会出现中文字符变成“?”现象,出现这种情况要仔细查看中间的编码环节,找出出现编码错误的地方。
还有一种情况是在我们通过 request.getParameter 获取参数值时,当我们直接调用
String value = request.getParameter(name); 会出现乱码,但是如果用下面的方式
String value = String(request.getParameter(name).getBytes(" ISO-8859-1"), "GBK");
解析时取得的 value 会是正确的汉字字符,这种情况是怎么造成的呢?
看下如所示:
这种情况是这样的,ISO-8859-1 字符集的编码范围是 0000-00FF,正好和一个字节的编码范围相对应。这种特性保证了使用 ISO-8859-1 进行编码和解码可以保持编码数值“不变”。虽然中文字符在经过网络传输时,被错误地“拆”成了两个欧洲字符,但由于输出时也是用 ISO-8859-1,结果被“拆”开的中文字的两半又被合并在一起,从而又刚好组成了一个正确的汉字。虽然最终能取得正确的汉字,但是还是不建议用这种不正常的方式取得参数值,因为这中间增加了一次额外的编码与解码,这种情况出现乱码时因为 Tomcat 的配置文件中 useBodyEncodingForURI 配置项没有设置为”true”,从而造成第一次解析式用 ISO-8859-1 来解析才造成乱码的。
この記事では、まず、いくつかの一般的なエンコード形式の違いを要約し、次に中国語をサポートするいくつかのエンコード形式を紹介し、それらの使用シナリオを比較します。次に、Java でコーディングの問題が関係する箇所と、Java でコーディングがどのようにサポートされるかを紹介します。ネットワーク I/O を例として、HTTP リクエスト内のエンコーディングが存在する場所と、Tomcat による HTTP プロトコルの分析に焦点を当て、最後に、私たちがよく遭遇するコード化けの問題の原因を分析します。
要約すると、中国語の問題を解決するには、まず、文字からバイトへのエンコードとバイトから文字へのデコードがどこで行われるか、最も一般的な場所はデータの読み取りとディスクへの保存、またはネットワークを通過するデータを把握する必要があります。 。 伝染 ; 感染。次に、これらの場所については、これらのデータを操作するフレームワークまたはシステムがエンコードをどのように制御するかを理解し、エンコード形式を正しく設定し、ソフトウェアまたはオペレーティング システム プラットフォームのデフォルトのエンコード形式の使用を避けます。
以上がJava Web における中国語エンコーディングの問題の分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



