

Python クローリング テクノロジーでの IP 自動プロキシの例

最近、試験のためにインターネットからソフト試験問題をクロールする予定ですが、クロール中にいくつかの問題が発生しました。次の記事では、主に Python を使用してソフト試験問題をクロールする方法と、IP 自動プロキシの関連情報を紹介します。この記事では、それについて詳しく紹介しています。以下を見てみましょう。
はじめに
最近、ソフトウェア プロフェッショナル レベルの試験があります。以下、ソフト試験と呼びます。試験の復習と準備をより良くするために、www.rkpass からソフト試験の問題を取得する予定です。 CN。
まず最初に、私がどのようにしてソフト試験問題をクロールしたかの物語(ケン)を話させてください。以下の図に示すように、特定のモジュール内のすべての問題を自動的にキャプチャできるようになりました。
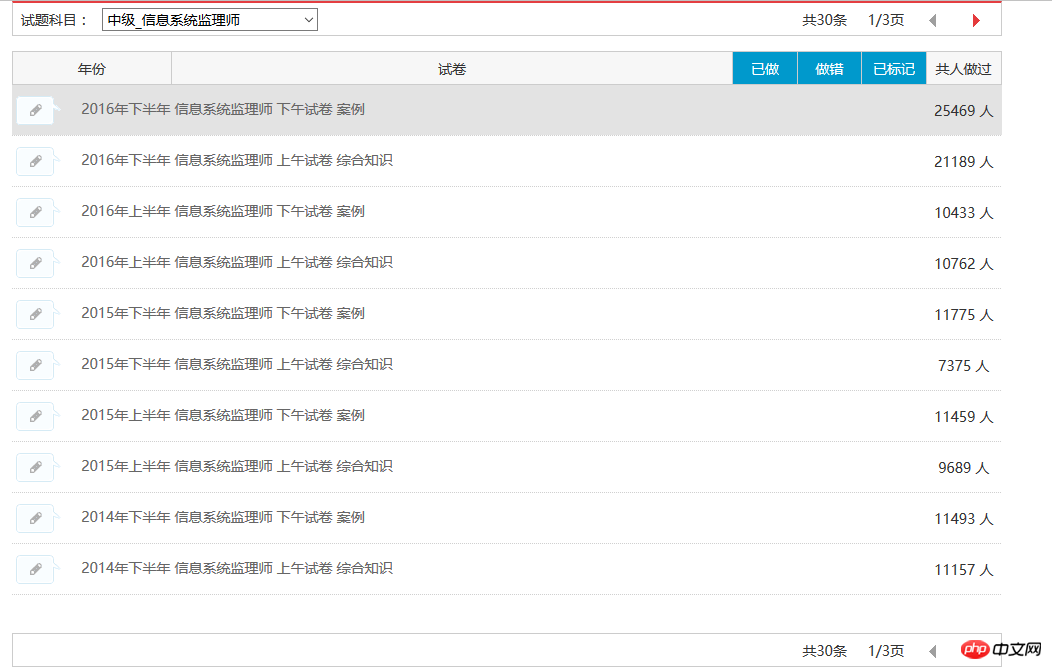
現在、情報システム監督者の試験問題レコード 30 件すべてをキャプチャでき、結果は図に示すとおりです。以下:
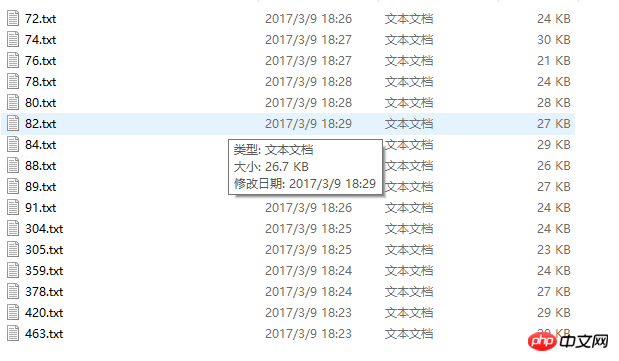
キャプチャされたコンテンツの写真:

一部の情報はキャプチャできますが、キャプチャされた情報システムのスーパーバイザーを例に挙げると、目標が明確であり、コードの品質は高くありません。パラメータは明確です。テスト用紙の情報を短時間で取得するために、昨夜はピットを埋めるのに長い時間を費やしませんでした。
本題に戻りますが、今日このブログを書いているのは、新たな落とし穴に遭遇したからです。記事のタイトルから、リクエストが多すぎたために、Web サイトのクローラー対策メカニズムによって IP がブロックされたのではないかと推測できます。
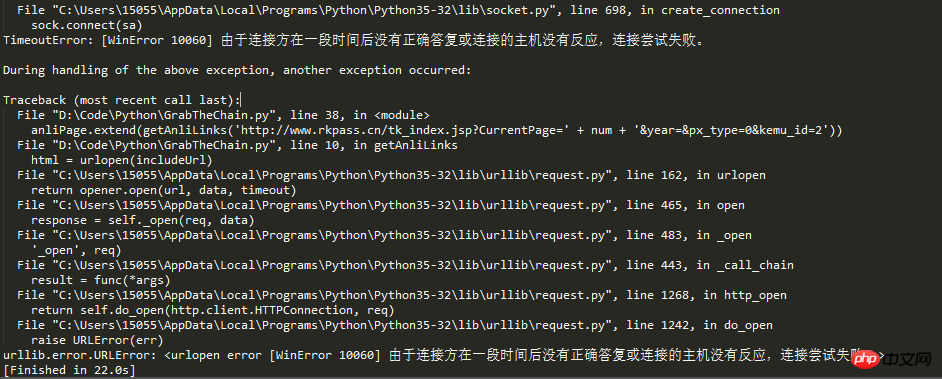
生きている人間が自分の尿を窒息させて死ぬことはできません。私たちの革命家の偉業は、社会主義の後継者として、解決するために困難に屈したり、山を越えて道路を開いたり、川を渡ったりすることができないことを教えてくれます。知財問題、知財庁というアイデアが出てきたばかりです。
ウェブクローラーによる情報の巡回過程において、巡回頻度がウェブサイトの設定した閾値を超えた場合、アクセスが禁止されます。通常、Web サイトのクローラー対策メカニズムは IP に基づいてクローラーを識別します。
したがって、クローラー開発者は通常、この問題を解決するために 2 つの方法を取る必要があります:
1. クロール速度を遅くし、ターゲット Web サイトへの負荷を軽減します。ただし、これにより単位時間あたりのクロール量が減少します。
2. 2 番目の方法は、プロキシ IP を設定するなどの手段で、クローラー対策メカニズムを突破し、高頻度のクロールを継続することです。ただし、これには複数の安定したプロキシ IP が必要です。
多くのことは言わないで、コードに直接進みましょう:
# IP地址取自国内髙匿代理IP网站:www.xicidaili.com/nn/
# 仅仅爬取首页IP地址就足够一般使用
from bs4 import BeautifulSoup
import requests
import random
#获取当前页面上的ip
def get_ip_list(url, headers):
web_data = requests.get(url, headers=headers)
soup = BeautifulSoup(web_data.text)
ips = soup.find_all('tr')
ip_list = []
for i in range(1, len(ips)):
ip_info = ips[i]
tds = ip_info.find_all('td')
ip_list.append(tds[1].text + ':' + tds[2].text)
return ip_list
#从抓取到的Ip中随机获取一个ip
def get_random_ip(ip_list):
proxy_list = []
for ip in ip_list:
proxy_list.append('http://' + ip)
proxy_ip = random.choice(proxy_list)
proxies = {'http': proxy_ip}
return proxies
#国内高匿代理IP网主地址
url = 'http://www.xicidaili.com/nn/'
#请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'}
#计数器,根据计数器来循环抓取所有页面的ip
num = 0
#创建一个数组,将捕捉到的ip存放到数组
ip_array = []
while num < 1537:
num += 1
ip_list = get_ip_list(url+str(num), headers=headers)
ip_array.append(ip_list)
for ip in ip_array:
print(ip)
#创建随机数,随机取到一个ip
# proxies = get_random_ip(ip_list)
# print(proxies)実行結果のスクリーンショット:
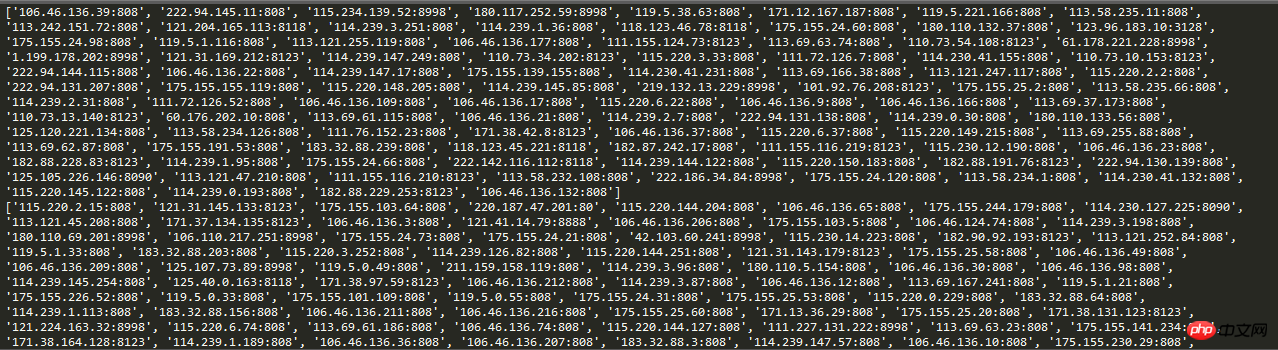
このようにして、クローラーがリクエストするときに、リクエスト IP を自動 IP に設定します。これにより、単純な問題を効果的に回避できます。アンチクローラ機構 IP をブロックして固定する方法が使用されます。
------------------------------------------------ -------------------------------------------------- ----------------------------------
ウェブサイトの安定性を確保するために、誰もがウェブサイトの速度を制御する必要があります。結局のところ、ウェブマスターにとっても簡単ではありません。この記事のテストでは、17 ページの IP のみがキャプチャされました。
概要
以上がPython クローリング テクノロジーでの IP 自動プロキシの例の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7517
7517
 15
1378
52
79
11
21
66
15
1378
52
79
11
21
66

 Debian Apacheログを使用してWebサイトのパフォーマンスを向上させる方法
Apr 12, 2025 pm 11:36 PM
Debian Apacheログを使用してWebサイトのパフォーマンスを向上させる方法
Apr 12, 2025 pm 11:36 PM
この記事では、Debianシステムの下でApacheログを分析することにより、Webサイトのパフォーマンスを改善する方法について説明します。 1.ログ分析の基本Apacheログは、IPアドレス、タイムスタンプ、リクエストURL、HTTPメソッド、応答コードなど、すべてのHTTP要求の詳細情報を記録します。 Debian Systemsでは、これらのログは通常、/var/log/apache2/access.logおよび/var/log/apache2/error.logディレクトリにあります。ログ構造を理解することは、効果的な分析の最初のステップです。 2。ログ分析ツールさまざまなツールを使用してApacheログを分析できます。コマンドラインツール:GREP、AWK、SED、およびその他のコマンドラインツール。
 Python:ゲーム、GUIなど
Apr 13, 2025 am 12:14 AM
Python:ゲーム、GUIなど
Apr 13, 2025 am 12:14 AM
PythonはゲームとGUI開発に優れています。 1)ゲーム開発は、2Dゲームの作成に適した図面、オーディオ、その他の機能を提供し、Pygameを使用します。 2)GUI開発は、TKINTERまたはPYQTを選択できます。 TKINTERはシンプルで使いやすく、PYQTは豊富な機能を備えており、専門能力開発に適しています。
 PHPとPython:2つの一般的なプログラミング言語を比較します
Apr 14, 2025 am 12:13 AM
PHPとPython:2つの一般的なプログラミング言語を比較します
Apr 14, 2025 am 12:13 AM
PHPとPythonにはそれぞれ独自の利点があり、プロジェクトの要件に従って選択します。 1.PHPは、特にWebサイトの迅速な開発とメンテナンスに適しています。 2。Pythonは、データサイエンス、機械学習、人工知能に適しており、簡潔な構文を備えており、初心者に適しています。
 DDOS攻撃検出におけるDebianスニファーの役割
Apr 12, 2025 pm 10:42 PM
DDOS攻撃検出におけるDebianスニファーの役割
Apr 12, 2025 pm 10:42 PM
この記事では、DDOS攻撃検出方法について説明します。 「DebiansNiffer」の直接的なアプリケーションのケースは見つかりませんでしたが、次の方法はDDOS攻撃検出に使用できます:効果的なDDOS攻撃検出技術:トラフィック分析に基づく検出:突然のトラフィックの成長、特定のポートの接続の急増などのネットワークトラフィックの異常なパターンの識別。たとえば、PysharkライブラリとColoramaライブラリと組み合わせたPythonスクリプトは、ネットワークトラフィックをリアルタイムで監視し、アラートを発行できます。統計分析に基づく検出:データなどのネットワークトラフィックの統計的特性を分析することにより
 Nginx SSL証明書更新Debianチュートリアル
Apr 13, 2025 am 07:21 AM
Nginx SSL証明書更新Debianチュートリアル
Apr 13, 2025 am 07:21 AM
この記事では、DebianシステムでNGINXSSL証明書を更新する方法について説明します。ステップ1:最初にCERTBOTをインストールして、システムがCERTBOTおよびPython3-Certbot-Nginxパッケージがインストールされていることを確認してください。インストールされていない場合は、次のコマンドを実行してください。sudoapt-getupdatesudoapt-getinstolcallcertbotthon3-certbot-nginxステップ2:certbotコマンドを取得して構成してlet'sencrypt証明書を取得し、let'sencryptコマンドを取得し、nginx:sudocertbot - nginxを構成します。
 Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
DebianシステムのReadDir関数は、ディレクトリコンテンツの読み取りに使用されるシステムコールであり、Cプログラミングでよく使用されます。この記事では、ReadDirを他のツールと統合して機能を強化する方法について説明します。方法1:C言語プログラムを最初にパイプラインと組み合わせて、cプログラムを作成してreaddir関数を呼び出して結果をinclude#include#include inctargc、char*argv []){dir*dir; structdireant*entry; if(argc!= 2){(argc!= 2){
 Pythonと時間:勉強時間を最大限に活用する
Apr 14, 2025 am 12:02 AM
Pythonと時間:勉強時間を最大限に活用する
Apr 14, 2025 am 12:02 AM
限られた時間でPythonの学習効率を最大化するには、PythonのDateTime、時間、およびスケジュールモジュールを使用できます。 1. DateTimeモジュールは、学習時間を記録および計画するために使用されます。 2。時間モジュールは、勉強と休息の時間を設定するのに役立ちます。 3.スケジュールモジュールは、毎週の学習タスクを自動的に配置します。
 debian opensslでHTTPSサーバーを構成する方法
Apr 13, 2025 am 11:03 AM
debian opensslでHTTPSサーバーを構成する方法
Apr 13, 2025 am 11:03 AM
DebianシステムでHTTPSサーバーの構成には、必要なソフトウェアのインストール、SSL証明書の生成、SSL証明書を使用するWebサーバー(ApacheやNginxなど)の構成など、いくつかのステップが含まれます。 Apachewebサーバーを使用していると仮定して、基本的なガイドです。 1.最初に必要なソフトウェアをインストールし、システムが最新であることを確認し、ApacheとOpenSSL:sudoaptupdatesudoaptupgraysudoaptinstaをインストールしてください
