

この記事では主にPythonでNaive Bayesアルゴリズムを使用する方法に関する関連知識を紹介します。非常に良い基準値を持っています。エディターで見てみましょう
ここで、タイトルが「実装」ではなく「使用」である理由を繰り返します:
まず第一に、専門家によって提供されるアルゴリズムは、私たちが作成するアルゴリズムよりも効率的で正確です。私たちもハイになりましょう。
第二に、数学が苦手な人にとって、アルゴリズムを実装するために大量の公式を勉強するのは非常に苦痛です。
繰り返しになりますが、他人が提供するアルゴリズムがあなたのニーズを満たせない場合を除き、「車輪の再発明」をする必要はありません。
本題に入りましょう。ベイジアン アルゴリズムを知らない場合は、関連情報を確認してください。
1. ベイジアンの公式:
P(A| B)=P(AB)/P(B)P(A|B)=P(AB)/P(B)
2.贝叶斯推断:
P(A|B)=P(A)×P(B|A)/P(B)
2. ベイズ推論:
P(A|B)=P(A)×P(B|A)/P (B) 言葉で説明すると:
ベイジアン アルゴリズムが解決する必要がある問題は、類似度を見つける方法、つまり次のとおりです。 P (B|A) の値
3. 一般的に使用される 3 つの単純ベイズ アルゴリズムが scikit-learn パッケージで提供されており、以下で順番に説明します:
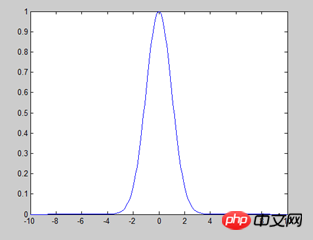 1) ガウス単純ベイズ: 仮定属性/特徴は正規分布に従い (以下に示すように)、主に数値特徴に使用されます。
1) ガウス単純ベイズ: 仮定属性/特徴は正規分布に従い (以下に示すように)、主に数値特徴に使用されます。
>>>from sklearn import datasets ##导入包中的数据 >>> iris=datasets.load_iris() ##加载数据 >>> iris.feature_names ##显示特征名字 ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'] >>> iris.data ##显示数据 array([[ 5.1, 3.5, 1.4, 0.2],[ 4.9, 3. , 1.4, 0.2],[ 4.7, 3.2, 1.3, 0.2]............ >>> iris.data.size ##数据大小 ---600个 >>> iris.target_names ##显示分类的名字 array(['setosa', 'versicolor', 'virginica'], dtype='<U10') >>> from sklearn.naive_bayes import GaussianNB ##导入高斯朴素贝叶斯算法 >>> clf = GaussianNB() ##给算法赋一个变量,主要是为了方便使用 >>> clf.fit(iris.data, iris.target) ##开始分类。对于量特别大的样本,可以使用函数partial_fit分类,避免一次加载过多数据到内存 >>> clf.predict(iris.data[0].reshape(1,-1)) ##验证分类。标红部分特别说明:因为predict的参数是数组,data[0]是列表,所以需要转换一下 array([0]) >>> data=np.array([6,4,6,2]) ##验证分类 >>> clf.predict(data.reshape(1,-1)) array([2])
##示例来在官方文档,详细说明见第一个例子
>>> import numpy as np
>>> X = np.random.randint(5, size=(6, 100)) ##返回随机整数值:范围[0,5) 大小6*100 6行100列
>>> y = np.array([1, 2, 3, 4, 5, 6])
>>> from sklearn.naive_bayes import MultinomialNB
>>> clf = MultinomialNB()
>>> clf.fit(X, y)
MultinomialNB(alpha=1.0, class_prior=None, fit_prior=True)
>>> print(clf.predict(X[2]))
[3]
##示例来在官方文档,详细说明见第一个例子 >>> import numpy as np >>> X = np.random.randint(2, size=(6, 100)) >>> Y = np.array([1, 2, 3, 4, 4, 5]) >>> from sklearn.naive_bayes import BernoulliNB >>> clf = BernoulliNB() >>> clf.fit(X, Y) BernoulliNB(alpha=1.0, binarize=0.0, class_prior=None, fit_prior=True) >>> print(clf.predict(X[2])) [3]
以上がPython で Naive Bayes アルゴリズムを使用する方法の詳細な紹介の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



