

この記事では、主に Java String クラスの詳細な説明を紹介します。この記事は、多くのソースから収集、整理、要約され、最終的に書かれたものです。必要な方は参考にしてください。
導入の質問
Java 言語の 1. Java メモリとは具体的にどのメモリを指しますか?なぜこのメモリ領域を分割する必要があるのでしょうか?どのように分けられているのでしょうか?分割後の各エリアの役割は何ですか?各領域のサイズを設定するにはどうすればよいですか? 2. 接続操作を実行するときに、String 型が StringBuffer や StringBuilder よりも効率が悪いのはなぜですか? StringBuffer と StringBuilder の関係と違いは何ですか? 3. Java では定数は何を意味しますか? String s = "s" と String s = new String("s") の違いは何ですか? この記事はさまざまなソースから編集および要約され、最終的に書かれたものです。間違いがある場合は、お知らせください。Java メモリ割り当て
Java 仮想マシン (Java 仮想マシン、JVM と呼ばれる) は、すべての Java プログラムを実行する抽象的なコンピューターです。 Java 言語の最も魅力的な機能の 1 つです。 Java 仮想マシンには、プロセッサ、スタック、レジスタなどの独自の完全なハードウェア アーキテクチャがあり、対応する命令システムもあります。 JVM は特定のオペレーティング システム プラットフォームに関連する情報をシールドするため、Java プログラムは Java 仮想マシン上で実行されるターゲット コード (バイトコード) を生成するだけでよく、変更することなくさまざまなプラットフォーム上で実行できます。 ランタイム Java 仮想マシン インスタンスの制限された義務は、Java プログラムを実行することです。 Java プログラムが開始されると、仮想マシン インスタンスが生成されます。プログラムが閉じて
終了
ガベージ コレクション: ヒープ メモリ (ヒープ) で使用されていないオブジェクトのリサイクルを担当します。つまり、これらのオブジェクトはもう参照されなくなりました。
クラスローダー サブシステム: バイナリ クラス ファイルの検索とインポートに加えて、インポートされたクラスの正確性の検証、クラス変数のメモリの割り当てと初期化、シンボル参照の解決の支援も行う必要があります。 Executive Engine: ロードされたクラスに含まれる命令の実行を担当します。
ランタイムデータ領域 (Java メモリ割り当て領域): 仮想マシンメモリまたは Java メモリとも呼ばれ、仮想マシンの実行時に、コンピュータのメモリ全体から多くのものを保存するためのメモリ領域。例: バイトコード、ロードされたクラス ファイルから取得されるその他の情報、プログラムによって作成されたオブジェクト、メソッドに渡されるパラメーター、戻り値、ローカル変数など。
2. Java メモリのパーティション
前のセクションからわかるように、実行時のデータ領域は Java メモリであり、このメモリ領域が分割されていない場合、データ領域には多くのものを格納する必要があります。管理されていると、むしろ混乱しているように見えます。プログラムは秩序あるものを好み、無秩序なものを嫌います。 さまざまな格納データに従って、Java メモリは通常、プログラム カウント レジスタ、ネイティブ スタック、メソッド領域、スタック、およびヒープの 5 つの領域に分割されます。 プログラムカウンター (プログラムカウントレジスタ): プログラムレジスタとも呼ばれます。 JVM は、同時に実行される複数のスレッドをサポートします。新しいスレッドが作成されるたびに、独自の PC レジスタ (プログラム カウンター) が取得されます。スレッドが Java メソッド (非ネイティブ) を実行している場合、PC レジスタの値は常に次に実行される命令を指します。メソッドがネイティブの場合、プログラム カウンタ レジスタの値は定義されません。 JVM のプログラム カウンタ レジスタは、リターン アドレスまたはネイティブ ポインタを保持するのに十分な幅を持っています。 スタック: スタックとも呼ばれます。 JVM は、新しく作成されたスレッドごとにスタックを割り当てます。つまり、Java プログラムの場合、その動作はスタックの動作によって完了します。スタックはスレッドの状態をフレーム単位で保存します。 JVM はスタック上で 2 つの操作 (フレーム単位でのプッシュ操作とポップ操作) のみを実行します。スレッドによって実行されているメソッドは、このスレッドの現在のメソッドと呼ばれることがわかります。現在のメソッドで使用されているフレームが現在のフレームと呼ばれていることを知らないかもしれません。スレッドが Java メソッドをアクティブ化すると、JVM は新しいフレームをスレッドの Java スタックにプッシュし、このフレームが自然に現在のフレームになります。このメソッドの実行中、このフレームはパラメータ、ローカル変数、中間計算、その他のデータを保存するために使用されます。 Java の割り当てメカニズムの観点から、スタックは次のように理解できます。スタックは、オペレーティング システムがプロセスまたはスレッド (マルチスレッドをサポートするオペレーティング システムのスレッド) を作成するときに、このスレッド用に作成される記憶領域です。この領域には先入れ後出しの特性があります。関連する設定パラメーター:-• XSS - 設定メソッド スタックの最大値 ネイティブ スタック • -Xms - ヒープ メモリの初期サイズを設定します • -Xmx - 最大ヒープ メモリ サイズを設定します • -XX:PretenureSizeThreshold -- 指定されたサイズを超える大きなオブジェクトが古い世代に直接割り当てられるように設定します Java ヒープは、ガベージ コレクターによって管理される主要な領域であるため、「GC ヒープ」(Garbage Collectioned Heap) とも呼ばれます。現在のガベージ コレクターは基本的に世代別コレクション アルゴリズムを使用するため、Java ヒープは次の図に示すように、若い世代と古い世代に再分割できます。世代別コレクション アルゴリズムの考え方: 最初の方法は、若いオブジェクト (若い世代) をより高い頻度でスキャンしてリサイクルすることです。これはマイナー コレクションと呼ばれますが、古いオブジェクト (古い世代) のチェックとリサイクルの頻度は低くなります。メジャーコレクションと呼ばれるたくさんの。この方法では、GC を使用するたびにメモリ内のすべてのオブジェクトをチェックする必要がなく、アプリケーション システムがより多くのシステム リソースを利用できるようになります。別の言い方をすれば、オブジェクトを割り当てたときに不足が発生したときです。メモリの場合、最初に新しい世代に対して GC が実行されます (ヤング GC)。新しい世代の GC がまだメモリ領域の割り当て要件を満たさない場合、ヒープ領域とメソッド領域全体に対して GC (フル GC) が実行されます。 読者の中にはここで質問があるかもしれません: 永続世代 (Permanent Generation) があることを思い出してください。それは Java ヒープに属しているのではありませんか?親愛なる、あなたは正しく理解しました!実際、伝説的な永続生成は、JVM の初期化時にローダーによってロードされるいくつかの型情報 (クラス情報、定数、静的変数など) を格納する上記のメソッド領域です。この情報のライフサイクルは比較的短いです。 PermGen Space はメイン プログラムの実行中にクリーンアップされるため、アプリケーション内に多くの CLASS がある場合、PermGen Space エラーが発生する可能性があります。関連する設定パラメータ:-• XX: Permsize - Perm 領域の初期サイズを設定します。 • -XX: Maxpermsize - Perm 領域の最大値を設定します。 領域と Survivor 領域は「From Space」と「To Space」に分かれています。 Eden 領域はデフォルトでオブジェクトが最初に割り当てられる場所であり、From Space と To Space の領域は同じサイズです。 JVM はマイナー GC を実行すると、Eden 内の存続するオブジェクトを Survivor 領域にコピーし、Survivor 領域内の存続するオブジェクトを Tenured 領域にコピーします。この GC モードでは、GC 効率を向上させるために、JVM は Survivor を From Space と To Space に分割し、オブジェクトのリサイクルとオブジェクトのプロモーションを分離できます。新しい世代のサイズを設定するには、次の 2 つの関連パラメーターがあります: • -Xmn -- 新しい世代のメモリ サイズを設定します。 •-xx:survivorratio-エデンと生存空間の間のサイズ比を設定する 古い世代生存者と古いエリアはまだエデンからコピーされたオブジェクトを保存することができず、JVMが新しいオブジェクトのメモリ領域を作成できませんエデンエリアにあると「メモリ不足エラー」が発生します。 3. String 型の詳細な分析 Java データ型から始めましょう! Java データ型は一般に、基本型と参照型の 2 つのカテゴリに分類されます。基本型の変数はプリミティブ値を保持し、参照型の変数は通常、実際のオブジェクトへの参照を表します。オブジェクト。 Stringのソースコードを開くと、クラスにこんな段落があります 「文字列は定数であり、その値は作成後に変更することはできません。文字列バッファ可変文字列をサポートします。String オブジェクトは不変であるため、共有できます。」この文は、String の最も重要な特徴の 1 つを要約しています。つまり、String は値が不変 (不変) であり、スレッドセーフ (共有可能) である定数です。 次に、String クラスは、最後の修飾子を使用します。これは、String クラスの 2 番目の特徴、つまり String クラスは ではないことを示しています。 以下は String クラスのメンバー変数定義であり、String 値がクラスの実装から不変であることを明確にしています。 そこで、Stringクラスのconcatメソッドを見ていきます。このメソッドを実装する最初のステップは、メンバー変数値の容量を拡張することです。この拡張メソッドは、大容量の文字配列 buf を再定義します。 2 番目のステップでは、元の値の文字を buf にコピーし、次に連結する必要がある文字列値を buf にコピーします。このようにして、buf には連結後の文字列値が含まれます。ここが問題の鍵です。値が最終値でない場合は、その値を buf に直接指定してこれを返します。新しい String オブジェクトを返す必要はありません。しかし。 。 。残念。 。 。 valueはfinalなので、新しく定義した大容量配列bufを指すことはできません。 「return new String(0, count + otherLen, buf);」、これは String クラス concat 実装メソッドの最後のステートメントであり、新しい String オブジェクトを返します。今、真実が明らかになります! 概要: String は本質的に 2 つの特性を持つ文字配列です。1. このクラスは継承できません。2. 不変です。 2. String の定義方法 String の定義方法を説明する前に、メソッド領域の紹介で触れた定数プールの概念を理解してください。少し正式な定義をしてみましょう。 定数プールは、コンパイル中に決定され、コンパイルされた .class ファイルに保存される一部のデータを指します。これには、文字列定数だけでなく、クラス、メソッド、インターフェイスなどの定数も含まれます。定数プールも動的であり、実行時に新しい定数をプールに入れることができます。String クラスの intern() メソッドは、この機能の典型的なアプリケーションです。分かりませんか?インターン方式については後ほど紹介します。仮想マシンは、ロードされた型ごとに定数プールを維持します。プールは、直接定数 (文字列、整数、浮動小数点定数) や他の型、フィールド、メソッドへのシンボリック参照を含む、その型で使用される定数の順序付けられたコレクションです (Whatそれとオブジェクト参照の違いは読者が自分で見つけることができます)。 myString";•次のように連続して生成されます。 String s1 = "my" + "String"; このメソッドはより複雑なので、ここでは詳しく説明しません。 1 つ目の方法は、キーワード new を使用してプロセスを定義することです。プログラムのコンパイル中に、コンパイラーはまず文字列定数プールをチェックして、「myString」が存在するかどうかを確認します。存在しない場合は、定数プール内にメモリ空間が開かれます。 "myString". "; が存在する場合、スペースを再度開く必要はなく、定数プール内に "myString" 定数が 1 つだけ存在することが保証され、メモリ スペースが節約されます。次に、メモリ ヒープ内のスペースを開き、新しい String インスタンスを格納します。スタック内にスペースを作成し、「s1」という名前を付けます。このプロセスは、ヒープ内の String インスタンスのメモリ アドレスを指定します。 s1 を新しいインスタンスに参照します。 2 番目の方法は、プロセスを直接定義する方法です。プログラムのコンパイル中に、コンパイラーはまず文字列定数プールに移動して、「myString」が存在するかどうかを確認します。存在しない場合は、定数プール内にメモリ空間が開かれます。 store "myString"; 存在する場合、スペースを再度開く必要はありません。次に、スタック内のスペースを開き、「s1」という名前を付け、その値を定数プールの「myString」のメモリ アドレスとして保存します。 たくさんの質問があるので、ヒープ内の String オブジェクトと定数プール内の String 定数の関係について説明します。私もこのトピックについては比較的漠然としているので、これは単なる議論であることを覚えておいてください。 第一种猜想:因为直接定义的字符串也可以调用String对象的各种方法,那么可以认为其实在常量池中创建的也是一个String实例(对象)。 这种猜想认为:常量池中的字符串常量实质上是一个String实例,与堆中的String实例是克隆关系。 第二种猜想也是目前网上阐述的最多的,但是思路都不清晰,有些问题解释不通。下面引用《JAVA String对象和字符串常量的关系解析》一段内容。 在解析阶段,虚拟机发现字符串常量"myString",它会在一个内部字符串常量列表中查找,如果没有找到,那么会在堆里面创建一个包含字符序列[myString]的String对象s1,然后把这个字符序列和对应的String对象作为名值对( [myString], s1 )保存到内部字符串常量列表中。如下图所示: 如果虚拟机后面又发现了一个相同的字符串常量myString,它会在这个内部字符串常量列表内找到相同的字符序列,然后返回对应的String对象的引用。维护这个内部列表的关键是任何特定的字符序列在这个列表上只出现一次。 这个猜想有一个比较明显的问题,红色字体标示的地方就是问题的所在。证明方式很简单,下面这段代码的执行结果,javaer都应该知道。 虽然这段内容不那么有说服力,但是文章提到了一个东西——字符串常量列表,它可能是解释这个问题的关键。 文中提到的三个问题,本文仅仅给出了猜想,具体请自己考证! • 堆中new出来的实例和常量池中的“myString”是什么关系呢? • 常量池中的字符串常量与堆中的String对象有什么区别呢? • 为什么直接定义的字符串同样可以调用String对象的各种方法呢? 3、String、StringBuffer、StringBuilder的联系与区别 上面已经分析了String的本质了,下面简单说说StringBuffer和StringBuilder。 StringBuffer和StringBuilder都继承了抽象类AbstractStringBuilder,这个抽象类和String一样也定义了char[] value和int count,但是与String类不同的是,它们没有final修饰符。因此得出结论:String、StringBuffer和StringBuilder在本质上都是字符数组,不同的是,在进行连接操作时,String每次返回一个新的String实例,而StringBuffer和StringBuilder的append方法直接返回this,所以这就是为什么在进行大量字符串连接运算时,不推荐使用String,而推荐StringBuffer和StringBuilder。那么,哪种情况使用StringBuffe?哪种情况使用StringBuilder呢? 关于StringBuffer和StringBuilder的区别,翻开它们的源码,下面贴出append()方法的实现。 上の 1 枚目の画像は StringBuffer での append() メソッドの実装、2 枚目の画像は StringBuilder での append() メソッドの実装です。違いは一目瞭然です。StringBuffer はメソッドの前に同期された変更を追加します。これは同期の役割を果たし、マルチスレッド環境で使用できます。その代償として実行効率が低下します。したがって、マルチスレッド環境で文字列接続操作に StringBuffer を使用できる場合は、シングルスレッド環境で StringBuilder を使用する方が効率的です。  メソッド領域
メソッド領域
• -XX:MaxTenuringThreshold - 新しい環境でオブジェクトが存続する回数を設定します世代 

private final char value[];
private final int count;
String s1 = new String("myString");先在编译期的时候在常量池创建了一个String实例,然后clone了一个String实例存储在堆中,引用s1指向堆中的这个实例。此时,池中的实例没有被引用。当接着执行String s1 = "myString";时,因为池中已经存在“myString”的实例对象,则s1直接指向池中的实例对象;否则,在池中先创建一个实例对象,s1再指向它。如下图所示: 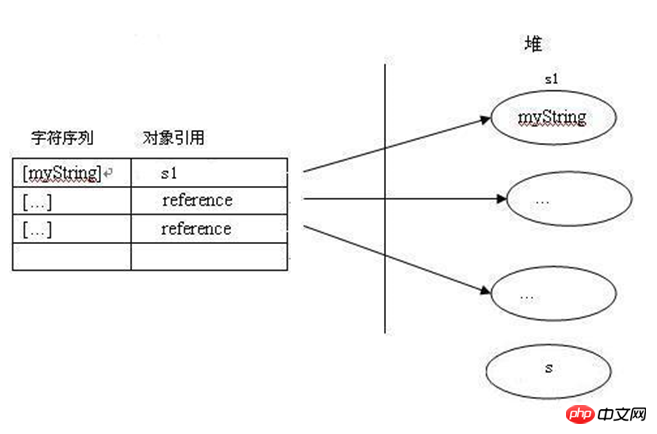
例如,String s2 = "myString",运行时s2会从内部字符串常量列表内得到s1的返回值,所以s2和s1都指向同一个String对象。String s1 = new String("myString");
String s2 = "myString";
System.out.println(s1 == s2); //按照上面的推测逻辑,那么打印的结果为true;而实际上真实的结果是false,因为s1指向的是堆中String对象,而s2指向的是常量池中的String常量。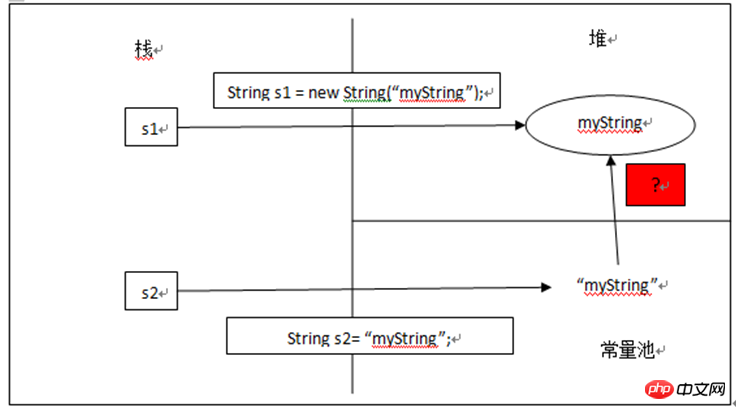

以上がJavaのStringクラスの詳しい説明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



